前言
对于《Kubernetes in action》这本书前三章节相关的笔记,我都记录在下面这个链接了,有需求的可以看看。
http://elssm.top/2021/03/22/Docker-Kubernetes%E5%AD%A6%E4%B9%A0/
存活探针
Kubernetes可以通过存活探针(liveness probe)检查容器是否还在运行,可以为pod中的每个容器单独指定存活探针。如果探测失败,Kubernetes将定期执行探针并重新启动容器。
Kubernetes三种探测容器的机制
- HTTP GET探针对容器的IP地址执行HTTP GET请求。如果HTTP响应状态码事
2xx或3xx,则认为探测成功,如果服务器返回错误响应状态码或是没有收到响应,则认为探测事失败的,这个时候容器将会被重新启动。 - TCP套接字探针尝试与容器指定端口建立TCP连接,如果连接建立成功,则探测成功,否则,容器重新启动。
- Exec探针在容器内执行任意命令,并检查命令的退出状态码,如果状态码是0,则探测成功。所有其他的状态码都会被认为失败。
创建基于HTTP的存活探针
老规矩,先来创建一个名为kubia-liveness-probe.yaml的文件,该pod的描述文件定义了一个httpGet存活探针,该探针告诉Kubernetes定期在端口8080路径上执行HTTP GET请求,以确定该容器是否健康。
1 | apiVersion: v1 |
接下来使用kubectl create从YAML文件创建pod
1 | kubectl create -f kubia-liveness-probe.yaml |
大约过几分钟后,我们通过kubectl get可以看到,pod的容器已经被重启了一次,如果继续等下去,容器将会再次重启,无限循环。
1 | caoyifan@MacBookPro DockerTest % kubectl get pod kubia-liveness |
通过kubectl describe可以看到重启容器后的相关描述
1 | caoyifan@MacBookPro DockerTest % kubectl describe pod kubia-liveness |
从上述返回的结果中我们可以看到容器此时是正在运行着的,但之前由于Terminated而退出,退出代码为137,137表示该进程由外部信号中断,137是两个数字的总和:128+x,其中x是终止进程的信号编号,在这个例子中,x等于9,这是SIGKILL的信号编号,意味着这个进程被强行终止。
ReplicationController
ReplicationController介绍
ReplicationController是一种Kubernetes资源,可确保它的pod始终保持运行状态,如果pod因任何原因消失,则ReplicationController会注意到缺少了pod并创建替代pod。如下图所示,当节点出现故障时,只有ReplicationController管理的pod才能被重新创建。对于podA而言,则会完全丢失,因为没有东西负责重建它。
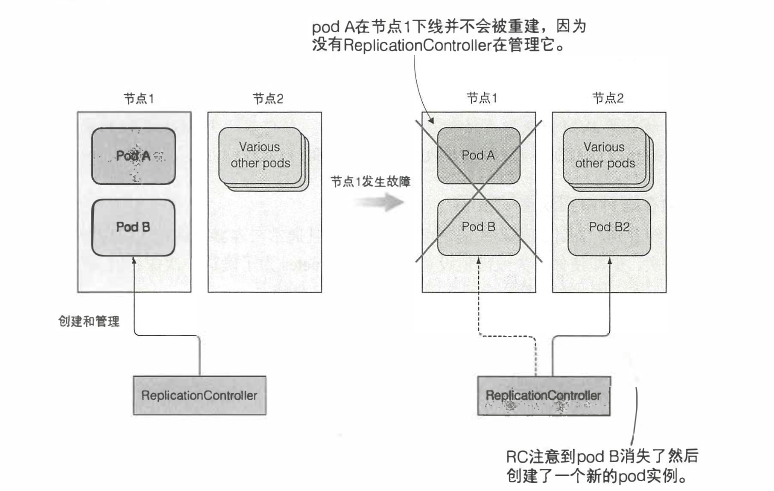
ReplicationController会持续监控正在运行的pod列表,并保证相应“类型”的pod的数目与期望相符,如果正在运行的pod太少,它会根据pod模版创建新的副本。如果正在运行的pod太多,它会删除多余的副本。
ReplicationController协调流程
