第一章节
引言
过去十几年计算机系统变得越来越复杂。关于如何获取软件的行为就已经创造了很多的业务类别,这些业务类别都试图解决观测复杂系统的挑战。一种可观测的方法是分析运行在系统中的程序所产生的数据日志,日志是一种很好的信息源,它们可以为您提供有关应用程序行为的精确数据,然而事实是你只能获取到工程师在创建该程序时暴露在外面的日志信息。从任何系统收集日志格式的信息都可能像反编译程序和查看执行流一样具有挑战性。另一种比较流行的方法是使用指标来解释程序的行为方式。指标在数据格式上不同于日志;日志为你提供了明确的数据,而指标则聚合数据来衡量程序在特定时间点的行为。
可观测性是一种从不同角度处理这个问题的新兴实践。人们将可观测性定义为我们必须提出任意问题并从任何给定系统接收复杂答案的能力。可观测性、日志和指标聚合之间的一个关键区别在于你所收集的数据。鉴于通过实践可观测性你需要在任何时间点回答任意问题,对数据进行推理的唯一方法是收集系统可以生成的所有数据,并仅在需要回答问题时对其进行聚合。
黑天鹅事件在软件工程中比我们想象的更普遍,而且是不可避免的。因为我们可以假设我们无法阻止此类事件,所以我们唯一的选择是拥有尽可能多的关于它们的信息来解决它们,而不会对业务系统造成严重影响。可观测性帮助我们构建强大的系统并减轻未来会发生的黑天鹅事件,因为它基于你收集的任何数据可以回答未来所发生的任何问题的前提。对黑天鹅事件的研究和实践可观测性集中在一个中心点,即你从系统收集的数据中。
Linux容器是Linux内核上一组功能的抽象,用于隔离和管理计算机进程。传统上负责资源管理的内核还提供任务隔离和安全性。在Linux中,容器主要基于namespaces和cgroups。namespaces是将任务彼此隔离的组件。从某种意义上说,当你在一个namespaces中时,你会体验到操作系统就像没有其他任务在计算机上运行一样。cgroups 是提供资源管理的组件。从操作的角度来看,它们可以让你对任何资源使用情况进行细粒度控制,例如 CPU、磁盘 I/O、网络等。在过去十年中,随着Linux容器的普及,软件工程师设计大型分布式系统和计算平台的方式发生了转变。多租户计算已经完全依赖于内核中的这些特性。
通过如此依赖 Linux 内核的低级功能,我们挖掘了一个新的复杂性和信息来源,我们在设计可观察系统时需要考虑这些来源。内核是一个事件系统,这意味着所有的工作都是基于事件来描述和执行的。打开文件是一种事件,CPU执行任意指令是一种事件,接收网络数据包是一种事件等等。Berkeley Packet Filter (BPF) 是内核中的一个子系统,可以检查这些新的信息源。BPF允许你编写在内核触发任何事件时安全执行的程序。 BPF为你提供强大的安全保证,以防止你在这些程序中注入使系统崩溃的恶意行为。 BPF正在开发新一轮工具,帮助系统开发人员观察和使用这些新平台。
BPF历史
1992年的时候出现了一篇名为“The BSD Packet Filter: A New Architecture for User-Level Packet Capture”的论文,在该论文中,作者描述了他们如何为Unix内核实现网络数据包过滤器,该过滤器的速度比当时最先进的数据包过滤器快20倍。包过滤器有一个特定的目的:为监控系统网络的应用程序提供来自内核的直接信息。有了这些信息,应用程序就可以决定如何处理这些数据包。 BPF 在包过滤方面引入了两大创新:
- 一种新的虚拟机 (VM),旨在与基于寄存器的CPU高效工作。
- 每个应用程序缓冲区的使用,可以在不复制所有数据包信息的情况下过滤数据包。这最大限度地减少了决策所需的BPF数据量。
这些巨大的改进使所有Unix系统都采用BPF作为网络数据包过滤的首选技术,放弃了消耗更多内存且性能较低的旧实现。 这种实现仍然存在于该Unix内核的许多衍生产品中,包括Linux内核。
