Generating Adversarial Examples with Adversarial Networks
论文链接:https://arxiv.org/abs/1801.02610
代码链接:https://github.com/mathcbc/advGAN_pytorch
简介
为了更有效地生成感知真实的对抗性样本,本文提出一种基于GAN的方式来产生对抗样本。
1.训练一个产生扰动的前馈网络来产生不同的对抗性样本。
2.训练一判别网络来确保生成的样本是真实的。
3.应用了GAN网络在半白盒和黑盒设置中产生对抗性样本。
4.借助了CGAN的思想利用相似的范例生成高质量的图片。
主要贡献
- 训练了一个条件对抗性网络,直接生成对抗性实例,不仅可以生成感知逼真的实例,对不同目标模型的攻击成功率最高,而且生成过程更高效。
- 证明了AdvGAN可以通过训练一个提取的模型来攻击黑盒模型。我们提出用查询信息动态训练提取的模型,实现高黑盒攻击成功率和有针对性的黑盒攻击。
- 使用最先进的防御方法来抵御对抗性示例,并表明AdvGAN在当前防御下实现了更高的攻击成功率。
相关工作
回顾了之前的一些对抗性例子和生成对抗网络。总结来看,对抗样本的生成方式无非是以下三种。
- 基于梯度的生成方式(FGSM和PGD)
- 基于优化的生成方式(CW和JSMA)
- 基于GAN的生成方式
作者提出了基于梯度和基于优化方式产生对抗样本的一些局限性。对于基于梯度来讲,在白盒攻击下攻击者需要完全清楚模型的参数。对于基于优化来讲,存在优化过程慢,只能优化每个特定实例的扰动等问题。相比之下,使用GAN来生成对抗样本,能够在不同防御下实现更高的攻击成功率。
AdvGAN框架
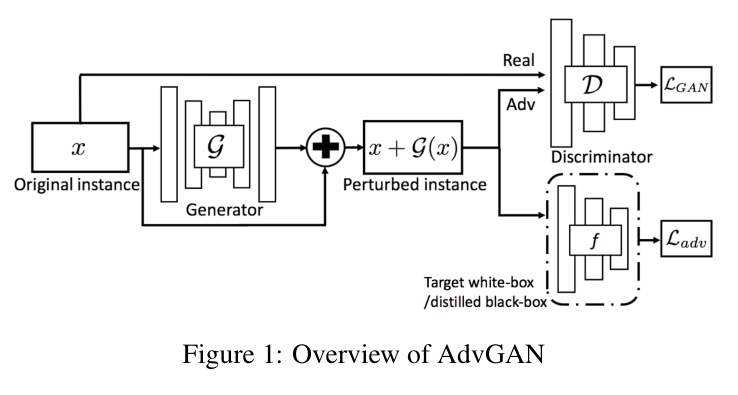
AdvGAN的整体框架如上图所示,主要包含三个部分。一个生成器G,一个判别器D和一个目标攻击网络模型f。从左边开始分析,生成器G会接受一张原始图像输入x,通过生成器G之后会生成一个微小的扰动G(x),接着扰动实例x+G(x)会被分别送入判别器D和目标攻击网络模型f,判别器的任务是分辨生成数据和原始数据,判别器的作用是引导生成数据与原始类别数据不可区分。在目标攻击网络模型f中,扰动实例x+G(x)会作为输入参数,为了欺骗学习模型,作者先进行了白盒攻击,在白盒攻击下经过f输出对抗损失,对抗损失表示预测类别和要攻击到其错误分类类别的距离或者是与真实类别标签相反的距离。
其中在2014年Goodfellow提出的对抗损失可以被定义如下:
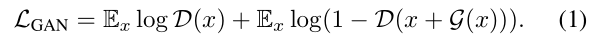
在这里判别器D的目标是分辨带有扰动的数据x+G(x)和原始数据x,其中真实数据是从真实类别中被采样的,目的是为了使得生成的数据尽可能的接近原始数据。
目标攻击网络模型f的损失被定义如下:
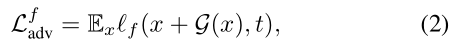
其中t是目标标签,$l_f$表示损失函数,在文中使用的是交叉熵损失来训练原始模型f。$L^f_{adv}$损失函数引导带有扰动的图像被错误分类成目标类别t。
为了限制扰动的大小,作者在L2 norm的基础上加了一个hinge loss,损失被定义如下:
