前言
在上一篇文章里实现了MNIST手写数据集的识别之后,趁热打铁,这一篇文章使用GAN来实现MNIST数据集的生成。2014年Ian Goodfellow的那篇GAN是我接触的第一篇有关机器学习的文章。那篇文章被称为GAN的开山之作,它提出了一种新的生成式框架,其中包括生成模型和鉴别模型。生成模型用于描述数据的分布,生成尽可能拟合真实数据的分布,而鉴别模型用于对生成模型各个迭代轮次产生的结果进行评估,其中利用到了一种博弈的思想。
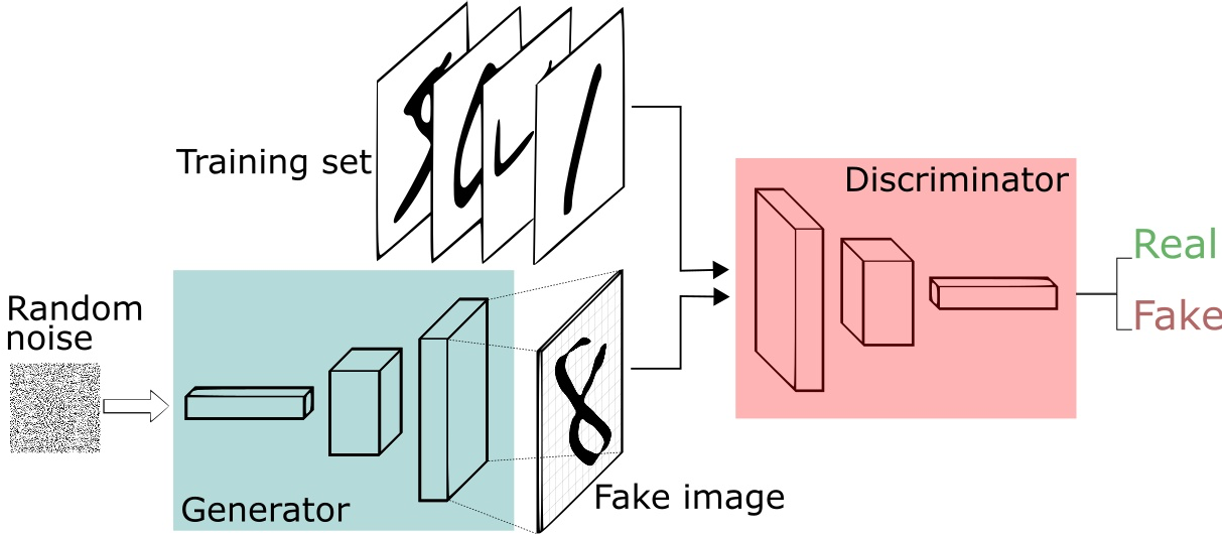
在GAN模型的后面是大量的度量单位和公式推导,在这里我们不做详细说明。今天主要是通过GAN的方式利用两个模型(卷积网络和线性网络)实现MNIST数据集的生成。
线性模型
首先还是模块的导入,对应相关模块的功能在上一篇文章已做了相关说明。
1 | import torch |
参数定义,其中z_dimension是随机生成噪声的维度,这里定义为100维,可以自定义。
1 | batch_size = 64 |
数据集的加载,由于是生成MNIST数据集,所以这次不需要对测试集进行加载,通过训练集进行训练生成即可。
1 | train_set = datasets.MNIST("data",train=True,transform=transforms,download=True) |
判别器的定义,采用三层的线性模型。Linear的两个参数分别是输出层和隐藏层。在第一层的输出层是784是因为MNIST图片大小是1*28*28,中间的隐藏层可以自定义,线性变换之后采用一个LeakyReLU的激活函数实现非线性映射,参数0.2是激活函数的斜率。最后使用Sigmoid函数实现概率值的映射,sigmoid常用作二分类问题。在这里使用sigmoid函数得到一个0到1的概率进行二分类。在forward函数中还采用了一个squeeze函数,这个函数主要对数据的维度进行压缩,去掉维数为1的的维度,默认是将a中所有为1的维度删掉。x.squeeze(-1)用于将二维压缩为一维。
1 | class Discriminator(nn.Module): |
生成器的定义,生成器和判别器的定义相同,也是经过一个三层的线性模型,其中第一个Linear函数的第一个参数是100,这是在前面参数定义的z_dimension = 100也就是随机噪声的维度,在生成器中使用的激活函数是Relu激活函数,最后一层Linear函数的输出层是784维对应了MNIST数据的大小,之后使用Tanh激活函数是希望生成的假的图片数据分布能够在-1~1之间。
