SeqGAN: Sequence GenerativeAdversarial Nets with Policy Gradient
1 | 论文地址:https://arxiv.org/abs/1609.05473 |
当目标是离散序列数据时,生成模型的离散输出使得从判别模型到生成模型的梯度更新很难传递,此外,判别模型只能评估一个完整的序列。对于一个部分生成的序列,平衡当前的分数和未来的分数时非常重要的。
两个问题
- Generator难以传递梯度更新
- Discriminator难以评估非完整序列。
两种解决方法
- Policy Gradien
- MCTS
What is policy?
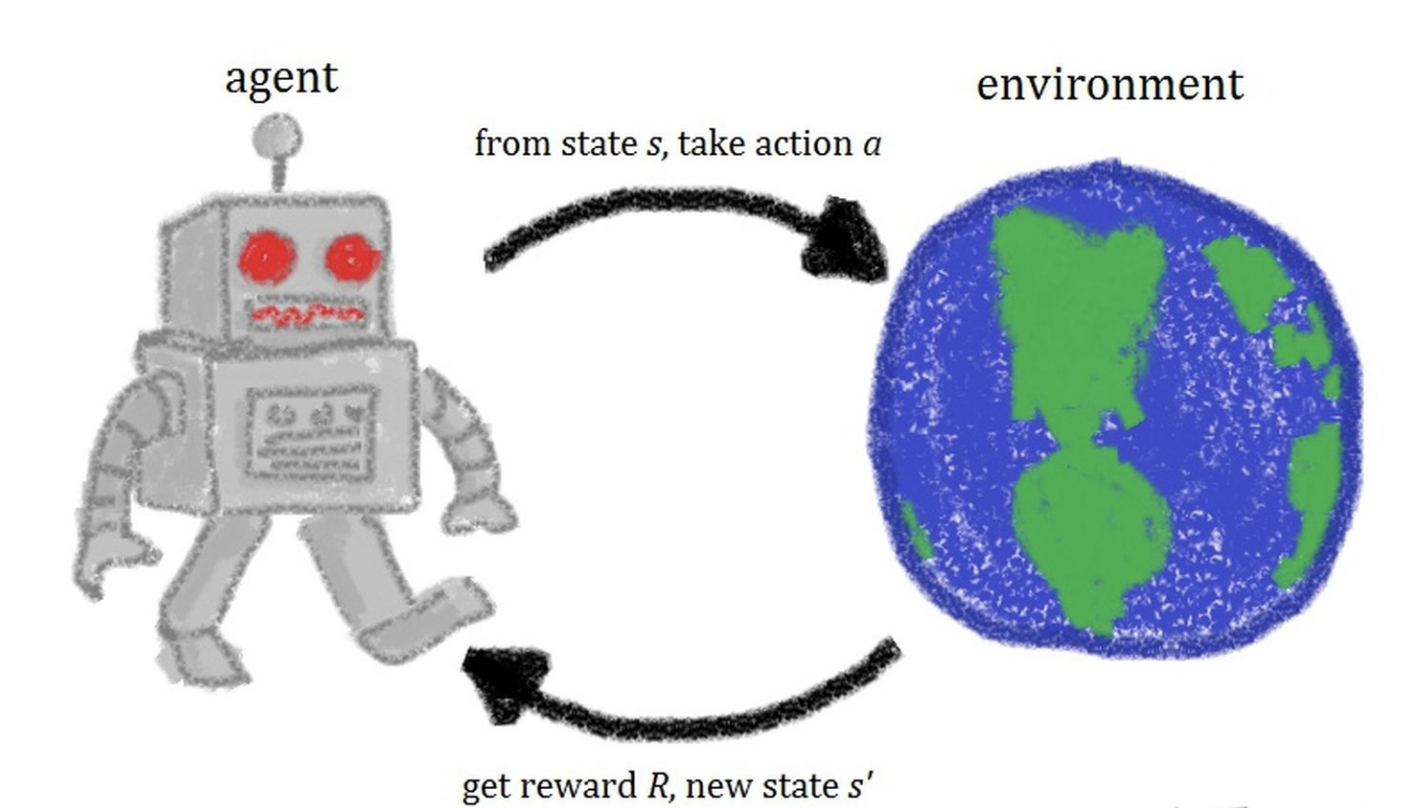
一个由agent和environment组成的结构。
Agent通过观察当前环境的状态 $s_t$ ,得出当前应当执行的动作 $a_t$。Agent执行完动作之后环境对应发生了改变,并且环境会给予Agent一个反馈reward $r_t$。此时又会是一个新的环境状态 $s’$,基于本次的环境状态,Agent又会执行对应的动作…以此类推持续进行下去,直到无法继续。
Policy Gradient就是基于我们的策略Policy来做梯度下降从而优化我们的模型。
What is MCTS?