2014年的时候,Alexei Starovoitov介绍了eBPF的实现。这种新设计针对现代硬件进行了优化,使其生成的指令集比旧BPF解释器生成的机器代码更快。这个扩展版本还将BPF VM中的寄存器数量从两个32位寄存器增加到十个64位寄存器。寄存器数量和位宽的增加为编写更复杂的程序提供了可能性,因为开发人员可以使用函数参数自由地交换更多信息。 这些更改以及其他改进使扩展的BPF版本比原始BPF实现快了四倍。
这个新实现的最初目标是优化处理网络过滤器的内部BPF指令集。此时,BPF仍然受限于内核空间,只有少数用户空间的程序可以编写BPF过滤器供内核处理,如Tcpdump和Seccomp,今天,这些程序仍然为旧的BPF解释器生成字节码,但内核将这些指令翻译为改进更大的内部表示。
2014年6月,BPF的扩展版本被暴露给用户空间。 这是BPF的一个转折点。 正如Alexei在引入这些更改的补丁中所写的那样,“这个补丁集展示了eBPF的潜力。”
BPF成为顶级内核子系统,不再局限于网络堆栈。 BPF程序开始看起来更像内核模块,非常强调安全性和稳定性。 与内核模块不同,BPF程序不需要你重新编译你的内核,并且它们可以保证在不崩溃的情况下完成。
BPF验证器确保任何BPF程序都将在不崩溃的情况下完成,并确保程序不会尝试访问超出范围的内存。但是,这些优势伴随着某些限制:程序具有允许的最大大小,并且需要限制循环以确保系统的内存永远不会被错误的BPF程序耗尽。
随着使BPF可以从用户空间访问的更改,内核开发人员还添加了一个新的系统调用,bpf。 这个新的系统调用将成为用户空间和内核之间通信的中心部分。BPF maps将成为内核和用户空间之间交换数据的主要机制。eBPF是本书的起点。 在过去的五年中,BPF自从引入这个扩展版本以来已经发生了显着的变化,我们详细介绍了BPF程序的演变、BPF map和受这种演变影响的内核子系统。
BPF结构
正如前面提到的,BPF是一种高度先进的虚拟机,在隔离环境中运行代码指令。 从某种意义上说,你可以将BPF视为你对Java虚拟机(JVM)的看法,这是一个运行由高级编程语言编译的机器代码的专用程序。LLVM之类的编译器和不久的将来的GNU Compiler Collection(GCC)都提供对BPF的支持,允许你将C代码编译成BPF指令。在你的代码被编译之后,BPF使用一个验证器来确保内核可以安全地运行程序。 它可以防止你运行可能使内核崩溃而危及系统的代码。如果你的代码是安全的,BPF程序将被加载到内核中。 Linux内核还包含一个用于BPF指令的即时(JIT)编译器。JIT将在程序验证后直接将BPF字节码转换为机器码,避免了执行时间上的这种开销。这种架构的一个有趣的点是你不需要重新启动系统来加载BPF程序。 你可以按需加载它们,也可以编写自己的初始化脚本,在系统启动时加载BPF程序。
在内核运行任何BPF程序之前,它需要知道程序attach到了哪个执行点。内核有很多附着点,而且这个数量还在不断增加。当您选择一个执行点时,内核还提供了特定的函数助手,您可以使用它们来处理程序接收到的数据,从而使执行点和BPF程序紧密耦合。
BPF架构中最后的组件主要负责用户态和内核态之间的数据交换,这个组件叫做BPF map,BPF map是共享数据的双向结构,这意味着你可以从内核和用户空间的两侧写入和读取它们。BPF map有几种类型的结构,从简单的数组和hash map到专门的map,允许你将整个BPF程序保存在其中。
结论
我们写这本书是为了帮助你熟悉在日常使用这个Linux子系统时需要用到的基本BPF概念。 BPF仍然是一项正在发展的技术,在我们编写本书的过程中,新的概念和范式也在不断发展。 理想情况下,本书将为你提供BPF基础组件的坚实基础,从而帮助您轻松扩展知识。
下一章将直接深入BPF程序的结构以及内核如何运行它们。 它还涵盖了内核中可以attach这些程序的点。 这将帮助你熟悉程序可以使用的所有数据以及如何使用这些数据。
第二章节
第一个BPF程序