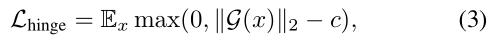
这里c代表一个用户所定义的最大边界,可以稳定GAN的训练。
最终目标函数被表示为:
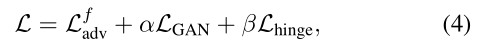
其中$\alpha$和$\beta$用来控制每个损失函数之间的相对重要程度$L^f_{adv}$用来生成对抗样本,$L_{GAN}$是为了使带有扰动的数据与原始数据相似,$L_{hinge}$用来限制perturbation的大小。
生成对抗网络进行黑盒攻击
静态蒸馏
对于黑盒攻击,我们假设攻击者对于训练数据和需要攻击的模型没有先验知识。在我们进行的实验中,因为我们假设攻击者对于训练数据和模型没有先验知识,因此我们随机选取与原始训练数据不相交的图像数据去进行模型蒸馏。为了实现黑盒攻击,我们首先基于黑盒模型b的输出构建了一个蒸馏网络f。一旦我们获得了经过蒸馏的网络f,我们就会执行与白盒设置中描述的相同的攻击策略。蒸馏网络目标函数定义如下:
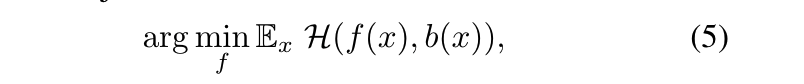
其中f(x)和b(x)分别表示蒸馏模型和黑盒模型的输出,H表示交叉熵损失函数,通过使用所有的训练图像去优化上面的目标函数,我们可以获得效果接近于黑盒模型b的蒸馏模型f。然后我们可以在这个蒸馏网络上进行我们的攻击策略。
不同于训练判别器D,在训练判别器D的过程中,我们只使用来自原始类别的真实数据去引导生成的对抗样本实例尽可能地接近它的原始类别。在这里我们训练蒸馏模型使用的是来自所有类别的全部数据。
动态蒸馏
仅仅用所有原始的训练数据训练经过提炼的模型是不够的,因为我们不清楚黑盒和经过提炼的模型在生成的对抗样本上的表现有多接近,而这些样本在之前的训练集中没有出现过。在这里作者提出一种代替最小化方法去动态查询和联合训练蒸馏模型f和生成器G 。在每一次迭代中执行下面两个步骤:

1.对于给定的蒸馏网络$f_{i-1}$更新$G_i$:根据白盒攻击的算法步骤,利用前一个蒸馏网络$f_{i-1}$去训练生成器和判别器,初始化$G_i$的权重为$G_{i-1}$的权重,$G_i,D_i=arg\underset{G}{min}\underset{D}{max}L^{f_{i-1}}_{adv}+\alpha L_{GAN}+\beta L_{hinge}$
2.对于给定的生成器$G_{i-1}$更新$f_i$:首先我们使用$f_{i-1}$的权重初始化$f_i$的权重,然后对于给定的从$G_i$生成的对抗样本x+G(x),蒸馏模型$f_i$会根据最新的在黑盒模型上对抗样本的查询结果和原始数据进行参数更新。$f_i=arg\underset{f}{min}E_xH(f(x),b(x))+E_xH(f(x+G_i(x)),b(x+G_i(x)))$这里我们使用原始图像x和生成的对抗样本x+$sG_i(x)$去更新蒸馏网络。
实验结果