MCTS也就是蒙特卡罗树搜索(Monte Carlo Tree Search),是一类树搜索算法的统称,可以较为有效地解决一些探索空间巨大的问题,例如一般的围棋算法都是基于MCTS实现的。MCTS要解决的问题是搜索空间足够大,不能计算得到所有子树的价值,这是需要一种较为高效的搜索策略,同时也得兼顾探索和利用,避免陷入局部最优解。
MCTS可以无限循环,而每一次循环都由以下4个步骤构成:
- Selection:从根节点开始,连续选择子节点向下搜索,直至抵达一个叶节点。子节点的选择方法一般采用UCT(Upper Confidence Bound applied to trees)算法,根据节点的“胜利次数”和“游戏次数”来计算被选中的概率,保持了Exploitation和Exploration的平衡,是保证搜索向最优发展的关键。
- Expansion:在叶节点创建多个子节点。
- Simulation:在创建的子节点中根据roll-out policy选择一个节点进行模拟,又称为playout或者rollout。它和Selection的区别在于:Selection指的是对于搜索树中已有节点的选择,从根节点开始,有历史统计数据作为参考,使用UCT算法选择每次的子节点;Simulation是简单的模拟,从叶节点开始,用自定义的roll-out policy(可以只是简单的随机概率)来选择子节点,且模拟经过的节点并不加入树中。
- Backpropagation:根据Simulation的结果,沿着搜索树的路径向上更新节点的统计信息,包括“胜利次数”和“游戏次数”,用于Selection做决策。
RL
- agent:生成模型
- state:生成的token
- action:生成下一个token的操作
BLEU:nlp中机器翻译的模型评估指标
文本生成相关工作
- variational autoencoder (VAE) that combinesdeep learning with statistical inference intended to representa data instance in a latent hidden space
- proposed an alternativetraining methodology to generative models, i.e. GANs, wherethe training procedure is aminimaxgame between a gener-ative model and a discriminative model.However, little progress has been madein applying GANs to sequence discrete data generation prob-lems, e.g. natural language generation.This isdue to the generator network in GAN is designed to be ableto adjust the output continuously, which does not work ondiscrete data generation
- The most popular way oftraining RNNs is to maximize the likelihood of each tokenin the training data whereas pointedout that the discrepancy between training and generatingmakes the maximum likelihood estimation suboptimal andproposed scheduled sampling strategy (SS).
- the sequence data generation can be formulated as a sequentialdecision making process, which can be potentially be solvedby reinforcement learning techniques.
SeqGAN
基于RL的生成器对GAN进行扩展,解决序列生成问题
鉴别器通过蒙特卡洛方法在每次结束时提供一个奖励信号,生成器使用估计的总体奖励选择动作并学习策略。
policy的模型是:
网络结构
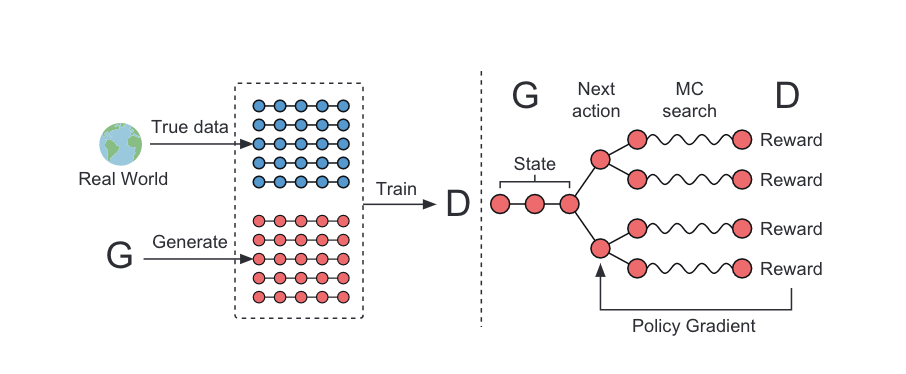
左边是GAN的训练步骤一,根据真实样本和伪造样本训练判别器D网络,这里的D网络用的CNN实现。
右边是GAN的训练步骤二,根据D网络回传的判别概率通过增强学习更新G网络,这里的G网络用的LSTM。
SeqGAN via Policy Gradient
其中,$R_T$是整个序列的奖励,奖励来自于判别器$D_\phi$。$Q_{D_{\phi}}^{G_\theta}(s,a)$是序列的作用值函数。目标函数的合理性应该是:从给定的初始状态,generator的目标是产生一个序列,使得discriminator认为是真的。
下一个问题是如何预测the action-value function。在这篇文章中,作者采用强化学习算法。如果判别器D认为给定的fake sequence是真的,其概率记为reward,此时,概率越高,reward越大,这两者是成正比例关系的。正式的来讲我们有如下公式:
然而,这个discriminator仅仅提供了一个reward给一个已经结束的sequence。然而我们实际关系的是长期的回报,在每一个时间步骤,我们不但应该考虑到previous tokens的拟合程度,也要考虑到the resulted future outcome。就像是下棋的游戏。因此,为了评价the action-value for an intermediate state,我们采用 MC search with a roll-out policy to sample the unkown last T-1 tokens。我们表示一个 N-time 的 MC search 为:
在我们的实验当中,$G^\beta$ 也设置为 the generator。为了降低 variance,并且得到更加精确的 action value 的估计值,我们运行 the roll-out policy starting from current state 直到 序列的结束,N times,以得到一批输出样本。所以,我们有:
我们看到,当没有立刻的奖赏的时候,函数被迭代的定义为the next-state value starting from states′=Y1:tand rolling out to the end.