ReplicationController的工作是确保pod的数量始终与其标签选择器匹配。 如果不匹配, 则ReplicationController将根据所需, 采取适当的操作来协调pod的数量。如下图是一个ReplicationController的协调流程
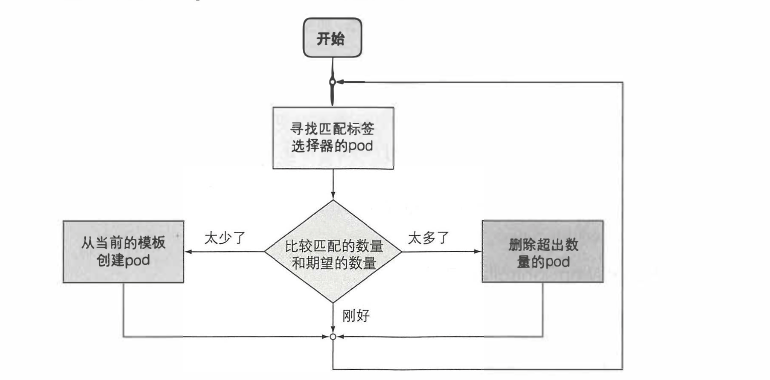
ReplicationController组成
- label selector(标签选择器):用于确定ReplicationController作用域中有哪些pod
- replica count(副本个数):指定应运行的pod数量
- pod template(pod模版):用于创建新的pod
创建ReplicationController
首先创建一个名为kubia-rc.yaml的YAML文件,代码描述如下。当上传文件道API服务器时,Kubernetes会创建一个名为kubia的ReplicationController,它确保符合标签选择器app=kubia的pod实例始终是三个,当没有足够的pod时,它根据提供的pod模版创建新的pod。
1 | apiVersion: v1 |
使用kubectl create命令创建
1 | kubectl create -f kubia-rc.yaml |
由于没有任何pod有app=kubia标签,因此ReplicationController会根据pod模版启动三个新的pod。使用kubectl get查看。
1 | caoyifan@MacBookPro DockerTest % kubectl get pods |
这个时候如果我们删除了一个pod,看看会发生什么。这个时候被删除的pod状态处于终止状态,而新的pod处于创建状态。
1 | caoyifan@MacBookPro ~ % kubectl get pods |
1 | caoyifan@MacBookPro DockerTest % kubectl get pods |
通过kubectl get查看ReplicationController的信息
1 | caoyifan@MacBookPro DockerTest % kubectl get rc |
通过kubectl describe查看ReplicationController详细信息
1 | caoyifan@MacBookPro DockerTest % kubectl describe rc kubia |
获取当前ReplicationController管理的pod的标签
1 | caoyifan@MacBookPro DockerTest % kubectl get pods --show-labels |
给ReplicationController管理的pod加标签,在这里我们给名为kubia-bcbz5的pod添加了一个type=special的标签
1 | kubectl label pod kubia-bcbz5 type=special |
这个时候我们再次查看pod的标签
1 | caoyifan@MacBookPro DockerTest % kubectl get pods --show-labels |
更改已托管的pod的标签,这里我们还是更改名为kubia-bcbz5的pod的标签,这一步操作会使得该pod不再与ReplicationController的标签选择器相匹配。因此这个时候ReplicationController会重新启动一个新的pod。在这里我们使用了--overwrite参数是为了覆盖标签。
