前言
之前在Kaggle上看到了一个XSS的数据集,所以想着用pytorch实现一下,代码参考了kaggle上有人用keras实现的。
https://www.kaggle.com/syedsaqlainhussain/cross-site-scripting-attack-detection-using-cnn
XSS数据集介绍
数据集地址:https://www.kaggle.com/syedsaqlainhussain/cross-site-scripting-xss-dataset-for-deep-learning
数据是csv形式的,一共有三列,第一列是序号,第二列是具体的代码,第三列是标签。一共有13686条数据,没有分训练集和测试集,因此后面我们需要分一下。
思路分析
首先我们应该对数据进行编码。转换成向量的形式,对于训练集和测试集每一行数据,我们都有编码和标签两种数据,之后通过模型进行训练,训练结果与标签进行比对,计算损失,最后通过测试集进行验证。
模块导入
其中cv2是一个进行图像处理的库,sklearn是基于python的机器学习攻击。
1 | import numpy as np |
参数定义
1 | batch_size = 50 |
加载数据集
将XSS数据集下载之后,放在和代码同级的目录下。通过pandas模块可以实现对csv文件的读取等操作。
1 | df = pd.read_csv("XSS_dataset.csv",encoding="utf-8-sig") |
定义编码函数
对于一些编码后比较大的字符,可以为他们分配一个比较小的值,方便后续进行正则化。将每一条数据都通过一个长度为10000的向量进行存储。之后reshape成一个二维向量,大小是100*100
1 | def convert_to_ascii(sentence): |
编码转换
首先定一个数组,大小是数据集的长度,类型是一个二维向量,大小是100*100,之后对csv中每一条数据都进行编码转换,并将二维向量中的数据都转为float类型表示。之后得到的data就是对数据集编码后的结果。
1 | arr = np.zeros((len(sentences), 100, 100)) |
获取标签
1 | y=df['Label'].values |
划分数据集
采用train_test_split函数随机划分数据。其中test_size是指测试数据占样本数据的比例,这里取样本总数的20%作为测试数据,random_state是一个随机数种子。之后通过DataLoader函数设定训练批次大小和shuffle操作,这里需要注意的是,因为我们data和y中的数据都是ndarray类型的,因此我们还需要对他们进行类型转换,转为tensor类型。
1 | trainX, testX, trainY, testY = train_test_split(data,y, test_size=0.2, random_state=42) |
模型定义
1 | class CNN_XSS_Net(nn.Module): |
实例化模型
1 | model = CNN_XSS_Net() |
定义训练函数
1 | def train(model,trainX,trainY,optimizer,epochs): |
定义测试函数
1 | def test_model(model,testX,testY): |
模型训练
1 | for epoch in range(epochs): |
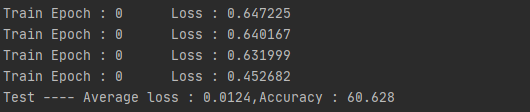
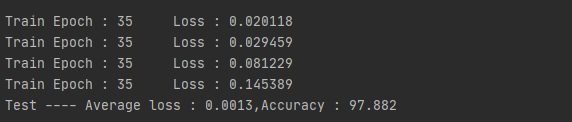
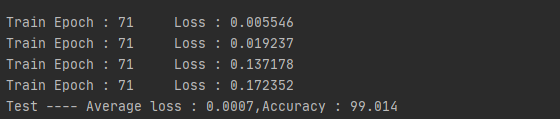
结果展示