BPF虚拟机能够运行指令以响应内核触发的事件。然而,并不是所有的BPF程序都可以访问内核触发的所有事件。当你将一个程序加载到BPF虚拟机中时,你需要决定你正在运行哪种类型的程序。这会通知内核你的程序将被触发的位置。它还告诉BPF验证器在你的程序中将允许哪些助手。当你选择程序类型时,你也在选择程序正在实现的接口。 该接口确保你可以访问适当类型的数据,以及你的程序是否可以直接访问网络数据包。
多年来,内核开发人员一直在添加不同的入口点,你可以将 BPF 程序attach到这些入口点。 这项工作还没有完成,他们每天都在寻找利用BPF的新方法。 在本章中,我们将重点介绍一些最有用的程序类型,目的是让你了解使用BPF可以做什么。 我们将在以后的章节中讨论如何编写BPF程序的许多其他示例。
本章还将介绍BPF验证器在运行程序中所扮演的角色。 该组件验证你的代码是否可以安全执行,并帮助你编写不会导致意外结果的程序,例如内存耗尽或内核突然崩溃。
编写BPF程序
编写BPF程序的最常见方法是使用LLVM编译的C语言子集。LLVM是一种通用编译器,可以输出不同类型的字节码。在这种情况下,LLVM将输出BPF汇编代码,之后我们会将代码加载到内核中。我们会在以后的章节中展示 BPF汇编的简短示例,编写汇编比C语言更合适,例如Seccomp过滤器来控制内核中的传入系统调用。内核提供系统调用bpf来在程序编译后将它们加载到BPF虚拟机中。 该系统调用用于加载程序之外的其他操作,你将在后面的章节中看到更多使用示例。 内核还提供了一些实用工具,可以为你抽象BPF程序的加载。在第一个代码示例中,我们将展示BPF的“Hello World”示例
1 |
|
在上面的程序中有一些简单的概念。当我们想要运行这个程序时,我们使用属性SEC来通知BPF虚拟机。在上面BPF例子中,当检测到execve系统调用中的跟踪点时,我们将运行这个BPF程序。跟踪点是内核二进制代码中的静态标记,允许开发人员注入代码来检查内核的执行。所以我们将看到消息Hello,BPF World!每当内核检测到一个程序执行另一个程序时。
在这个例子的最后,我们还指定了这个程序的许可证。因为Linux内核是在GPL下获得许可的,所以它也只能加载获得GPL许可的程序。 如果我们将许可证设置为其他内容,内核将拒绝加载我们的程序。我们正在使用 bpf_trace_printk在内核跟踪日志中打印一条消息; 该消息你可以在/sys/kernel/debug/tracing/trace_pipe路径下找到此日志。
我们将使用Clang将第一个程序编译为有效的ELF二进制文件。这是内核期望加载的格式。我们将把我们的第一个程序保存在一个名为bpf_program.c的文件中,以便编译它:
1 | clang -O2 -target bpf -c bpf_program.c -o bpf_program.o |
在这里编译的时候遇到了一个错误。具体报错如下
1 | bpf_program.c:7:3: warning: implicit declaration of function 'bpf_trace_printk' is invalid in C99 [-Wimplicit-function-declaration] |
解决方法:https://github.com/iovisor/gobpf/issues/267
重新编译得到bpf_program.o文件
1 | clang -O2 -target bpf -c bpf_program.c -I bpf_helpers.h -o bpf_program.o |
现在我们已经编译了第一个BPF程序,需要将它加载到内核中。我们使用内核提供的特殊帮助器来抽象编译和加载程序。这个帮助程序称为load_bpf_file,它需要一个二进制文件并尝试将其加载到内核中。程序代码如下
1 |
|
我们将使用脚本来编译该程序并将其链接为ELF二进制文件。 在这种情况下,我们不需要指定目标,因为该程序不会加载到BPF虚拟机中。 我们需要使用一个外部库,并且编写一个脚本可以更容易地将它们放在一起。
具体的执行流程如下链接所示
https://github.com/bpftools/linux-observability-with-bpf/tree/master/code/chapter-2/hello_world
