Namespace
concept
Linux Namespace是Kernel的一个功能,它可以隔离一系列的系统资源。例如PID、UserID、Network等。Namespace也可以在一些资源上,将进程隔离起来,这些资源包括进程树、网络接口、挂载点等。
例如一家公司向外界出售自己的计算资源。但是需要将不同的客户隔离起来。这个时候,Linux Namespace就派上了用场,使用Namespace就可以做到UID级别的隔离,也就是说,可以以UID为n的用户,虚拟化出来一个Namespace,在这个Namespace里面,用户是具有root权限的。但是在真实的物理机器上,他还是那个以UID为n的用户。
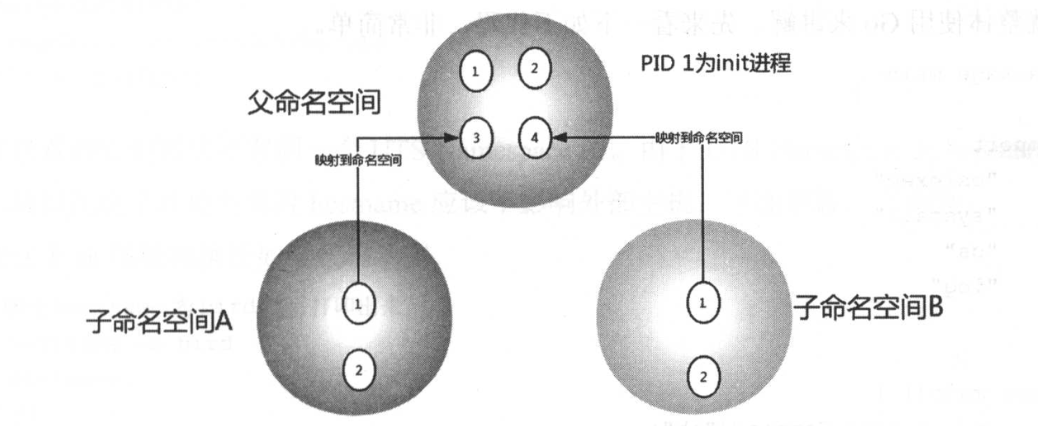
除了User Namespace,PID也是可以被虚拟的。命名空间建立系统的不同视图。从用户的角度来看,每一个命名空间应该像一台单独的Linux计算机一样,有自己的init进程(PID为1),其他进程的PID依次递增。A和B空间都有PID为1的init进程,子命名空间的进程映射到父命名空间的进程上,父命名空间可以知道每一个子命名空间的运行状态,而子命名空间与子命名空间之间是隔离的。
如下图所示,进程3在父命名空间中的PID为 3,但是在子命名空间内,它的PID就是1。也就是说用户从子命名空间A内看进程3就像init进程一样,以为这个进程是自己的初始化进程,但是从整个host来看,它其实只是3号进程虚拟化出来的一个空间而己。
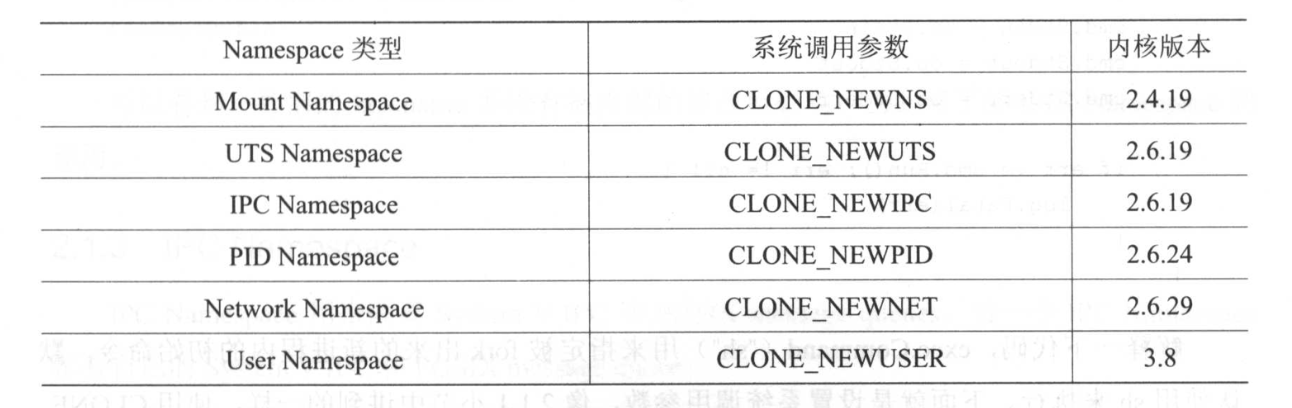
当前Linux一共实现了6种不同类型的Namespace
Namespace的API主要是用如下3个系统调用
clone()创建新进程。根据系统调用参数来判断哪些类型的Namespace被创建,而且它们的子进程也会被包含到这些Namespace中unshare()将进程移出某个Namespacesetns()将进程加入到Namespace中
UTS Namespace
UTS Namespace主要用来隔离nodename和domainname两个系统标识。在UTS Namespace里面,每个Namespace允许有自己的hostname
输出当前的PID
1 | echo $$ |
查看进程的UTS
1 | readlink /proc/<PID>/ns/uts |
IPC Namespace
IPC Namespace用来隔离System V IPC和POSIX message queues。每一个IPC Namespace都有自己的System V IPC和POSIX message queues
查看现有的ipc Message Queues
1 | ipcs -q |
PID Namespace
PID Namespace是用来隔离进程ID的。同样一个进程在不同的PID Namespace里可以拥有不同的PID。这样就可以理解,在docker container里面,使用ps-ef经常会发现,在容器 内,前台运行的那个进程PID是1,但是在容器外,使用ps -ef会发现同样的进程却有不同的PID,这就是PID Namespace做的事情
查看进程树
1 | pstree -pl |
Mount Namespace
Mount Namespace用来隔离各个进程看到的挂载点视图。在不同Namespace的进程中, 看 到的文件系统层次是不一样的。在Mount Namespace中调用mount()和umount()仅仅只会影响当前Namespace内的文件系统 ,而对全局的文件系统是没有影响的
User Namespace
User Namespace主要是隔离用户的用户组ID。也就是说,一个进程的User ID和Group ID在User Namespace内外可以是不同的。比较常用的是,在宿主机上以一个非root用户运行 创建一个User Namespace, 然后在User Namespace里面却映射成root用户。这意味着, 这个进程在User Namespace里面有root权限,但是在User Namespace外面却没有root的权限。从Linux Kernel 3.8开始,非root进程也可以创建User Namespace,并且此用户在Namespace里面可以被映射成root,且在Namespace内有root权限
