前言
最近因为一些原因开始学习eBPF,后续也将持续学习eBPF的一些具体应用。
BPF发展史
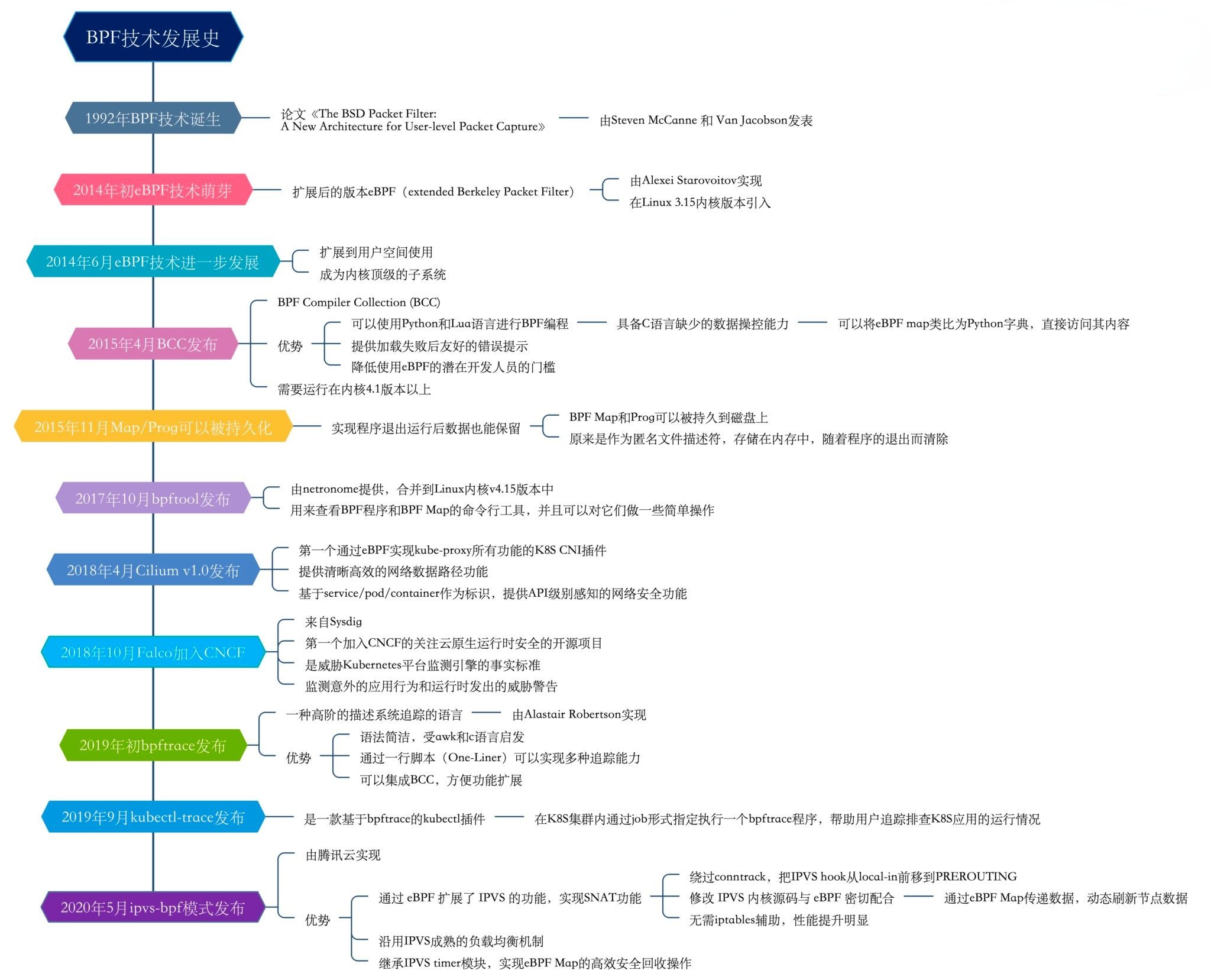
BPF介绍
BPF(伯克利包过滤器),也称为cBPF,在1992年提出,目的是为了提供一种过滤包的方法,并且要避免从内核空间到用户空间的无用的数据包复制行为。最初,BPF是在BSD内核实现的, 后来,由于其出色的设计思想,其他操作系统也将其引入, 包括Linux。
BPF架构如下图所示,从图中可以看到,BPF是作为内核报文传输路径的一个旁路存在,当报文到达内核驱动程序后,内核在将报文上送协议栈的同时,会额外将报文的副本交给BPF,之后报文会经过BPF内部逻辑的过滤。
eBPF介绍
eBPF是扩展的BPF,2014 年初,Alexei Starovoitov 实现了 eBPF(extended Berkeley Packet Filter)。经过重新设计,eBPF 演进为一个通用执行引擎,可基于此开发性能分析工具、软件定义网络等诸多场景。eBPF 最早出现在 3.18 内核中,此后原来的 BPF 就被称为经典 BPF,缩写 cBPF(classic BPF),cBPF 现在已经基本废弃。现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。
从eBPF官网摘录下段文字说明
eBPF is a revolutionary technology with origins in the Linux kernel that can run sandboxed programs in an operating system kernel. It is used to safely and efficiently extend the capabilities of the kernel without requiring to change kernel source code or load kernel modules.(一项革新性技术!!!有苹果发布会内味。起源于Linux内核,可以在操作系统内核中运行沙箱程序,被用来安全的扩展内核功能,不用去更改内核源码或加载内核模块)
Historically, the operating system has always been an ideal place to implement observability, security, and networking functionality due to the kernel’s privileged ability to oversee and control the entire system. At the same time, an operating system kernel is hard to evolve due to its central role and high requirement towards stability and security. The rate of innovation at the operating system level has thus traditionally been lower compared to functionality implemented outside of the operating system.(操作系统一直是实现可观测性、安全性和网络功能的最佳场所,因为内核具有监视和控制整个系统的权限。同时,由于其核心作用和对于稳定性和安全性的高要求,使得它很难进化。因此,和在操作系统之外实现的功能相比,操作系统级别的创新率就会偏低)