1 | class Generator(nn.Module): |
实例化生成器模型和判别器模型。
1 | Dis = Discriminator() |
定义损失函数和优化器,其中BCELoss是单目标二分类交叉熵函数。
1 | criterion = nn.BCELoss() |
开始训练。训练集中包含图片和标签数据。通过img.size(0)可以得到每一批数据的数量,也就是我们之前设定的batch_size大小,随后通过view函数将数据进行拉平成二维方便后续的处理,之后分别计算真实图片和假图片的损失并进行迭代训练,最后将生成的真实图片和假的图片保存在img文件夹下。
1 | for epoch in range(epochs): |
结果展示,下图是训练3轮次后生成的图像。因为代码是在自己电脑上跑的所以训练的次数比较少,生成的图片不太清晰。

训练20轮次的结果
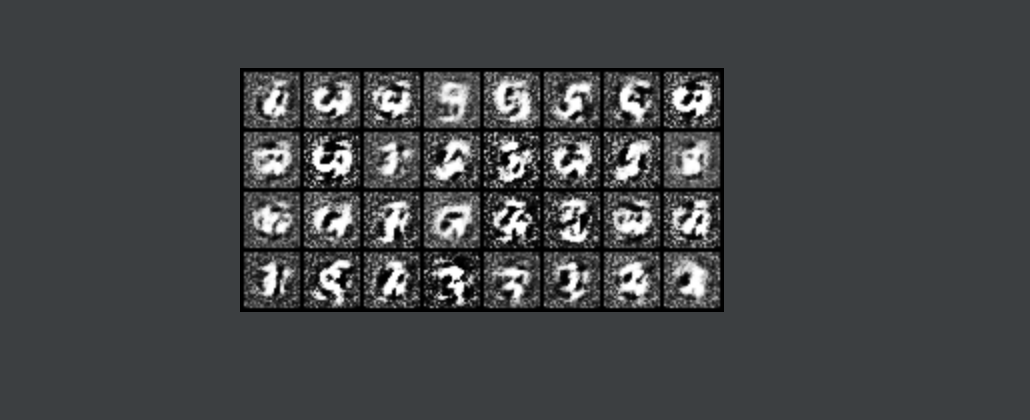
训练50轮次的结果,怎么感觉越训练越差了。。。后面再看看具体调优的事。
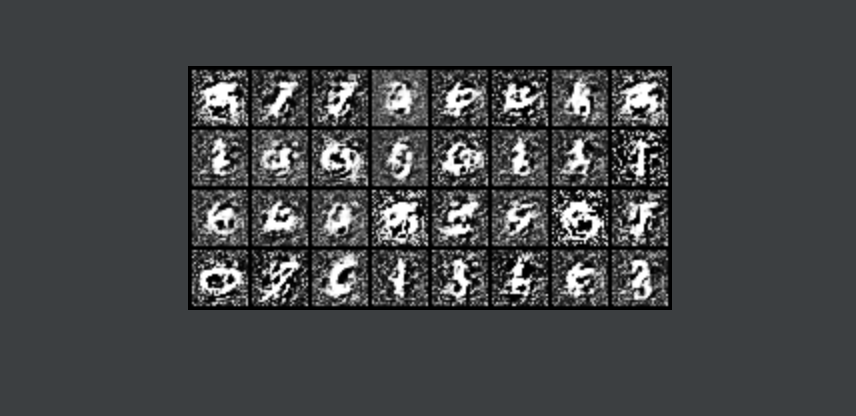
卷积模型
卷积模型和线性模型的代码主要是模型的定义处不太相同。
首先是判别器的定义,其中判别器采用的是两层的卷积模型和一层的全连接层
1 | class Discriminator(nn.Module): |
其次是生成器的定义,生成器首先是经过一个全连接层,其中input_size是100也就是随机噪声的维度,num_feature是我们定义的数值为3136,这个可以自定义,只要最后转为[batch,1,28,28]形式就行。其中 BatchNorm2d函数用来做归一化处理,这里我们只写入了BatchNorm2d的第一个参数,也就是输入图像的通道数,所以刚开始是1。后面的通道数随着卷积操作的改变而改变。
1 | class Generator(nn.Module): |
实例化生成器和判别器
1 | Dis = Discriminator() |
进行训练,这里需要注意的是在训练的时候不需要使用view函数将img转为二维,这里直接对四维数据进行处理。剩下的操作和线性模型相同。
1 | for epoch in range(epochs): |
线性模型完整代码
注意要在同级目录下创建一个img的文件夹
1 | import torch |
卷积模型完整代码
1 | import torch |