入门机器学习的最简单案例就是对MNIST手写数据集的识别。本篇文章将会通过Pytorch框架完成对MNIST手写数据集识别。首先我们来简单了解一下MNIST。
What is MNIST?
MNIST数据集是一个有名的手写数字数据集,该数据集包含60000个用于训练的示例和10000个用于测试的示例,这些数字已经经过尺寸标准化并位于图像中心,图像的固定大小是28*28像素,值为0到9。
Pytorch识别MNIST
今天我们将通过Pytorch实现对MNIST的识别。对于Pytorch的安装这里不做介绍。
版本说明
1 | python==3.8 |
本次代码利用pycharm进行编写,环境使用为anaconda3,使用cpu进行训练。
模块的导入
在使用Pytorch之前,我们要导入相关模块
1
2
3
4
5
6import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
import torch.optim as optim其中,
datasets用来导入MNIST数据集,transforms用于图像的转换处理,DataLoader用于加载数据集,optim用来加载优化器。参数定义
在数据集识别中我们要定义比较多的参数和超参数,因为数据集比较大,如果一次训练太多的数据,效果不会很好,因此我们通常对数据集的训练数据进行分批训练,还有就是我们一般对一个数据集的所有数据不止训练一轮次,例如MNIST数据集,我们对它的60000张训练数据会进行多个轮次的训练,这样会产生更好的训练效果。具体定义如下
1
2
3
4
5
6batch_size = 16 #批次大小,一次训练16张数据
epochs = 5 #对于60000张训练数据进行5轮训练
transforms = transforms.Compose([
transforms.ToTensor(), #将图片转换为张量
transforms.Normalize((0.1307,),(0.3081,)) #进行归一化处理,参数默认使用官网给定值
])数据集加载
定义好参数之后我们开始对数据集进行加载,利用
torchvision中的datasets模块就可以导入MNIST数据集。之后再利用DataLoader对数据集进行加载即可1
2
3
4train_set = datasets.MNIST("data",train=True,download=True,transform=transforms)
test_set = datasets.MNIST("data",train=False,download=True,transform=transforms)
train_loader = DataLoader(train_set,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_set,batch_size=batch_size,shuffle=True)因为MNIST中分为训练数据和测试数据,因此我们需要进行两次导入和加载。其中