eBPF changes this formula fundamentally. By allowing to run sandboxed programs within the operating system, application developers can run eBPF programs to add additional capabilities to the operating system at runtime. The operating system then guarantees safety and execution efficiency as if natively compiled with the aid of a Just-In-Time (JIT) compiler and verification engine. This has led to a wave of eBPF-based projects covering a wide array of use cases, including next-generation networking, observability, and security functionality.(eBPF从根本上改变了这个功能,通过允许在操作系统内运行沙箱程序,应用开发者可以通过运行eBPF程序在操作系统运行时添加额外功能。操作系统会保证安全性和执行效率,就像在JIT编译器和验证器的帮助下进行本机编译一样。接着就出现了一系列基于eBPF的项目,例如下一代网络、可观察性和安全功能等)
Today, eBPF is used extensively to drive a wide variety of use cases: Providing high-performance networking and load-balancing in modern data centers and cloud native environments, extracting fine-grained security observability data at low overhead, helping application developers trace applications, providing insights for performance troubleshooting, preventive application and container runtime security enforcement, and much more. The possibilities are endless, and the innovation that eBPF is unlocked has only just begun.(今天,eBPF被用于驱动各种各样的用例,例如在数据中心和云本机环境提供高性能网络和负载均衡、以较低的开销提取细粒度安全可观测性数据、帮助应用程序开发人员跟踪应用程序、为性能故障排除提供一些方法,预防应用程序和容器运行时的安全实施等等,eBPF有无限可能,eBPF才刚刚开始)
eBPF对比cBPF
eBPF相对于cBPF的增强如下:
- 处理器原生指令集建模,因此更接近底层处理器架构, 性能相比cBPF提升4倍
- 指令集从33个扩展到了114多个,依然保持了足够的简洁
- 寄存器从2个32位寄存器扩展到了11个 64 位的寄存器 (其中1个只读的栈指针)
- 引入 bpf_call 指令和寄存器传参约定,实现零(额外)开销内核函数调用
- 虚拟机的最大栈空间是 512 字节(cBPF 为 16 个字节)
- 引入了 map 结构,用于用户空间程序与内核中的 eBPF 程序数据交换
- 最大指令数初期为 4096,现在已经将这个限制放大到了100万条
eBPF工作机制
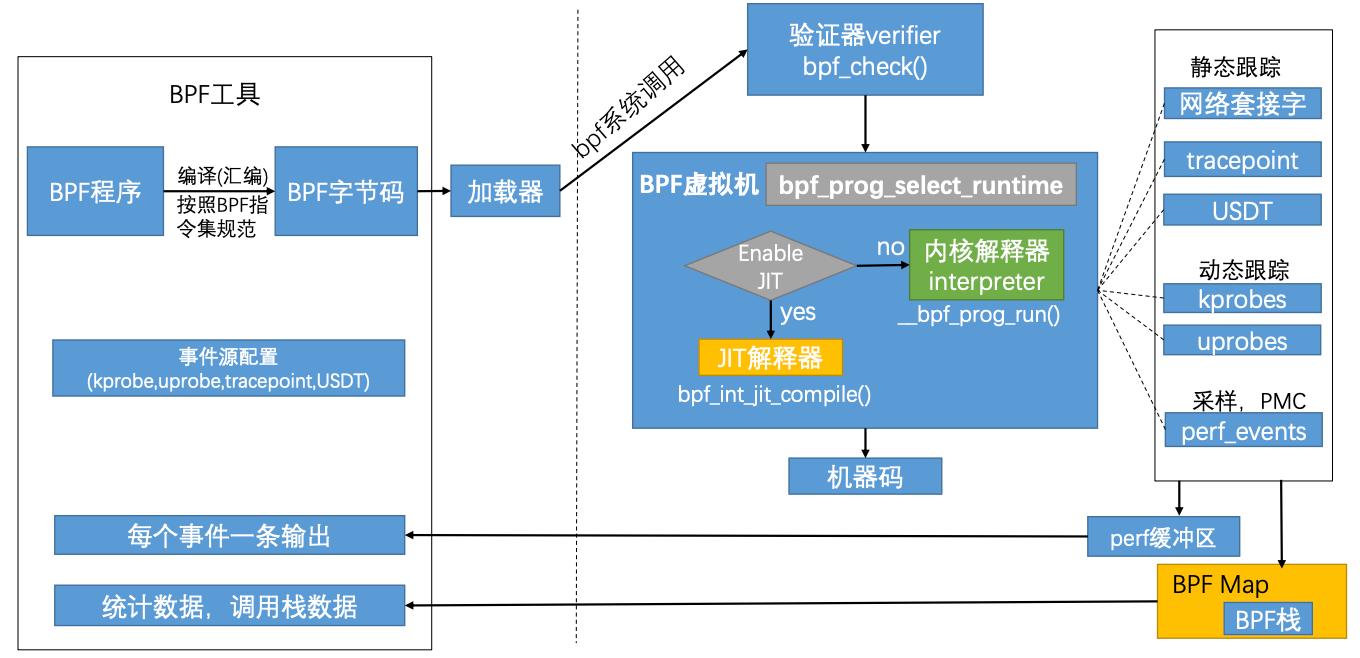
eBPF分为用户空间和内核空间,用户空间和内核空间的交互有两种方式
- BPF map:用于将内核中实现的统计摘要信息(比如测量延迟、堆栈信息)等回传至用户空间
- perf-event:用于将内核采集的事件实时发送至用户空间,用户空间程序实时读取分析
eBPF的工作逻辑是
- BPF程序通过
LLVM/Clang编译成eBPF定义的字节码prog.bpf - 通过bpf系统调用将bpf字节码指令传入内核
- 经过验证器检验字节码的安全性
- 加载eBPF程序的进程具有所需的权限,除非启用了非特权eBPF,否则只有特权进程才能加载eBPF程序
- 程序不会崩溃或以其它方式损坏系统