1 | kubectl label pod kubia-bcbz5 app=foo --overwrite |
这个时候我们再次列出所有pod,会发现多了一个pod,最后一个是新创建出来的
1 | caoyifan@MacBookPro DockerTest % kubectl get pods -L app |
下图展示了当我们更改pod的标签时,ReplicationController发生的一些操作。
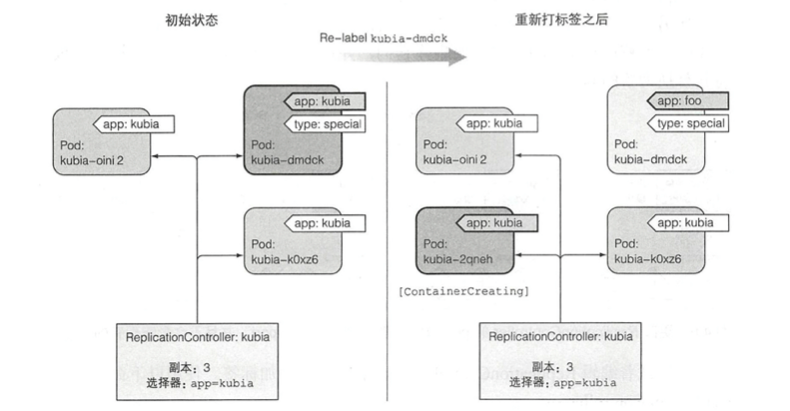
ReplicationController扩容
第一种方法
通过kubectl scale命令扩容
1 | kubectl scale rc kubia --replicas=10 |
第二种方法
通过编辑定义来扩容
1 | kubectl edit rc kubia |
之后将replicas的值从3改为10即可。再次使用kubectl get查看,发现扩展成功
1 | caoyifan@MacBookPro DockerTest % kubectl get rc |
删除ReplicationController
当使用kubectl delete删除ReplicationController时,pod也会被删除。当然我们也可以只删除ReplicationController,从而保持pod运行。通过增加--cascade=false选项来保持pod的运行。
1 | kubectl delete rc kubia --cascade=false |
ReplicaSet
ReplicaSet的行为和ReplicationController完全相同,但是pod选择器的表达能力更强
定义ReplicaSet
首先创建一个名为kubia-replicaset.yaml的YAML文件
这里需要注意的是ReplicaSet不是v1 API的一部分,它属于apps API组的v1版本。其次是在选择其中,不需要再selector属性中直接列出pod需要的标签,而是在selector.matchLabels下指定它们。
1 | apiVersion: apps/v1 |
在上一节的删除ReplicationController中,我们没有删除pod。因此在创建ReplicaSet的时候不会创建任何新的pod,ReplicaSet会把现有的三个pod归为自己来管理。
创建和检查ReplicaSet
1 | kubectl create -f kubia-replicaset.yaml |
使用kubectl get来获取当前的ReplicaSet
1 | kubectl get rs |
使用kubectl describe来检查当前的ReplicaSet
1 | kubectl describe rs |
这个时候如果我们使用kubectl get来列出当前的pod,则会发现还是之前的那三个pod,而ReplicaSet并没有创建新的pod
删除ReplicaSet
1 | kubectl delete rs kubia |
DaemonSet
DaemonSet确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet 的一些典型用法:
- 在每个节点上运行集群守护进程
- 在每个节点上运行日志收集守护进程
- 在每个节点上运行监控守护进程
一种简单的用法是为每种类型的守护进程在所有的节点上都启动一个 DaemonSet。 一个稍微复杂的用法是为同一种守护进程部署多个 DaemonSet;每个具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU要求。