datasets.MNIST的第一个参数是数据集导入的路径,这里使用"data"直接将数据集导入代码同级目录下,如果没有data目录会自动创建,在训练数据集的导入中,第二个参数train要设置为True,而在测试数据集中因为不需要进行训练,所以设置为False即可。后面的transform参数就是对图像进行一个处理,例如转换成张量和进行归一化处理,在DataLoader的参数中,batch_size就是每次训练的个数,shuffle参数的含义就是在每次训练的个数中进行一个随机打乱。这也算是处理过拟合现象的一种方式。模型的定义
在对数据集加载完成之后,我们开始定义自己的网络模型。我们使用了两个卷积层,之后使用了两个全连接层。在激活函数的选择上,我们使用relu作为激活函数,之后我们进行了一个2*2的池化操作,再对图像进行了一个拉平操作,最后我们采用
log_softmax函数进行输出。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,10,5)
self.conv2 = nn.Conv2d(10,20,3)
self.fc1 = nn.Linear(20*10*10,500)
self.fc2 = nn.Linear(500,10)
def forward(self,x):
input_size = x.size(0) #获取batch_size
x = self.conv1(x) #卷积
x = F.relu(x) #激活
x = F.max_pool2d(x,2,2) #池化
x = self.conv2(x)
x = F.relu(x) # 激活
x = x.view(input_size,-1) #拉平
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x,dim=1)
return output模型的使用
1
2model = Net()
optimizer = optim.Adam(model.parameters())第一行代码我们实例化了一个模型,第二行代码我们利用
optim选择合适的优化器,这里我们使用了Adam优化器,你也可以根据需求采用其他优化器例如SGD。模型训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def train_model(model, train_loader,optimizer ,epoch):
#模型训练
model.train()
for batch_index,(data,target) in enumerate(train_loader):
#梯度初始化为0
optimizer.zero_grad()
#预测
output = model(data)
#计算损失
loss = F.cross_entropy(output,target)
#反向传播
loss.backward()
optimizer.step()
if batch_index % 600 == 0: #每训练600次进行一次输出