Network Namespace
Network Namespace是用来隔离网络设备、IP地址端口等网络栈的Namespace。Network Namespace可以让每个容器拥有自己独立的(虚拟的)网络设备,而且容器内的应用可以绑定到自己的端口,每个Namespace内的端口都不会互相冲突。在宿主机上搭建网桥后,就能很方 便地实现容器之间的通信,而且不同容器上的应用可以使用相同的端口
Cgroups
concept
Namespace技术能够帮助进程隔离出自己单独的空间,但是Docker是怎么限制每个空间的大小,保证它们不会互相争夺呢。这里就用到了Cgroups技术。
Linux Cgroups(Control Groups)提供了对一组进程及将来子进程的资源限制、控制和统计的能力,这些资源包括CPU、内存、存储、网络等。通过Cgroups,可以方便地限制某个进 程的资源占用,并且可以实时地监控进程的监控和统计信息
Cgroups中的3个组件
cgroup是对进程分组管理的一种机制,一个cgroup包含一组进程,并可以在这个cgroup上增加Linux subsystem的各种参数配置,将一组进程和一组subsystem的系统参数关联起来。subsystem是一组资源控制的模块,一般包含如下几项blkio设置对块设备(比如硬盘)输入输出的访问控制cpu设置cgroup中进程的CPU被调度的策略cpuacct可以统计cgroup中进程的CPU占用cpuset在多核机器上设置cgroup中进程可以使用的CPU和内存(此处内存仅使用于NUMA 架构)devices控制cgroup中进程对设备的访问freezer用于挂起(suspend)和恢复(resume)cgroup中的进程memory用于控制cgroup中进程的内存占用net_els用于将cgroup中进程产生的网络包分类,以便Linux的tc(traffic controller)可以根据分类区分出来自某个cgroup的包并做限流或监控net_prio设置cgroup中进程产生的网络流量的优先级ns这个subsystem比较特殊,它的作用是使cgroup中的进程在新的Namespace中fork新进程CNEWNS时,创建出一个新的cgroup,这个cgroup包含新的Namespace中的进
每个subsystem会关联到定义了相应限制的cgroup上,并对这个cgroup中的进程做相应的限制和控制。
hierarchy的功能是把一组cgroup串成一个树状的结构,一个这样的树便是一个hierarchy,通过这种树状结构,Cgroups可以做到继承。比如,系统对一组定时的任务进程通过cgroup1限制了CPU的使用率,然后其中有一个定时dump日志的进程还需要限制磁盘 IO,为了避免限制了磁盘IO之后影响到其他进程,就可以创建cgroup2,使其继承于cgroup1并限制磁盘的IO,这样cgroup2便继承了cgroup1中对CPU使用率的限制,并且增加了磁盘IO的限制而不影响到cgroup1中的其他进程
三个组件之间的关系
- 系统在创建了新的
hierarchy之后,系统中所有的进程都会加入这个hierarchy的cgroup根节点,这个cgroup根节点是hierarchy默认创建的 - 一个
subsystem只能附加到一个hierarchy上面 - 一个
hierarchy可以附加多个subsystem - 一个进程可以作为多个
cgroup的成员,但是这些cgroup必须在不同的hierarchy中 - 一个进程
fork出子进程时,子进程是和父进程在同一个cgroup中的,也可以根据需要将其移动到其他cgroup中
Docker是如何使用Cgroups的
设置内存限制
1 | docker run -itd -m 128m ubuntu |
docker会为每个容器在系统的hierarchy种创建cgroup
1 | cd /sys/fs/cgroup/memory/docker/<container_id> |
1 | cat memory.limit_in_bytes #查看cgroup的内存限制 |
可以看到,Docker通过为每个容器创建cgroup,并通过cgroup去配置资源限制和资源监控
Union File System
concept
