自编码器介绍
自编码器主要是由编码器(Encoder)和解码器(Decoder)组成,它是一个试图去还原原始输入的一个系统。在深度学习中,自编码器是一种无监督的神经网络模型。它可以学习到输入数据的隐含特征,同时通过学习到的特征可以重构出原始数据。它类似于PCA,可以起到特征提取器的功能。
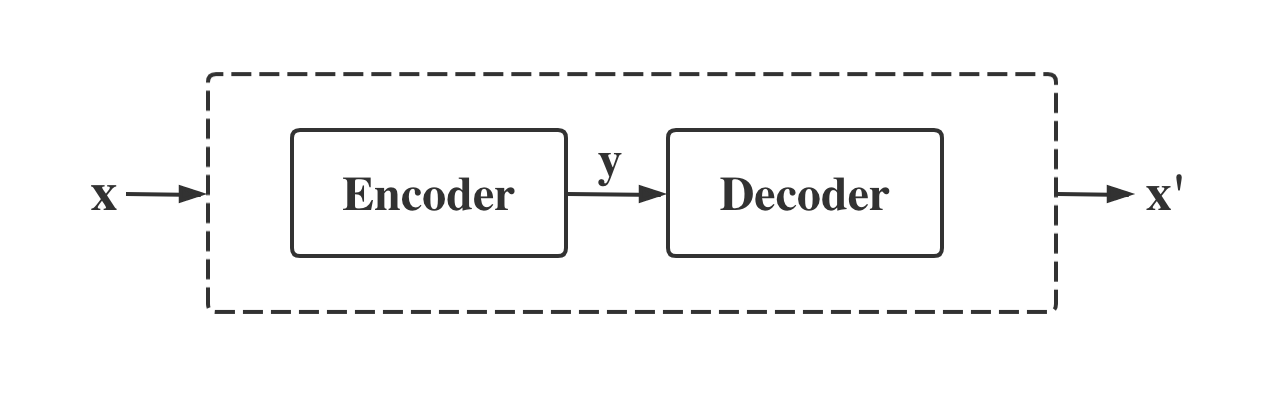
自编码器生成MNIST
导入相关模块
1 | import torch |
参数定义
1 | epochs = 10 |
建立文件夹保存数据
1 | if not os.path.exists("ae_img"): |
加载数据集
1 | mydataset = MNIST(root="./mnist_data/",train=True,download=True,transform=transforms) |
定义编码器网络
在这里编码器网络采用两个卷积层和一个全连接层。并进行了归一化处理,激活函数使用ReLU激活函数。
1 | class EncoderNet(nn.Module): |
定义解码器网络
解码器网络和编码器网络相反,拿到编码器的输出,通过一个全连接层放大维度,之后是通过两个逆卷积层扩大图像的尺寸,扩大到28*28和MNIST原始数据集尺寸大小相同。
1 | class DecoderNet(nn.Module): |
定义自编码器网络
1 | class Net(nn.Module): |
实例化模型
1 | model = Net() |
定义优化器和损失函数
损失函数我们这里使用的是均方损失函数,因为这里我们衡量的是真实图片和自编码器生成的图片的损失,采用均方差计算损失会好一些。
1 | optimizer = optim.Adam(model.parameters(),0.001) |
定义训练函数
在每一轮训练中加载训练数据集,并计算真实数据和生成数据的损失,之后进行梯度优化。并将真实图片和生成的图片保存在文件夹中。
1 | def train_model(model, train_loader,optimizer ,num_epochs): |
保存训练模型
1 | torch.save(model.state_dict(), "./params/model.pth") |
定义测试函数
1 | def test_model(model,test_loader,num_epochs): |
模型测试
1 | if __name__ == '__main__': |
数据展示
训练数据


测试数据