DaemonSet将pod部署到集群中的所有节点上,除非指定这些pod只在部分节点上运行,这是通过pod模版中的nodeSelector属性指定的,这是DaemonSet定义的一部分。
一个例子
假设有一个名为ssd-monitor的守护进程,它需要在包含固态驱动器(SSD)的所有节点上运行,我们需要创建一个DaemonSet,它在标记为具有SSD的所有节点上运行这个守护进程,如下图所示
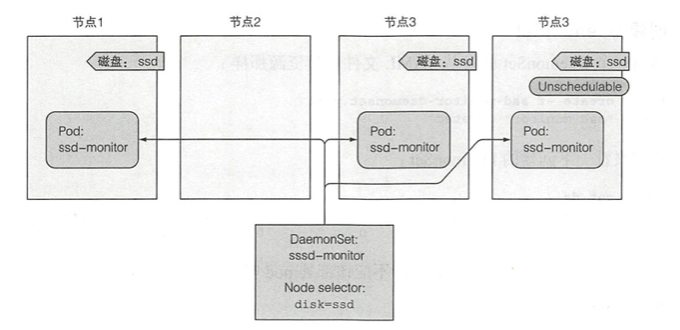
第一步还是创建一个DaemonSet的YAML文件,这样会创建一个运行ssd-monitor监控器进程的DaemonSet,该进程每5s会将”SSD OK”打印到标准输出。YAML文件名为ssd-monitor-daemonset.yaml
1 | apiVersion: v1 |
通过kubectl create创建DaemonSet
1 | kubectl create -f ssd-monitor-daemonset.yaml |
通过kubectl get查看DaemonSet
1 | kubectl get ds |
这个时候我们获取pod信息发现没有pod相关信息,这是因为我们没有给节点打上disk=ssd的标签,和上面那个图描述的一样,如果节点没有disk=ssd这个标签,则DaemonSet不会为该节点部署pod,因此我们需要为节点添加标签,这里我使用的节点为docker-desktop,当然你也可以通过kubectl get node获取你的节点信息。
现在给节点添加disk=ssd标签
1 | kubectl label node docker-desktop disk=ssd |
查看是否成功为节点打上标签
1 | caoyifan@MacBookPro DockerTest % kubectl get node --show-labels |
现在重新获取节点信息
1 | caoyifan@MacBookPro DockerTest % kubectl get pods |
假如说这个时候我们修改了节点的标签,看看会发生什么,如下面命令所示,我们将disk=ssd改为了disk=hdd
1 | kubectl label node docker-desktop disk=hdd --overwrite |
这个时候我们再次查看pod,发现pod正在被终止
1 | caoyifan@MacBookPro DockerTest % kubectl get pods |
删除节点标签,如果我们要删除某个节点的标签,命令如下,其中disk为标签的键,后面的减号代表删除该标签
1 | kubectl label node docker-desktop disk- |
Job
Job 会创建一个或者多个 Pods,并将继续重试 Pods 的执行,直到指定数量的 Pods 成功终止。 随着 Pods 成功结束,Job 跟踪记录成功完成的 Pods 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。 删除 Job 的操作会清除所创建的全部 Pods。 挂起 Job 的操作会删除 Job 的所有活跃 Pod,直到 Job 被再次恢复执行。
一种简单的使用场景下,你会创建一个 Job 对象以便以一种可靠的方式运行某 Pod 直到完成。 当第一个 Pod 失败或者被删除(比如因为节点硬件失效或者重启)时,Job 对象会启动一个新的 Pod。