这一章节,我们首先评估AdvGAN在半白盒和黑盒情景下对于MNIST和CIFAR-10的效果。我们也在ImageNet上进行的半白盒攻击的测试。接着我们应用AdvGAN在不同的目标模型上生成对抗样本和在目前最好的防御方法下测试其攻击成功率,结果显示我们的方法与其他目前存在的方法相比能实现更高的攻击成功率。为了保证比较的公平性,我们利用各种攻击方法生成的对抗样本都是在相同的无穷范式的约束下(在MNIST是0.3,在CIFAR-10是8/255)。大致来看,AdvGAN对比其他白盒攻击和黑盒攻击的方法体现出了几点优势。

就计算效率来讲,AdvGAN执行速度更快甚至比高效的FGSM方法快,即使AdvGAN需要额外的训练时间去训练生成器。我们这里对比的所有攻击策略除了基于迁移性攻击策略,其他都可以进行目标攻击。除此之外,FGSM和基于优化的方法只能进行白盒攻击,但是AdvGAN可以在半白盒的情景下进行攻击。
实验细节
采用与image-to-image转换文献类似的生成器和鉴别器结构,采用C&W方法中提出的损失函数作为损失函数。在黑盒攻击的情景下表示蒸馏网络。我们设置信度为0,优化方法使用Adam,批大小为128,学习率为0.001。对于生成式对抗网络的学习,我们使用最小平方目标函数,因为它有更好更稳定的结果。
半白盒攻击下的AdvGAN
我们用不同的模型结构来评估AdvGAN在MNIST和CIFAR-10数据集上的表现。我们首先应用AdvGAN来执行针对MNIST的不同模型的半白盒攻击。可以看出AdvGAN能够生成对抗实例以高攻击成功率攻击所有模型。我们还从相同的原始实例x生成对抗样本,攻击到其他不同的类别,在MNIST的半白盒情景中,我们可以看到生成的不同模型的对抗样本看起来与原始图像十分接近。此外,我们还分析了基于不同损失函数的MNIST攻击成功率。在相同的perturbation下,如果我们把上面定义的完整的损失函数代替成Baluja和Fischer使用的损失函数,攻击成功率为86.2%。如果把损失函数替代为$L=L_{hinge}+L^f_{adv}$,攻击成功率为91.1%,AdvGAN的成功率为98.3%。

黑盒攻击下的AdvGAN
黑盒攻击基于动态蒸馏策略,构造一个本地模型去蒸馏我们需要攻击的模型f。我们选择模型C作为我们本地模型的架构。注意的是我们随机选取与原始训练数据不同的图像实例子集去训练本地模型。我们假设攻击者对于训练数据和模型没有任何的先验了解。通过动态蒸馏策略,由AdvGAN产生的对抗样本实现了在MNIST数据集上超过90%的攻击成功率和在CIFAR-10上超过80%的攻击成功率。与此同时静态蒸馏在两个数据集上分别达到了30%和10%的攻击成功率。
我们使用AdvGAN在MNIST上生成能被错误分类到特定类别的对抗样本。通过对比生成的对抗样本和原图,我们可以看到对抗样本可以实现和原图一样高的视觉质量。特别地,原始图像被对抗噪声强调的部分暗含着视觉现实的操作。图3显示了在CIFAR-10上产生的对抗样本结果。这些对抗样本实例和原始图像相比具有照片的真实性。

在防御算法下的攻击效果
AdvGAN尝试生成隐含在真实数据分布中的对抗样本实例,它与其他攻击策略相比能在本质上产生更加真实的对抗扰动。因此AdvGAN有更高的概率能产生能抵抗不同防御方法的对抗样本。在
威胁模型