这里需要注意在Makefile中需要将kernel-src修改为你的内核源代码路径
1 | [root@VM-16-14-centos bpf]# make bpfload |
当你运行这个程序时,你会开始看到我们的Hello, BPF World! 几秒钟后的消息,即使您没有对计算机执行任何操作。 这是因为在您的计算机后台运行的程序可能正在执行其他调用了execve的程序。
1 | [root@VM-16-14-centos bpf]# ./monitor-exec |
当您停止此程序时,该消息将停止显示在您的终端中。 一旦加载 BPF 程序的程序终止,BPF 程序就会从虚拟机中卸载。在接下来的章节中,我们将探讨如何使BPF程序持久化,即使它们的加载器终止之后,因为在许多情况下,我们会希望BPF程序在后台运行,从系统中收集数据,而不管其他进程是否正在运行。现在我们已经了解了BPF程序的基本结构,接下来可以深入了解我们能够编写哪些类型的程序,从而使得我们能够访问Linux内核中的不同子系统。
BPF程序类型
尽管程序中没有明确的分类,但我们可以将所有类型分为两类,具体取决于它们的主要用途。
第一类是追踪(tracing)。 编写的程序会帮助你更好地了解系统中正在发生的事情。它们为你提供有关系统行为及其运行的硬件的直接信息。 它们可以访问与特定程序相关的内存区域,并从正在运行的进程中提取执行跟踪信息。 它们还使你可以直接访问为每个特定进程分配的资源,从文件描述符到CPU和内存的使用情况。
第二类是网络(networking)。 这些类型的程序允许你检查和操作系统中的网络流量。它们让你过滤来自网络接口的数据包,甚至完全拒绝这些数据包。不同类型的程序可以附着(attach)到内核内网络处理的不同阶段。 这有优点也有缺点。例如,你可以在网络驱动程序接收到数据包后立即将BPF程序附着到网络事件,但是该程序将访问的有关数据包的信息较少,因为内核还没有足够的信息来提供给你。另一方面,您可以在 BPF 程序被传递到用户空间之前立即将它们附加到网络事件。 在这种情况下,你可以获得有关数据包的更多信息,这会帮助你做出更好的决策,但是这样处理成本较高。
我们接下来展示的程序类型没有分类。我们按照它们被添加到内核的时间顺序来介绍这些类型。
Socket Filter程序
BPF_PROG_TYPE_SOCKET_FILTER是第一个添加到Linux内核的程序类型。当BPF程序附着到原始套接字时,你可以访问该套接字处理的所有数据包。套接字过滤程序不允许修改这些数据包的内容或更改这些数据包的目的地,它们仅允许你出于可观察性目的访问它们。你的程序接收的元数据包含与网络堆栈相关的信息,例如用于传递数据包的协议类型等。
Kprobe程序
kprobes是可以动态附加到内核中某些调用点的函数。BPF kprobe程序类型允许你将BPF程序用作kprobe处理程序。 它们使用BPF_PROG_TYPE_KPROBE类型定义。BPF虚拟机确保kprobe程序始终可以安全运行,这是传统kprobe模块的优势。 这里需要强调的是,kprobe不是内核中的稳定入口点,所以你需要确保kprobe BPF程序与你正在使用的特定内核版本兼容。
当你编写一个附着到kprobe的BPF程序时,你需要决定它是作为函数调用中的第一条指令执行还是在调用完成时执行。你需要在BPF程序的节头中声明此行为。例如,如果你想在内核调用exec系统调用时检查参数,你将在调用开始时附加程序,这个时候需要在头部添加SEC("kprobe/sys_exec")。如果要检查调用exec系统调用的返回值,则需要在头部添加SEC("kretprobe/sys_exec")。
Tracepoint程序
这种类型的程序允许将BPF程序附着到内核提供的跟踪点处理程序。跟踪点程序使用BPF_PROG_TYPE_TRACEPOINT类型定义。跟踪点是内核代码库中的静态标记,允许注入任意代码进行跟踪和调试。它们不如kprobes灵活,因为它们需要事先由内核定义,但在引入内核后就是稳定的。 当你想要调试系统时,这种方法提供了更高级别的可预测性。