- 程序始终可以运行完成
- 在确认字节码安全后将其加载对应的内核模块执行,在BPF虚拟机中会判断是否开启JIT(即时编译),如果开启了JIT,则会通过JIT解释器将程序字节码转为特定的机器码执行,如果没有开启JIT,则通过内核解释器执行
eBPF观测技术相关的程序类型有kprobes、uporbes、tracepoint、perf_event
- kprobes:实现内核中动态跟踪。kprobes可以跟踪到Linux内核中的函数入口或返回点,但是不是稳定ABI接口,可能会因为内核版本变化导致,导致跟踪失效。理论上可以跟踪到所有导出的符号
/proc/kallsyms。 - uprobes:用户级别的动态跟踪。与kprobes类似,只是跟踪的函数为用户程序中的函数。
- tracepoints:内核中静态跟踪。tracepoints是内核开发人员维护的跟踪点,能够提供稳定的ABI接口,但是由于是研发人员维护,数量和场景可能受限。
- perf_events:定时采样和PMC。
eBPF使用场景
- 系统性能监控/分析工具:能够实现性能监控工具、分析工具等常用的系统分析工具,比如 sysstate 工具集,里面提供了 vmstate,pidstat 等多种工具,一些常用的 top、netstat(netstat 可被 SS 替换掉),uptime、iostat 等这些工具多数都是从 /proc、/sys、/dev 中获取的会对系统产生一定的开销,不适合频繁的调用。比如在使用 top 的时候通过 cpu 排序可以看到 top cpu 占用也是挺高的,使用 eBPF 可以在开销相对小的情况下获取系统信息,定时将 eBPF 采集的数据 copy 到用户态,然后将其发送到分析监控平台。
- 用户程序活体分析:做用户程序活体分析,比如 openresty 中 lua 火焰图绘制,程序内存使用监控,cdn 服务异常请求分析,程序运行状态的查看,这些操作都可以在程序无感的情况下做到,可以有效提供服务质量。
- 防御攻击:比如 DDoS 攻击,DDoS 攻击主要是在第七层、第三层以及第四层。第七层的攻击如 http 攻击,需要应用服务这边处理。第四层攻击,如 tcp syn 可以通过 iptable 拒绝异常的 ip,当然前提是能发现以及难点是如何区分正常流量和攻击流量,简单的防攻击会导致一些误伤,另外 tcp syn 也可以通过内核参数保护应用服务。第 3 层攻击,如 icmp。对于攻击一般会通过一些特殊的途径去发现攻击,而攻击的防御则可以通过 XDP 直接在网络包未到网络栈之前就处理掉,性能非常的优秀。
- 流控:可以控制网络传输速率,比如 tc。
- 替换 iptable:在 k8s 中iptable的规则往往会相当庞大,而iptable规则越多,性能也越差,使用eBPF就可以解决
- 服务调优:在cdn服务中难免会出现一些指标突刺的情况,这种突刺拉高整体的指标,对于这种突刺时常会因为找不到切入点而无从下手,eBPF存在这种潜力能帮助分析解决该问题,当eBPF发现网络抖动,会主动采集当时应用的运行状态。
eBPF hooks
eBPF hooks即eBPF钩子,指的是在内核中哪些地方可以加载eBPF程序,在目前的Linux内核中已经有近10中钩子
1 | kernel functions(kprobes) |
eBPF Map
在eBPF中可以利用map在eBPF程序调用之间保存状态信息,也可以利用map在用户态程序和内核之间共享数据等。内核提供了一个系统调用bpf(),以让用户态程序可以根据使用场景来创建合适的map。这个系统调用会返回一个关联了这个map对象的文件描述符,后续用户态程序可以用这个文件描述符来对相应的map对象进行一些操作,如查询、更新和删除,这部分的接口在tools/lib/bpf/bpf.h中定义了。关于这个bpf()系统调用以及map操作接口的详细信息,可以参考相关资料,其中bpf()系统调用相关的信息可以在man page中找到,而map操作相关的接口可以在 tools/lib/bpf/bpf.h 中看到具体的实现。
eBPF支持的map类型如下
1 | BPF_MAP_TYPE_HASH:哈希表 |
eBPF Helper Function