你也可以使用 Job 以并行的方式运行多个 Pod。
定义Job资源
老规矩,还是创建一个名为exporter.yaml的YAML文件。该文件定义了一个Job类型的资源,它将运行luksa/batch-job镜像,该镜像调用一个运行120秒的进程,然后退出。在pod配置的属性restartPolicy默认为Always,然而Job pod不能使用默认策略,因为它们不是要无限期的运行下去,因此需要明确指定restartPolicy为OnFailure还是Never,这一设置防止容器在完成任务时重新启动。
1 | apiVersion: batch/v1 |
创建该job
1 | kubectl create -f exporter.yaml |
获取job信息
1 | caoyifan@MacBookPro DockerTest % kubectl get jobs |
获取pod信息
1 | caoyifan@MacBookPro DockerTest % kubectl get pods |
两分钟之后,我们再次获取pod信息,会发现该pod的状态被标记为已完成。
1 | caoyifan@MacBookPro DockerTest % kubectl get pods |
pod完成后并没有被删除,这样方便我们查阅该pod 的日志,如下命令所示
1 | caoyifan@MacBookPro DockerTest % kubectl logs batch-job-q8c44 |
在Job中运行多个pod实例
顺序运行:设置completions的值为多少,该job就会创建多少个pod,然后顺序运行。
并行运行:设置parallelism的值为多少,该job就会一次并行运行多少个pod,并行运行中也要设置completions的值
限制job pod完成任务的时间
通过在pod配置中设置activeDeadlineSeconds属性,可以限制pod的时间,如果pod运行时间超过此时间,系统将尝试终止pod,并将Job标记为失败。
服务
Kubernetes服务是一种为一组功能相同的pod提供单一不变的接入点的资源。当服务存在时,它的IP地址和端口不会改变,客户端通过IP地址和端口号建立连接,这些连接会被路由到提供该服务的任意一个pod上,通过这种方式,客户端不需要知道每个单独的提供服务的pod的地址,这样这些pod就可以在集群中随时被创建或移除。如下图展示的是一个客户端访问前端,前端访问后端服务的例子。
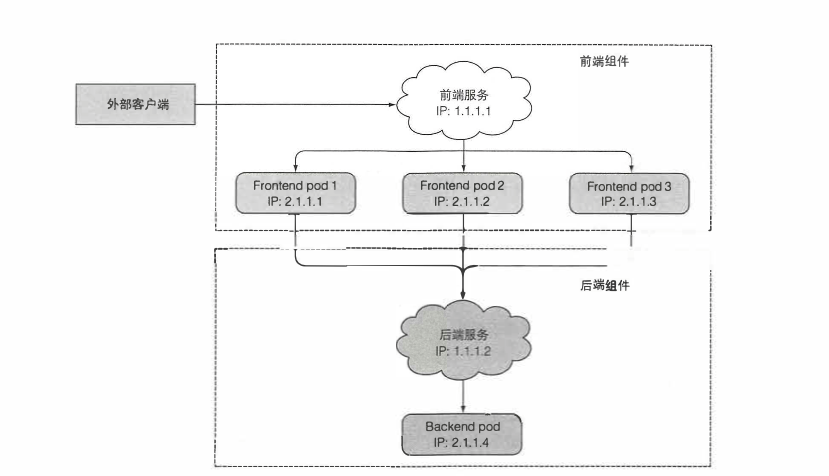
创建服务
在创建服务之前,我们先通过创建ReplicationController运行三个包含Node.js应用的pod。还是使用的是之前创建的kubia-rc.yaml文件
1 | kubectl create -f kubia-rc.yaml |
通过kubectl get命令检测pod是否成功启动,并查看这三个pod的标签
1 | caoyifan@MacBookPro DockerTest % kubectl get pods --show-labels |
这个时候通过YAML描述文件来创建服务,该YAML文件的名为kubia-svc.yaml
1 | apiVersion: v1 |
通过kubectl create发布文件创建服务
1 | kubectl create -f kubia-svc.yaml |
列出所有的服务资源,如下命令,可以看到第二个是我们创建的服务