利用判别器D作为奖赏函数的一个函数是为了进一步的提升生成式模型,它可以被动态的更新,一旦我们有了更加realistic的生成序列,我们应该重新训练判别器模型,公式如下:
当一个新的判别式模型已经被训练完毕的时候,我们已经准备好来更新generator,所提出的基于策略的方法依赖于优化一个参数化的策略,来直接最大化the long-term reward。目标函数J的梯度可以写为:
上述形式是由于the deterministic state transition and zero intermediate rewards。利用likelihood ratio,我们构建一种无偏估计在每一轮中
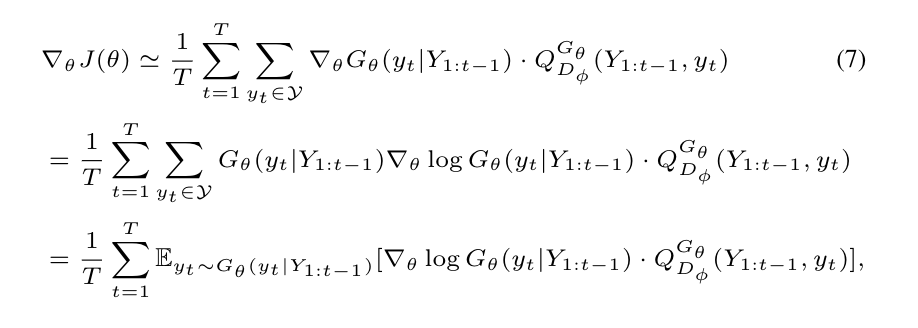
其中$Y_{1:t}$是观察到的 intermediate state sampled from $G_\theta$。因为期望E[·]可以通过采样的方法进行估计,然后更新生成器的参数。
其中,$\alpha$代表了对应的适合h-th step的学习率。
生成模型$G_\theta$
文章中使用RNN模型作为生成模型,RNN将输入嵌入表示$x1,…,x_T$映射为序列隐层$h_1,…,h_T$,通过递归的使用更新函数g:
然后一层softmax神经网络层z,将隐层映射到输出单词分布(token distribution)
其中c是偏置,V是权重矩阵,为了避免梯度消失和梯度爆炸,这里实际上使用LSTM神经单元
What is LSTM?