eBPF程序不能调用任意内核函数。如果允许这样做,会将eBPF程序绑定到特定的内核版本,并且会使程序的兼容性复杂化。相反,eBPF程序可以对helper函数进行函数调用,helper函数是内核提供的一种稳定的API。

一些可用于辅助调用的例子有
- 生成随机数
- 获取当前时间和日期
- eBPF map访问
- 获取进程/cgroup上下文
- 操作网络数据包和转发逻辑
BCC
bcc介绍
源码地址:https://github.com/iovisor/bcc
BCC工具全称BPF Compiler Collection (BCC),是一个很强大的库,强大的内核分析工具eBPF就是基于bcc开发的,利用这个库可以从底层获取操作系统性能信息,网络性能信息等许多与内核交互的信息。bcc使得bpf程序更容易被书写,bcc使用 Python和Lua,虽然核心依旧是一部分C语言代码(BPF C代码)。但是我们很快就可以体验了,这比手动安装 C 语言依赖、编译、插入内核要方便的多。
bcc-tools安装
1 | sudo yum -y install bcc-tools |
HelloWorld
代码如下
1 | from bcc import BPF |
执行如下
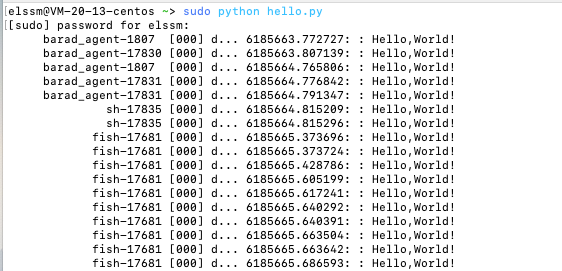
分析如下
text定义了一个嵌入的用C语言写的BPF程序
kprobe__sys_clone()是一个通过内核探针(kprobe)进行内核动态跟踪的快捷方式。如果一个C函数名开头为kprobe__,则后面部分实际为设备的内核函数名,这里是sys_clone()bpf_trace_printk()用于printf()到trace_pipe。一般用来快速调试return 0用来关闭凭证.trace_print(),一个bcc实例会通过这个读取trace_pipe并打印
利用eBPF提升socket性能
实验介绍
本实验主要是利用ebpf sockmap/redirection来提升socket的性能。sockmap是 eBPF 提供的一个特殊的eBPF MAP类型,主要用于socket redirection,在 socket redirection中,socket被添加到sockmap中并由key(主要是四元组)引用,然后该 socket 在调用bpf_sockmap_redirect()时进行重定向。对于本地通信方式而言,这样可以绕过整个 TCP/IP 协议栈,直接将数据发送到 socket 对端,从而提高性能。
实验代码
https://github.com/cyralinc/os-eBPF
实验环境
- Ubuntu Linux 18.04 with 5.3.0-40-generic
实验准备
安装相应包
- sudo apt-get install -y make gcc libssl-dev bc libelf-dev libcap-dev clang gcc-multilib llvm libncurses5-dev git pkg-config libmnl-dev bison flex graphviz
- sudo apt-get install iproute2
- sudo apt install libbfd-dev libcap-dev zlib1g-dev libelf-dev libssl-dev
修改apt源
https://blog.csdn.net/weixin_44143222/article/details/88592193
1 | apt-get source linux-image-$(uname -r) |
或直接下载对应源码
编译 bpftool 工具
1 | cd linux-5.3/tools/bpf/bpftool |
编译bpf字节码
1 | root@ubuntu:~/os-eBPF/sockredir$ clang -O2 -g -target bpf -I /usr/include/linux/ -I /usr/src/linux-headers-5.3.0-40/include/ -c bpf_sockops_v4.c -o bpf_sockops_v4.o |