1 | caoyifan@MacBookPro DockerTest % kubectl get svc |
从内部集群测试服务
- 创建一个pod,它将请求发送到服务的集群IP并记录响应,可以通过查看pod日志检查服务的响应。
- 使用ssh远程登录到其中一个Kubernetes节点上,然后使用curl命令。
- 可以通过
kubectl exec命令在一个已经存在的pod中执行curl命令。
我们使用最后一种方式来进行测试
1 | caoyifan@MacBookPro DockerTest % kubectl exec kubia-hvlfd -- curl -s http://10.111.239.153 |
我们来解释一下上述命令执行了哪些操作。首先是在一个pod容器上,利用Kubernetes去执行curl命令,curl命令向一个后端有三个pod服务的IP发送了HTTP请求,这个时候Kubernetes服务代理拦截该连接,在三个pod中任意选择了一个pod,然后将请求转发给它。Node.js在pod中运行处理请求,并返回带有pod名称的HTTP响应,接着curl命令向标准输出打印返回值,该返回值被kubectl截取并打印到主机的标准输出。
服务发现
Kubernetes还为客户端提供了发现服务的IP和端口的方式
通过环境变量发现服务
1 | caoyifan@MacBookPro DockerTest % kubectl exec kubia-695cf env |
通过DNS发现服务
运行一个DNS服务的pod,在集群中的其他pod都被配置成使用其作为DNS,运行在pod上的进程DNS查询都会被Kubernetes自身的DNS服务器响应,该服务器知道系统中运行的所有服务。
将服务暴露给外部客户端
- 将服务的类型设置成
NodePort:每个集群节点都会在节点上打开一个端口,对于NodePort服务,每个集群节点在节点本身上打开一个端口,并将在该端口上接收到的流量重定向到基础服务,该服务仅在内部集群IP和端口上才能访问,但也可通过所有节点上的专用端口访问。 - 将服务的类型设置成
LoadBalance:这是NodePort类型的一种扩展,这使得服务可以通过一个专用的负载均衡器来访问,这是由Kubernetes中正在运行的云基础设施提供的,负载均衡器将流量重定向到跨所有节点的节点端口,客户端通过负载均衡器的IP连接到服务。 - 创建一个Ingress资源:这是一个完全不同的机制,通过一个IP地址公开多个服务,它运行在HTTP层,因此可以提供比工作在第四层的服务更多的功能。
创建NodePort类型的服务
创建一个名为kubia-svc-nodeport.yaml的YAML文件
1 | apiVersion: v1 |
创建该服务
1 | kubectl create -f kubia-svc-nodeport.yaml |
查看该服务的基础信息
1 | caoyifan@MacBookPro ~ % kubectl get svc kubia-nodeport |
因为我是通过Docker-desktop for mac在本地搭建环境,所以可以通过localhost:30123进行访问
1 | caoyifan@MacBookPro ~ % curl localhost:30123 |
如下图显示了服务暴露在两个集群节点的端口30123上。到达任何一个端口的传入连接将被重定向到一个随机选择的pod,该pod是否位于接收到连接的节点上是不确定的。
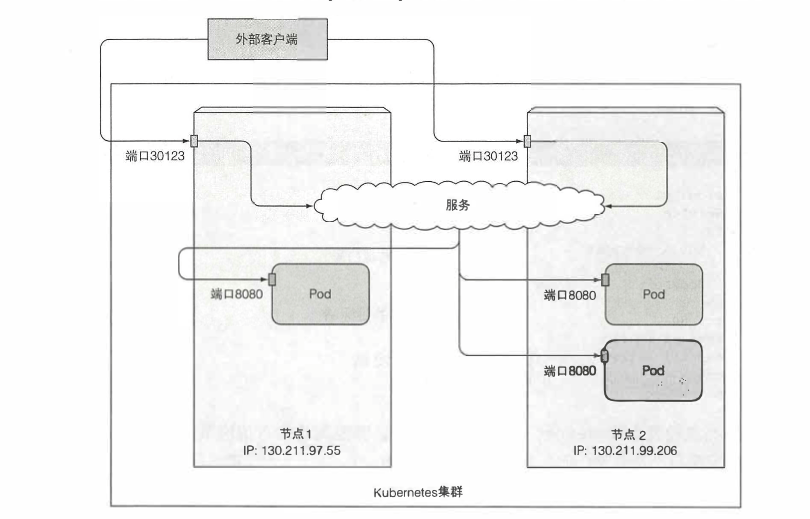