RNN是包含循环的网络,允许信息的持久化。链式的特征揭示了 RNN 本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构
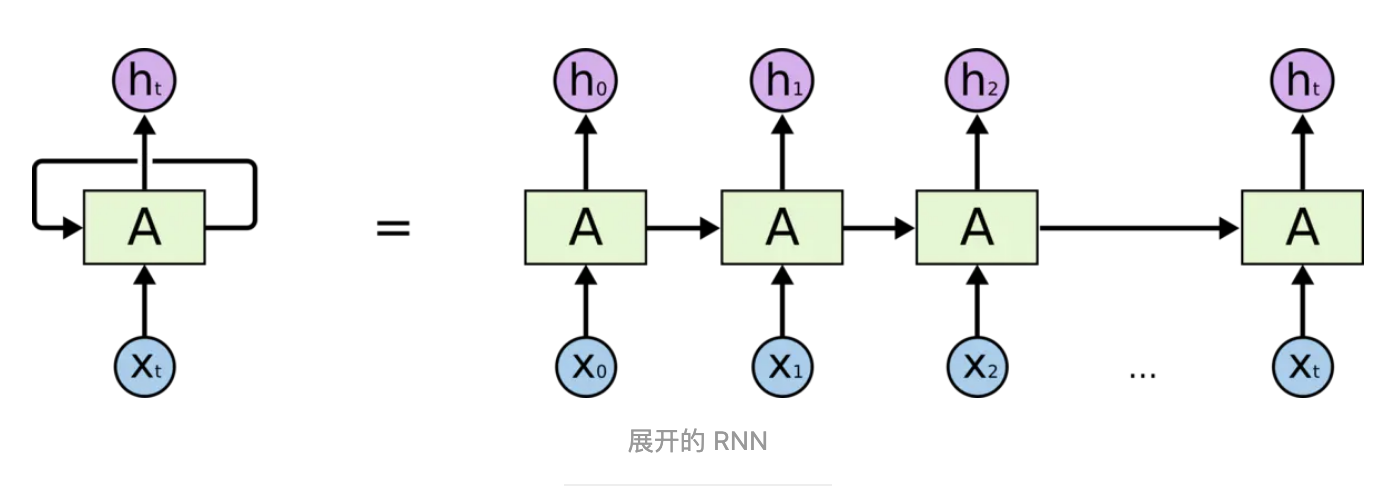
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。但是同样会有一些更加复杂的场景。这种场景下相关信息和当前预测位置之间的间隔会变得非常大,不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。在理论上,RNN 绝对可以处理这样的 长期依赖问题。人们可以仔细挑选参数来解决这类问题中的最初级形式,但在实践中,RNN 肯定不能够成功学习到这些知识。
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
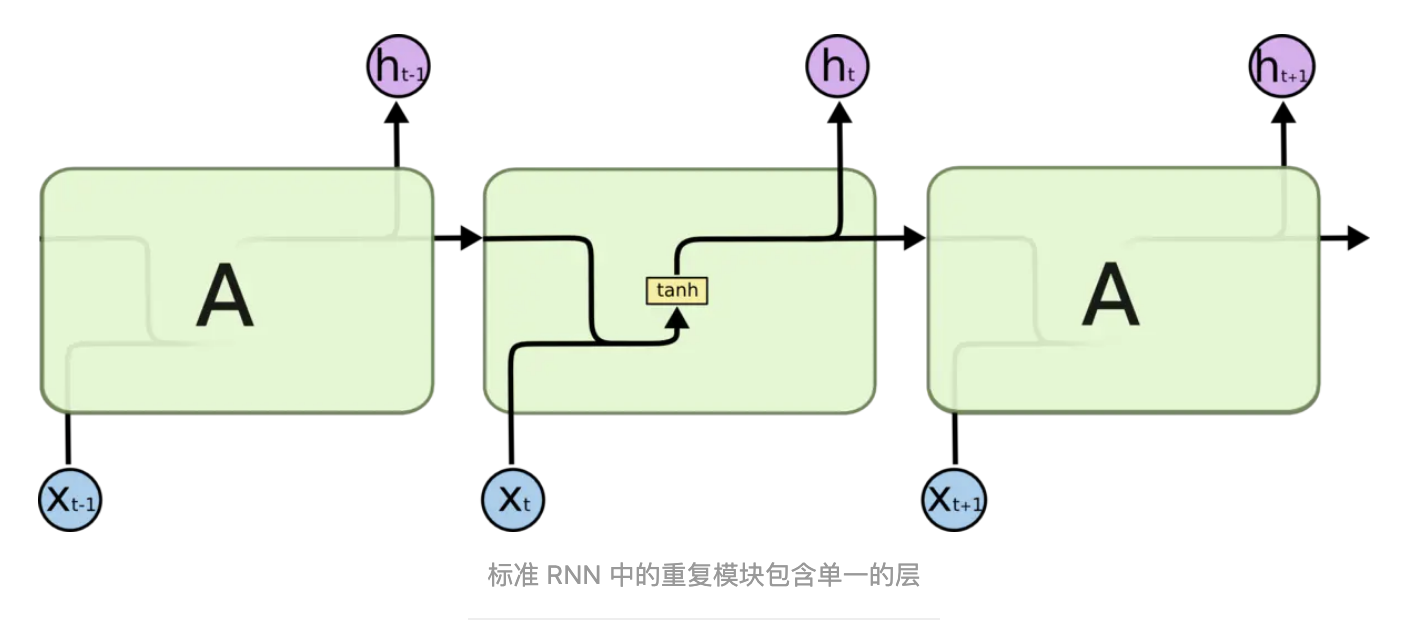
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
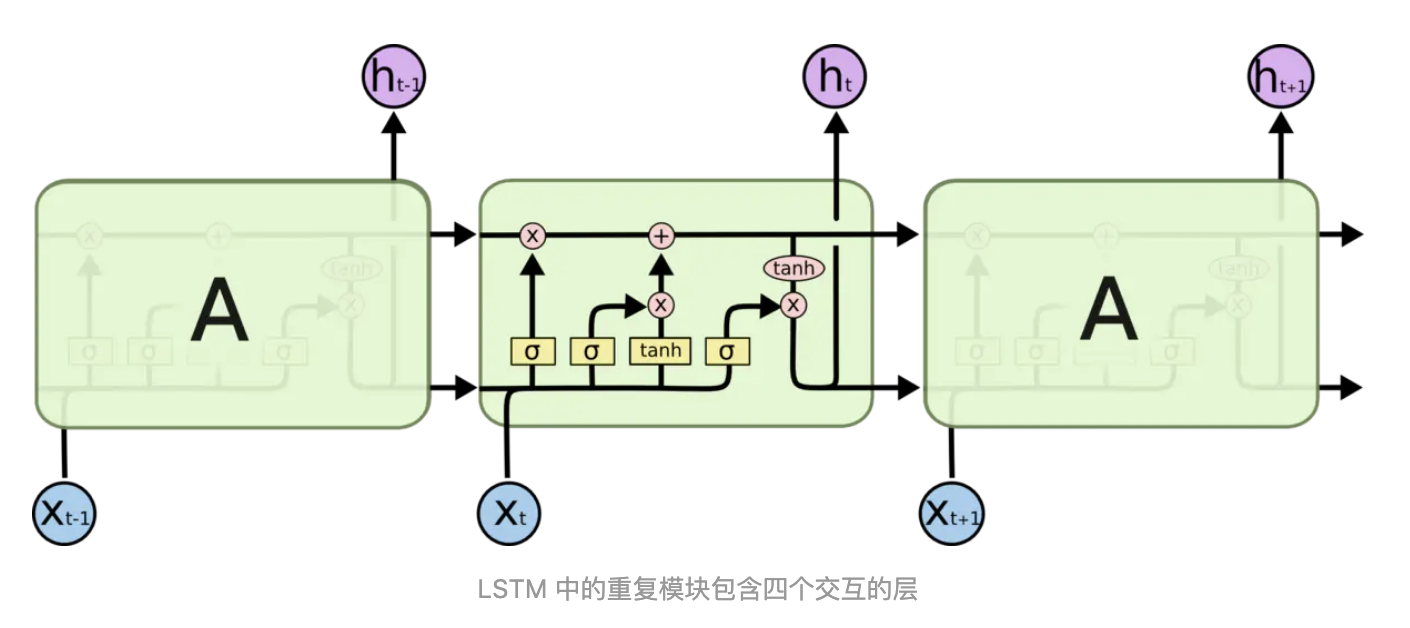
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
判别器模型$D_\phi$