print("Train Epoch : {} \t Loss : {:.6f}".format(epoch,loss.item()))在这里我们定义了一个训练函数,参数传递了定义的模型、训练的数据、优化器和训练轮次。在第二行代码中
model.train的含义是在训练过程中采用Dropout和Normalization。这样有助于优化训练。之后我们对训练数据中的data和target进行提取。target相当于数据的标签。接下来我们对优化器的梯度进行初始化,如果不进行初始化梯度累加就会影响训练效果。计算损失这里采用交叉熵损失。接下来就是很重要的一步,进行反向传播。最后使用optimizer.step()对模型进行更新。测试集验证
测试集的验证和训练集差不多,不同的地方是在训练之前采用
model.eval(),eval和train的区别在于,eval是不采用Dropout和Normalization。第二点就是在测试的时候不用计算梯度也不用进行反向传播。具体代码实现如下。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def test_model(model,test_loader):
#模型验证
model.eval()
#正确率
correct = 0.0
#测试损失
test_loss = 0.0
with torch.no_grad():#不会计算梯度也不会进行反向传播
for data,target in test_loader:
# data,target = data.to(device),target.to(device)
#测试数据
output = model(data)
#计算测试损失
test_loss+=F.cross_entropy(output,target).item()
#找到概率值最大的下标
pred = output.max(1,keepdim=True)[1] #值 索引
#pred = torch.max(output,dim=1)
#pred = output.argmax(dim=1)
#累计正确率
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("Test ---- Average loss : {:.4f},Accuracy : {:.3f}\n".format(test_loss,100.0*correct/len(test_loader.dataset)))训练和测试结果展示
1
2
3for epoch in range(1,epochs+1): #进行5轮次训练
train_model(model,train_loader,optimizer,epoch)
test_model(model,test_loader)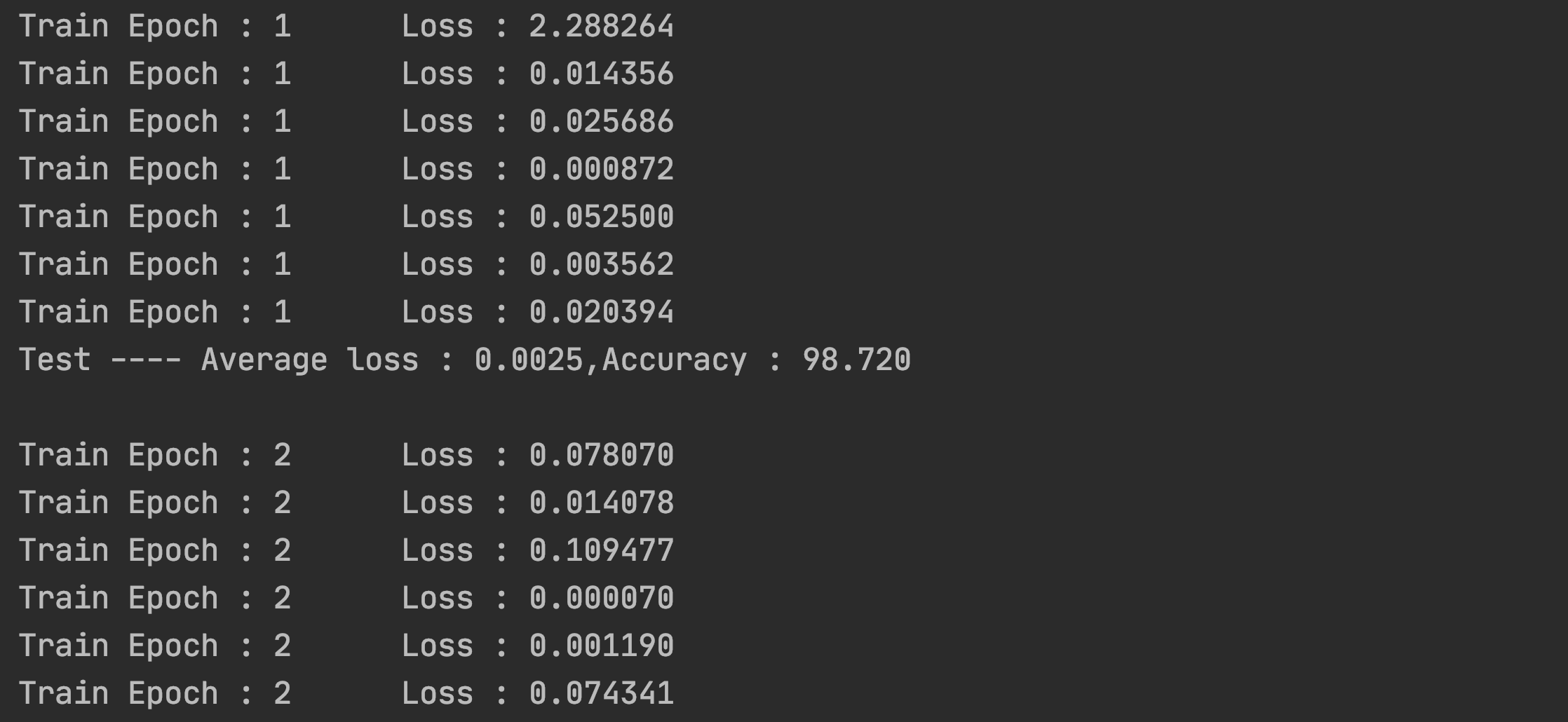
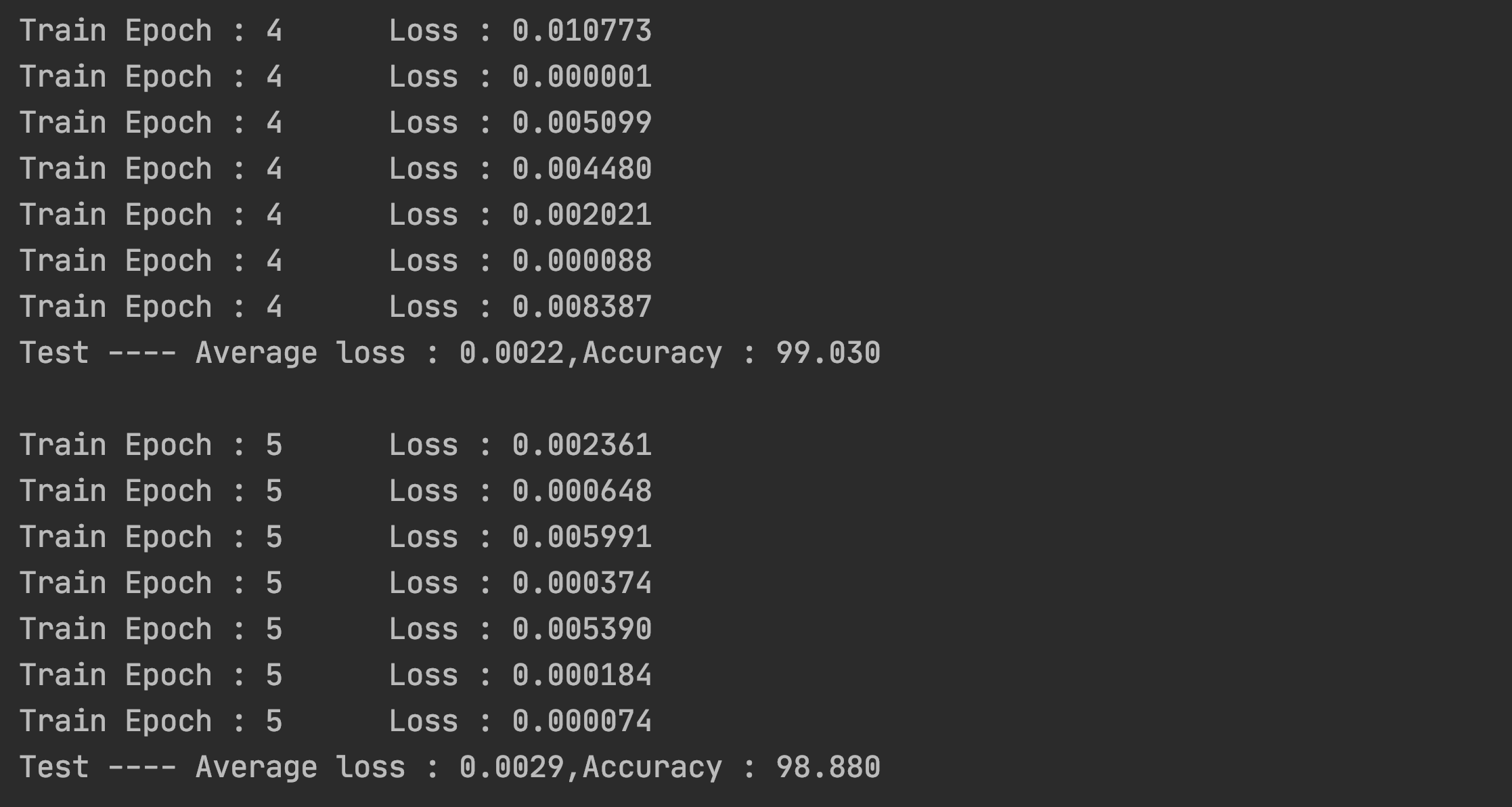
从图中我们可以看到训练效果并不随着训练轮次的增加而变得更好,在本次训练中,训练轮次为4的时候,准确率最高,达到了99.03%