大多数现在的防御策略在它们受到攻击时,并不表现得那么鲁棒。这里我们考虑一个较弱的威胁模型,当对手不知道防御方法,并直接尝试攻击原始的学习模型,这也是C&W分析的第一个威胁模型。在这种场景下,假设攻击者依然能够成功地攻击模型,这表明攻击策略是具有鲁棒性的。在这种场景下,我们首先应用不同的攻击算法在不知道被攻击的模型使用了什么防御算法的前提下,去产生对抗样本。然后我们使用不同的防御机制直接对这些产生的对抗样本进行防御。
半白盒攻击
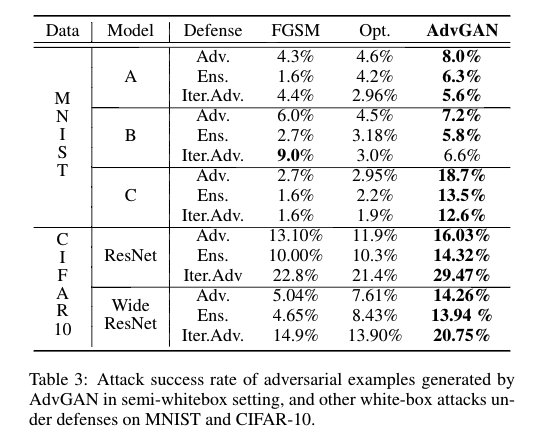
在半白盒攻击下,攻击者对模型结构和参数能进行白盒式访问。我们将图1中的f替换成我们的威胁模型A,B,C。我们分别使用标准的FGSM对抗训练,集成对抗训练,迭代对抗训练这三种对抗训练算法去针对不同的模型架构去训练防御模型。我们通过攻击这些防御模型来评估攻击的有效性。我们的实验结果显示使用AdvGAN生成的对抗样本的攻击成功率比FGSM和Opt都高。如下图表3所示:
黑盒攻击
对于AdvGAN,我们使用模型B作为黑盒攻击的模型,训练一个蒸馏模型进行黑盒攻击,攻击成功率在表4。
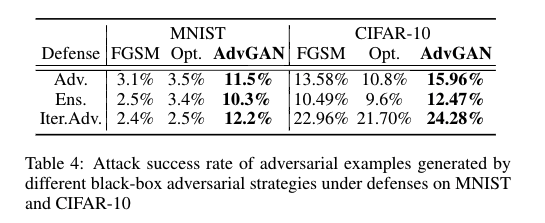
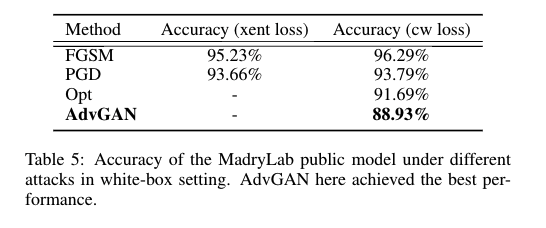
我们采用基于迁移性进行攻击的FGSM和Opt。我们使用FGSM和Opt在MNIST上攻击模型A,然后我们使用这些对抗样本去攻击模型B,显示对应分类的正确率。我们可以看到由AdvGAN生成的对抗样本的攻击成功率始终比其他攻击方法的高。对于CIFAR-10数据集,我们使用ResNet作为黑盒攻击模型,并且训练一个蒸馏模型对它进行黑盒攻击。为了与基于优化的黑盒攻击方法和FGSM进行对比,我们使用对Wide ResNet进行攻击生成的对抗样本在ResNet上测试。另外我们使用AdvGAN在MNIST挑战上,在表5上显示了几乎所有的标准攻击方法,其中AdvGAN实现了88.93%的攻击成功率在白盒攻击下。在与已经发表的黑盒攻击算法对比,AdvGAN实现了92.76%的攻击成功率,超过了所有其他在挑战中提交的最好的攻击策略。
在图4中,我们展示了随机挑选的由AdvGAN生成的原始图像数据和对抗样本。

结论
提出了一种基于生成式对抗网络的网络架构AdvGAN去生成对抗样本。在我们的网络架构中,前馈的生成器一旦训练完成,我们可以高效地生成对抗扰动。这种对抗样本在半白盒攻击和黑盒攻击下都能达到很高的成功率。另外,当我们使用AdvGAN去针对不同的未知防御方法的被攻击模型生成对抗样本时,生成的对抗样本可以保持高分辨率和高的视觉质量。能以高的攻击率成功攻击目前最好的防御方法。这个属性让AdvGAN成为有保障的提高对抗训练的途径。
复现代码分析
复现代码链接:https://github.com/mathcbc/advGAN_pytorch
training the target model
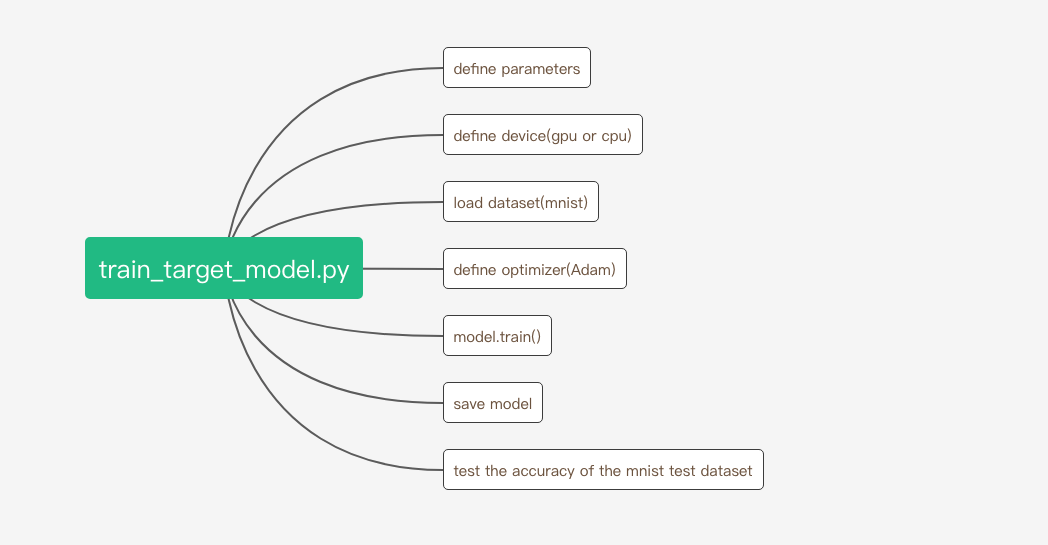
train_target_model.py的代码结构如下
模型定义在model.py文件中。模型采用了四个卷积层和三个全连接层。在forward函数中采用relu激活函数和池化操作并开启了dropout。
1 | class MNIST_target_net(nn.Module): |