SVHN数据集介绍
SVHN数据集是摘自Google街景图像中的门牌号,其风格与MNIST相似。其中包含了10个类别,数字1~9对应标签1~9,而“0”的标签则为10。其中训练集有73257张图像,测试集有26032张图像。
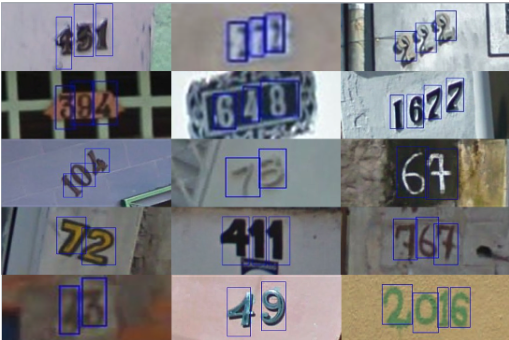
Pytorch识别SVHN数据集
模块导入
1 | import torch |
参数定义
其中Resize是对图像大小重新设定,ColorJitter可以改变图像的属性,例如亮度、对比度、饱和度和色调,RandomRotation可以使得图像在设定的角度范围内随机旋转。
1 | batch_size = 16 |
加载数据集
1 | train_set = datasets.SVHN("data_svhn","train",download=True,transform=transforms) |
网络定义
卷就完事了!4这里我采用了3个卷积层,激活函数使用的是Relu,还加入了池化操作,用了一个全连接层。在进行nn.Linear操作之前要使用view将四维拉成二维,因为全连接层的输入与输出都是二维张量。
1 | class SVHN_Net(nn.Module): |