加载bpf字节码
1 | root@ubuntu:~/os-eBPF/sockredir$ sudo bpftool prog load bpf_sockops_v4.o "/sys/fs/bpf/bpf_sockops" |
查看系统中已经加载的所有 BPF 程序
1 | root@ubuntu:~/os-eBPF/sockredir$ sudo bpftool prog show |
查看系统中所有的 map
1 | root@ubuntu:~/os-eBPF/sockredir$ sudo bpftool map show |
查看map的详情
1 | root@ubuntu:~$ sudo bpftool -p map show id 14 |
打印map中的内容
1 | root@ubuntu:~$ sudo bpftool -p map dump id 14 |
具体测试步骤
执行load.sh脚本
这里需要根据内核版本对应修改一下load.sh中的代码,如下图所示
执行结果如下
1 | root@ubuntu:~/os-eBPF/sockredir$ ./load.sh |
确认BPF程序已经被加载进内核
1 | root@ubuntu:~/os-eBPF/sockredir$ sudo bpftool prog show |
查看固定在文件系统上的SOCKHASH映射
1 | root@ubuntu:~/os-eBPF/sockredir$ sudo tree /sys/fs/bpf/ |
1 | root@ubuntu:~/os-eBPF/sockredir$ sudo bpftool map show id 42 -f |
确认应用程序绕过TCP/IP协议栈
首先打开日志追踪
root模式下执行如下命令
1 | root@ubuntu:~/os-eBPF/sockredir# echo 1 > /sys/kernel/debug/tracing/tracing_on |
接着在shell中对内核实时流跟踪文件trace_pipe进行cat查询,用来监视通过eBPF的TCP通信
1 | root@ubuntu:~/os-eBPF/sockredir# cat /sys/kernel/debug/tracing/trace_pipe |
使用socat生成的TCP监听器模拟echo服务器,并使用nc发送连接请求
1 | root@ubuntu:~$ sudo socat TCP4-LISTEN:9999,fork exec:cat |
随后我们就可以在内核追踪管道中看到在eBPF程序打印的日志
1 | root@ubuntu:~/os-eBPF/sockredir# cat /sys/kernel/debug/tracing/trace_pipe |
代码步骤梳理
bpf_sockops_v4.c- 监听
socket事件,当事件触发的时候执行 - 提取 socket 信息,并以 key & value 形式存储到 sockmap
- 监听
bpf_tcpip_bypass.c- 拦截所有的
sendmsg系统调用,从消息中提取 key - 根据key查询sockmap,找到这个socket的对端,然后绕过 TCP/IP 协议栈,将数据重定向
- 拦截所有的
网络延迟测试
使用netperf命令,执行时长参数为60秒的各种请求和响应消息大小,进行延迟测量(分别采用p50、p90 和 p99,其中P50表示中位数。P90表示包含90%的值。P99表示包含99%的值。):
1 | root@ubuntu:~$ netserver -p 1000 |
这里是因为端口被占用的问题,我们换一个端口即可
1 | root@ubuntu:~$ sudo netserver -p 9998 |
执行nperf_latency.sh
1 | root@ubuntu:~/os-eBPF/sockredir# ./nperf_latency.sh |
查看结果
其中第一行和第三行是原生TCP的网络延迟,第二行和第四行是eBPF重定向之后的网络延迟