文中判别器选用的是CNN,生成的序列长度是固定的T ,并且CNN通过使用max-over-time池化操作这样可以适用于变长序列判别。max-over-time池化操作,也就是对每个feature map选取最大值,这样只需要filter个数固定那么池化后得到的向量长度就是固定的,就自然适应于变长的序列。
我们首先将输入序列$x_1,…,x_T$表示为:
这里$\bigoplus$表示并置,也就是并置为一个矩阵,其中$x_t\epsilon R^k$,是k维的向量,得到的矩阵是$\varepsilon_{1:T}\epsilon R^{T*k}$,如上图所示,然后使用一个核做一个窗口大小为l个单词的卷积操作,产生一个feature map:
这里$\bigotimes$表示度对应元素相乘,b是偏置,$\rho$是一个非线形函数,我们可以使用具有不同窗口大小的各种数量的内核来提取不同的特征,最终我们对feature map使用max-over-time池化操作得到
算法流程图如下

算法步骤
- 随机初始化G网络和D网络参数
- 通过MLE预训练G网络,目的是提高G网络的搜索效率
- 通过G网络生成部分负样本预训练D网络
- 通过G网络生成sequence用D网络去评判,得到reward,根据计算得到每个action选择得到的奖励并求得累计奖励的期望,以此为loss function,并求导对网络进行梯度更新
- 根据GAN网络结构可知,训练目标是最大化识别真实样本的概率,最小化误识别伪造样本的概率
- 循环以上过程直到收敛