实例化模型和优化器
1 | model = SVHN_Net() |
模型训练
1 | def train_model(model, train_loader,optimizer ,epoch): |
测试模型
1 | def test_model(model,test_loader): |
调用训练和测试模型
1 | for epoch in range(epochs+1): |
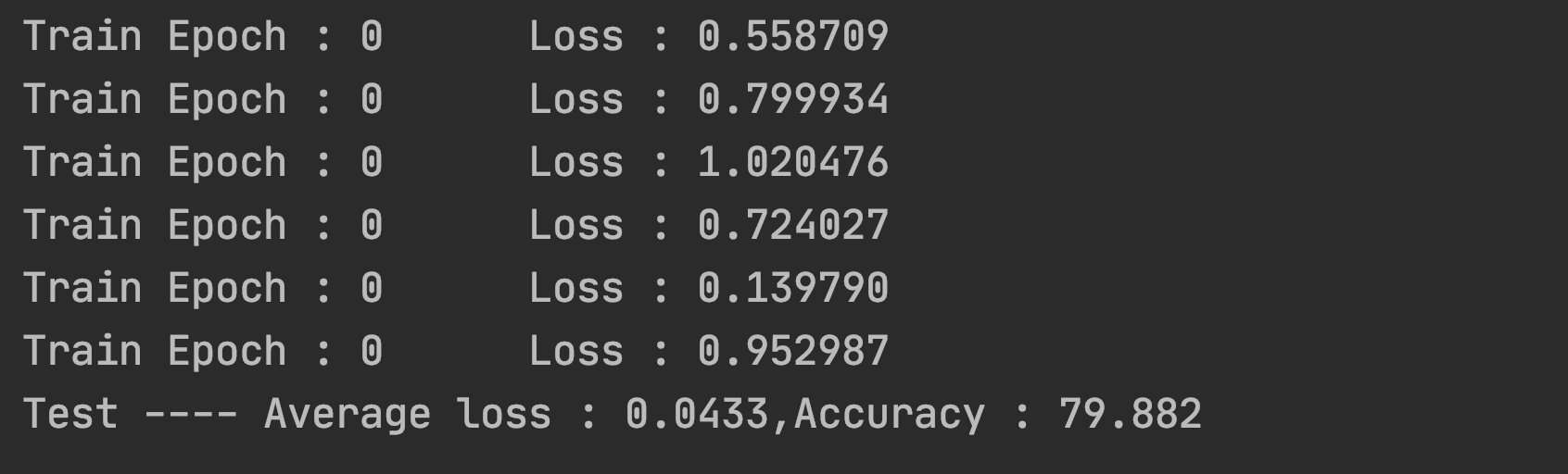
结果展示
….好家伙这也太低了