1 | root@ubuntu:~/os-eBPF/sockredir$ cat result_lat.txt |
网络事务测试
使用netperf命令来测试60秒运行的各种请求和响应消息大小的事务率:
1 | root@ubuntu:~/os-eBPF/sockredir$ ./nperf_trans.sh |
查看结果
第一行为原生TCP的事务率,第二行是eBPF重定向之后的事务率
1 | Req/Resp size: 64 128 |
网络吞吐测试
使用netserver服务端和netperf客户端进行60秒的各种发送消息大小的吞吐量测试:
1 | root@ubuntu:~/os-eBPF/sockredir$ ./nperf_thruput.sh |
查看结果
第一行为原生TCP的吞吐量,第二行是eBPF重定向之后的吞吐量
1 | 30 tx=256 rx=256 |
遇到的一些问题
编译bpftool工具出错
在/tools/bpf/bpftool目录下执行make时会自动检查系统特征,而对于libbfd库,linux内核为4.x的版本是检测不到的。在5.3版本下会显示on
编译bpf字节码出错
1 | root@ubuntu:~/os-eBPF/sockredir$ clang -O2 -g -target bpf -I /usr/include/linux/ -I /usr/src/linux-headers-4.18.0-13/include/ -c bpf_sockops_v4.c -o bpf_sockops_v4.o |
具体表现在clang编译的时候会报错use of undeclared identifier BPF_XXX,这里需要注意一下,对于bpf中的一些函数也有内核版本的限制,具体的版本可以参考如下链接
BPF Features by Linux Kernel Version
加载bpf字节码出错
1 | root@ubuntu:~/os-eBPF/sockredir$ ~/linux-4.18.13/tools/bpf/bpftool/./bpftool prog load bpf_sockops_v4.o /sys/fs/bpf/bpf_sockops |
问题google后发现,可能是低内核版本不支持bpf程序静态全局变量的定义,
https://stackoverflow.com/questions/48653061/ebpf-global-variables-and-structs
安装指定版本的Linux内核
查询当前内核版本
1 | root@ubuntu:~$ uname -r |
查询当前安装的内核镜像
1 | root@ubuntu:~$ dpkg --get-selections |grep linux-image |
查询指定版本的Linux镜像包
这里以5.3.0-40版本内核为例
1 | root@ubuntu:~$ apt-cache search linux| grep 5.3.0-40 |
安装
1 | sudo apt-get install linux-headers-5.3.0-40-generic linux-image-5.3.0-40-generic |
重启后查询内核版本
1 | root@ubuntu:~$ uname -r |
参考
- https://ebpf.io/what-is-ebpf/
- https://www.dazhuanlan.com/lganlan/topics/1072521
- https://arthurchiao.art/blog/cilium-bpf-xdp-reference-guide-zh/
- https://jishuin.proginn.com/p/763bfbd6368e
- https://forsworns.github.io/zh/blogs/20210311/
- http://arthurchiao.art/blog/socket-acceleration-with-ebpf-zh/
- https://www.cnxct.com/lessons-using-ebpf-accelerating-cloud-native-zh/