Union File System简称UnionFS,是一种位Linux、FreeBSD和NetBSD操作系统设计的,把其他文件系统联合到一个联合挂载点的文件系统服务。它使用branch把不同文件系统的文件和目录”透明地”覆盖,形成一个单一一致的文件系统。这些branch或者是read-only的,或者是read-write的,所以当对这个虚拟后的联合文件系统进行写操作的时候,系统是真正写到了一个新的文件中。看起来这个虚拟后的联合文件系统是可以对任何文件进行操作的,但是其实它并没有改变原来的文件,这是因为unionfs用到了一个重要的资源管理技术,叫写时复制。
写时复制(copy-on-write,简称CoW),也叫隐式共享,是一种对可修改资源实现高效复制的资源管理技术。它的思想是,如果一个资源是重复的,但没有任何修改,这时并不需要立即创建一个新的资源,这个资源可以被新旧实例共享。创建新资源发生在第一次写操作,也就是对资源进行修改的时候。通过这种资源共享的方式,可以显著地减少未修改资源复制带来的消耗,但是也会在进行资源修改时增加小部分的开销
AUFS
AUFS,英文全称是Advanced Multi-Layered Unification Filesystem,曾经也叫Acronym Multi-Layered Unification Filesystem、Another Multi-Layered Unification Filesystem。 AUFS完全重写了早期的UnionFS 1.x,其主要目的是为了可靠性和性能,并且引入了一些新的功能,比如可写分支的负载均衡。AUFS的一些实现已经被纳入UnionFS 2.x版本
Docker是如何使用AUFS的
AUFS是Docker选用的第一种存储驱动。AUFS具有快速启动容器、高效利用存储和内存的优点。直到现在,AUFS仍然是Docker支持的一种存储驱动类型。
Image layer和AUFS
每一个Docker image都是由一系列read-only layer组成的,image layer的内容都存储在Docker hosts filesystem的/var/lib/docker/aufs/diff目录下。而/var/lib/docker/aufs/layers目录,则存储着image layer如何堆栈这些layer的metadata
Container layer和AUFS
Docker使用AUFS的CoW技术来实现image layer共享和减少磁盘空间占用。CoW意味着一旦某个文件只有很小的部分有改动, AUFS也需要复制整个文件。这种设计会对容器性能产生一定的影响,尤其是在待复制的文件很大,或者位于很多image layer下方,又或者AUFS需要深度搜索目录结构树的时候。不过也不用过度担心,对于一个容器而言,每个image layer最多只需要复制一次。后续的改动都会在第一次拷贝的container layer上进行。
启动一个container的时候,Docker会为其创建一个read-only的init layer,用来存储与这个容器内环境相关的内容,Docker还会为其创建一个read-write的layer来执行所有写操作。
container layer的mount目录也是/var/lib/docker/aufs/mnt。container的metadata和配置文件都存放在/var/lib/docker/containers/<container-id>目录中。container的read-write layer存储在/var/lib/docker/aufs/diff/目录下。即使容器停止,这个可读写层仍然存在,因而重启容器不会丢失数据,只有当一个容器被删除的时候,这个可读写层才会一起删除。
最后,讲一下AUFS如何为container删除一个文件。如果要删除file1时,AUFS会在container 的read-write层生成一个.wh.file1的文件来隐藏所有read-only层的file1文件。
Linux proc介绍
Linux下的/proc文件系统是由内核提供的,它其实不是一个真正的文件系统,只包含了系统运行时的信息(比如系统内存、mount设备信息、一些硬件配置等),只存在于内存中,而不占用外存空间。它以文件系统的形式,为访问内核数据的操作提供接口。
当遍历/proc目录时,会发现很多数字,这些都是为每个进程创建的空间。
一些具体的文件信息如下所示
1 | /proc/N PID为N的进程信息 |