创建LoadBalance服务
创建一个名为kubia-svc-loadbalancer.yaml的YAML文件
1 | apiVersion: v1 |
创建该服务
1 | kubectl create -f kubia-svc-loadbalancer.yaml |
如下图所示为外部客户端连接一个LoadBalancer服务
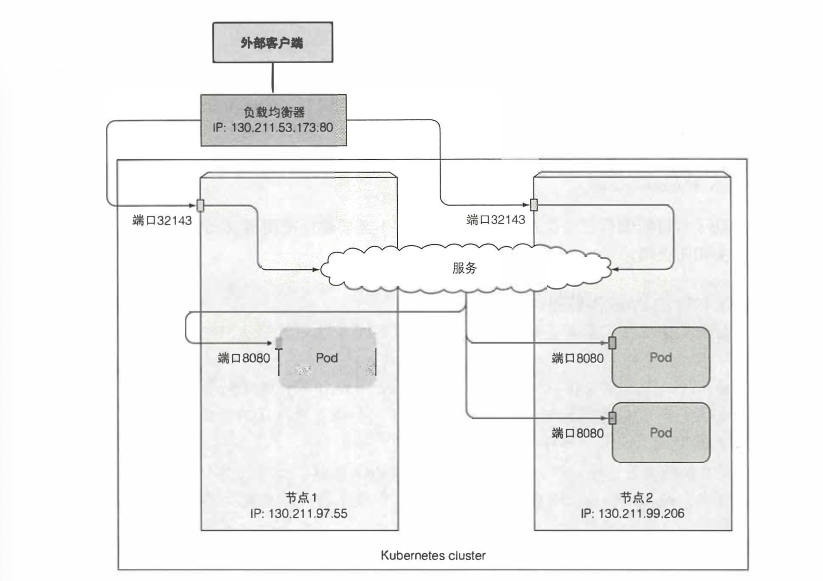
就绪探针
就绪探测器会定期调用,并确定特定的pod是否接受客户端的请求,当容器的准备就绪探测返回成功时,表示容器已经准备好接收请求。
就绪探针类型
- Exec探针,执行进程的地方。容器的状态由进程的退出状态代码确定
- HTTP GET探针,向容器发送HTTP GET请求,通过响应的HTTP状态码判断容器是否准备好
- TCP socket探针,打开一个TCP连接到容器的指定端口,如果连接已建立,则认为容器已准备就绪
卷
Kubernetes的卷时pod的一个组成部分,因此像容器一样在pod的规范中就定义了,它们不是独立的Kubernetes对象,也不能单出创建或删除,pod中的所有容器都可以使用卷,但必须先将它挂载在每个需要访问它的容器中,在每个容器中,都可以在其文件系统的任意位置挂载卷。
卷类型
- emptyDir:用于存储临时数据的简单空目录
- hostPath:用于将目录从工作节点的文件系统挂载到pod中
- gitRepo:通过检出Git仓库的内容来初始化的卷
- nfs:挂载到pod中的NFS共享卷
- gcePersistentDisk:Google高效能型存储磁盘卷
- cinder、cephfs、iscsi、flocker、glusterfs、quobyte、rbd、flexVolume、vsphere-Volume、photonPersistentDisk、scaleIO用于挂载其他类型的网络存储
- configMap、secret、downwordAPI:用于将Kubernetes部分资源和集群信息公开给pod的特殊类型的卷
- persistentVolumeClaim:一种使用预置或者动态配置的持久存储类型
在pod中使用emptyDir卷
现在有两个镜像需要运行在pod上,首先创建一个名为fortune-pod.yaml的文件。
1 | apiVersion: v1 |
pod包含两个容器和一个挂载在两个容器中的共用的卷,但在不同的路径上。当html-generator容器启动时,它每10秒启动一次fortune命令输出到var/htdocs/index.html文件,因为卷是在/var/htdocs上挂载的,所以index.html文件被写入卷中,而不是容器的顶层,一旦web-server容器启动,他就开始为/usr/share/nginx/html目录中的任意HTML文件提供服务,因为我们将卷挂载在那个确切的位置,Nginx将为运行fortune循环的容器输出的index.html文件提供服务,最终的效果是,一个客户端向pod上的80端口发送一个HTTP请求,将接收当前的fortune消息作为响应。
为了查看fortune消息,需要启动对pod的访问,可以尝试将端口从本地机器转发到pod来实现
1 | caoyifan@MacBookPro DockerTest % kubectl port-forward fortune 8080:80 |
使用curl命令访问Nginx服务器
1 | caoyifan@MacBookPro ~ % curl localhost:8080 |