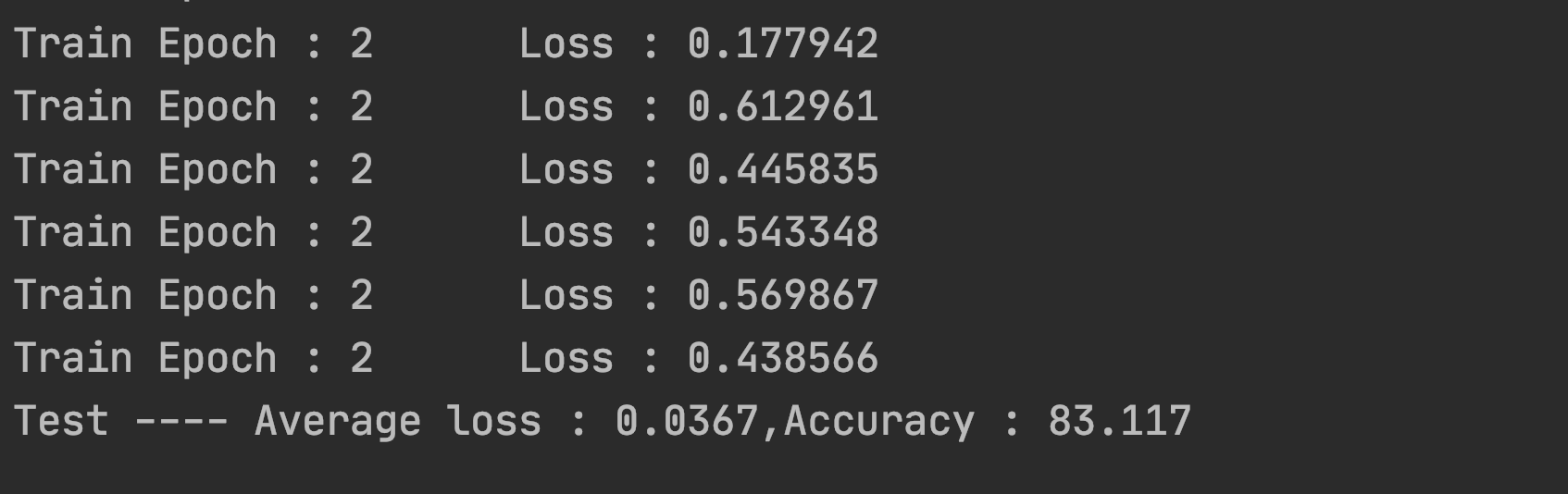
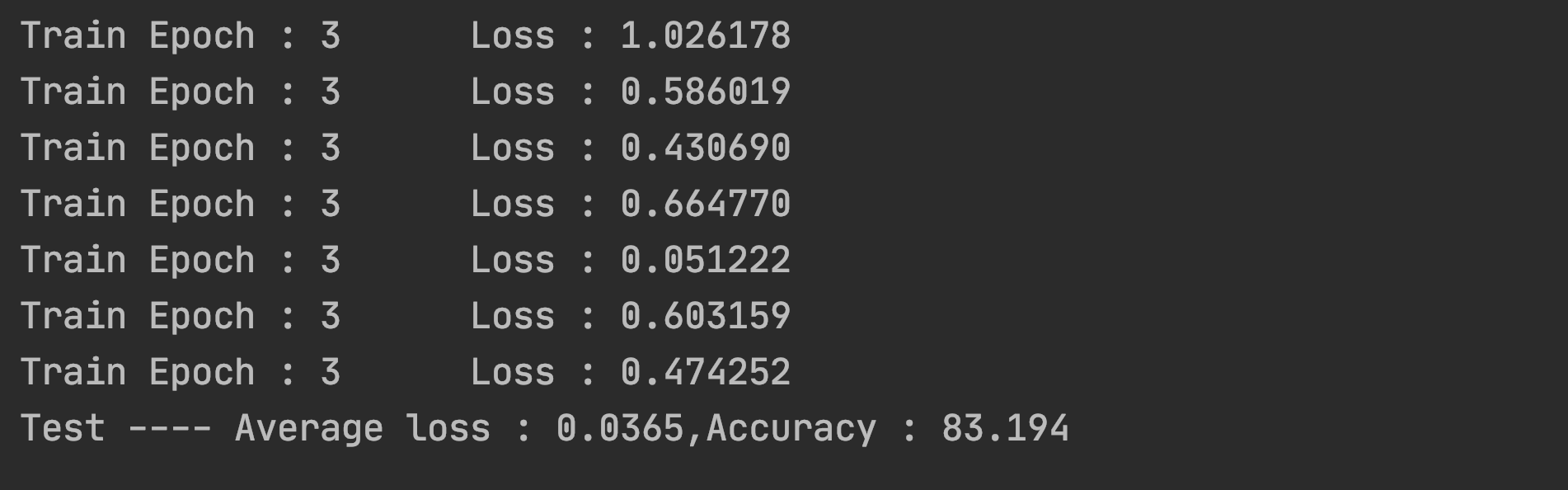
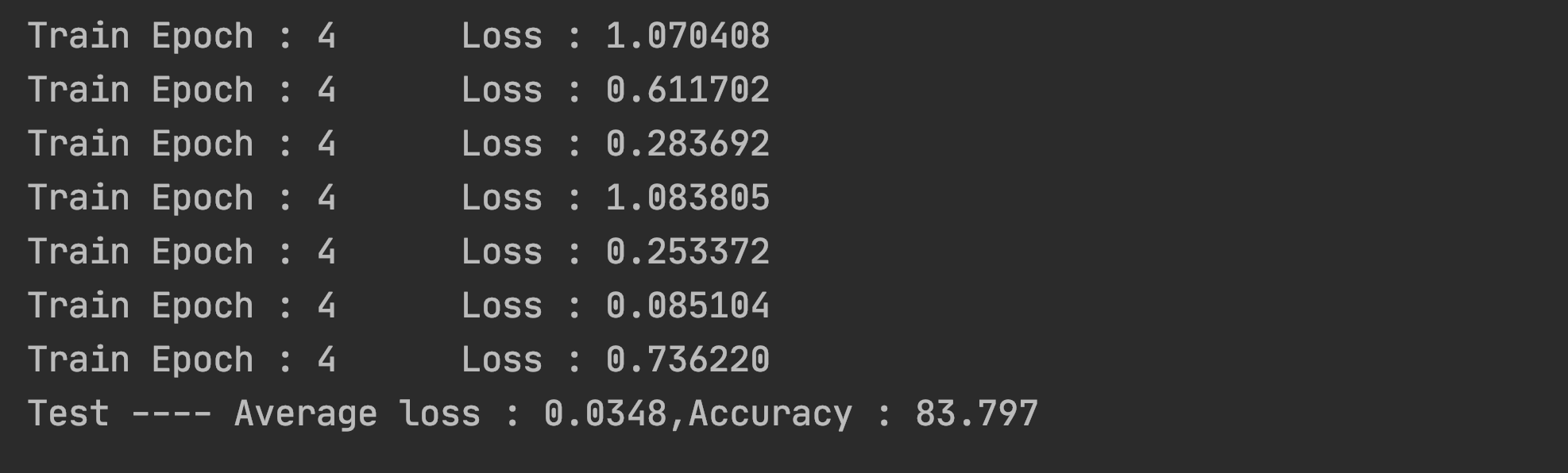
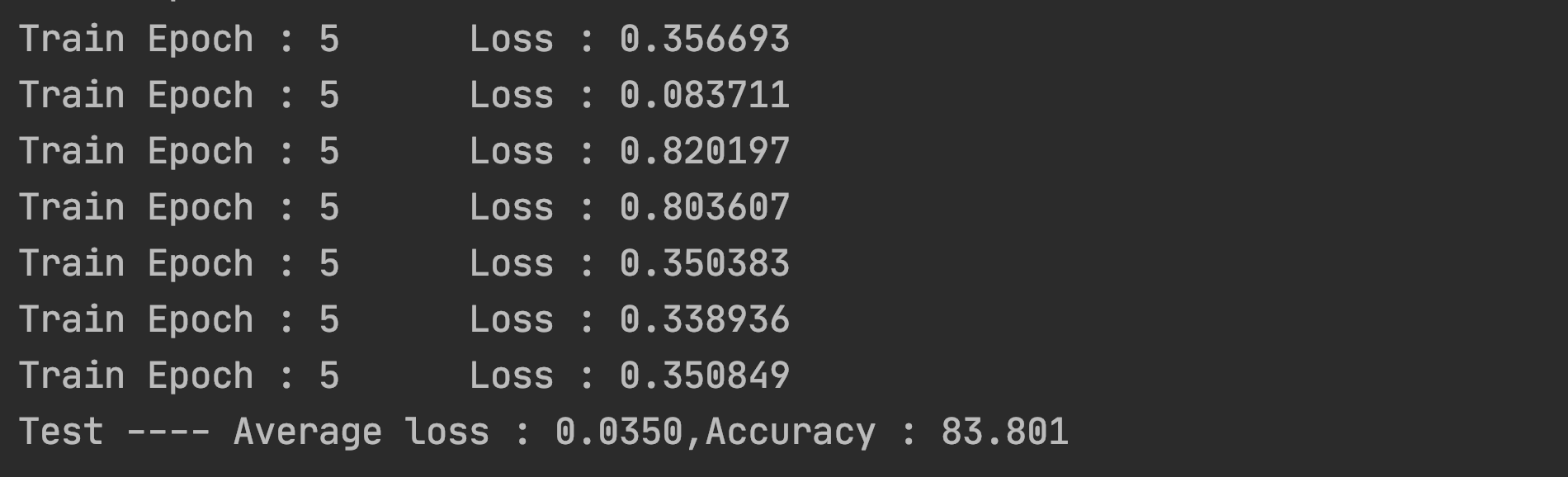
模型优化
1 | class SVHN_Net(nn.Module): |

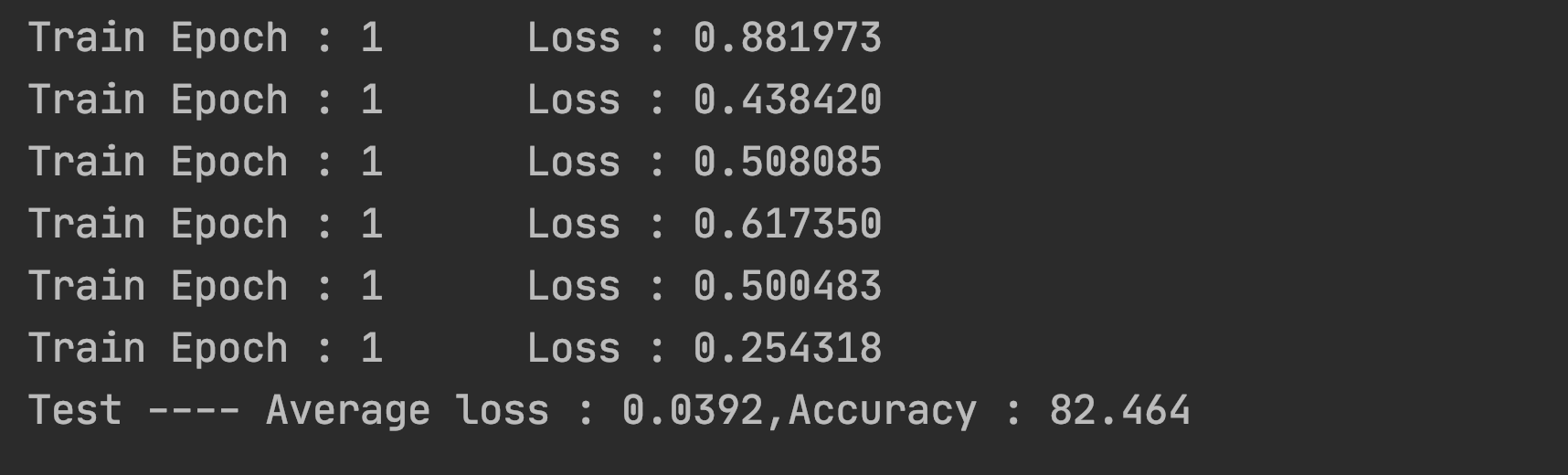
再次优化
1 | #准确率达93.4% |