系统中的所有跟踪点都定义在目录/sys/kernel/debug/tracing/events中。在该目录下,每个子系统都包含任何跟踪点,并且可以将BPF程序附着到这些子系统。BPF跟踪点在/sys/kernel/debug/tracing/events/bpf中定义。 例如,可以在此处找到bpf_prog_load的跟踪点定义。 这意味着你可以编写一个BPF程序来检查其他BPF程序何时加载。
XDP程序
XDP程序允许你编写在网络数据包到达内核时就执行的代码。 它们使用BPF_PROG_TYPE_XDP类型定义。 鉴于内核没有太多时间来处理信息本身,它只从数据包中公开一组有限的信息。 因为数据包是在早期执行的,所以你对如何处理该数据包有更高级别的控制。
XDP程序定义了几个可以控制的操作,并允许你决定如何处理该数据包。你可以从你的XDP程序中返回XDP_PASS,这意味着数据包应该被传递到内核中的下一个子系统。你还可以返回XDP_DROP,这意味着内核应该完全忽略此数据包,并且不对其进行任何其他操作。你还可以返回XDP_TX,这意味着数据包应该被转发回最初接收数据包的网卡接口(NIC)。
这种级别的控制使得网络层的处理更加灵活,XDP也已经成为BPF中的主要组件之一。在后续章节中,我们还会讨论XDP许多强大之处,例如保护你的网络免受分布式拒绝服务(DDoS)攻击。
Perf Event程序
这些类型的BPF程序允许你将BPF代码附着到Perf events。它们使用BPF_PROG_TYPE_PERF_EVENT类型定义。Perf是内核中的一个内部分析器,它为硬件和软件发出性能数据事件。你可以使用它来监控许多事物,从计算机的CPU到系统上运行的任何软件。当你将BPF程序附着到Perf events时,你的代码将在每次Perf生成数据时执行。
Cgroup Socket程序
这些类型的程序允许你将BPF处理逻辑附着到控制组(cgroups)。它们使用BPF_PROG_TYPE_CGROUP_SKB类型定义。它们允许cgroup控制它们包含的进程内的网络流量。使用这些程序可以在将网络数据包交付cgroup中的进程之前决定如何处理它。内核尝试传递给同一cgroup中的任何进程的任何数据包都将通过这些过滤器之一。 同时,你可以决定当cgroup中的进程通过该接口发送网络数据包时要做什么。
你会发现,这些行为类似于BPF_PROG_TYPE_SOCKET_FILTER程序。 主要区别在于BPF_PROG_TYPE_CGROUP_SKB程序附着到一个cgroup内的所有进程,而不是特定进程;这种行为适用于在给定cgroup中创建的当前和以后的套接字。附着到cgroup的BPF程序在容器环境中非常有用,在这些环境下,进程组受cgroup约束,因此你可以将相同的策略应用于所有进程,而无需单独识别每个进程。Cilium是一个流行的开源项目,它为Kubernetes提供负载均衡和安全功能,在cilium中,广泛使用cgroup套接字程序将其策略应用于组而不是孤立的容器中。
Cgroup Open Socket程序
这些类型的程序允许你在cgroup中的任何进程打开网络套接字时执行代码。这种行为类似于附着到cgroup套接字缓冲区的程序,但不是让你在数据包通过网络时访问它们,而是允许你控制进程打开新套接字时发生的情况。它们使用BPF_PROG_TYPE_CGROUP_SOCK类型定义。 这对于可以打开套接字的程序组提供安全性和访问控制很有用,因为这样不必单独限制每个进程的功能。
Socket Option程序
这些类型的程序允许你在运行时修改套接字连接选项,当数据包通过内核网络堆栈中的多个阶段时。它们附着到cgroup上,很像BPF_PROG_TYPE_CGROUP_SOCK和BPF_PROG_TYPE_CGROUP_SKB,但与那些程序类型不同的是,它们可以在连接的生命周期内多次调用。 该程序使用BPF_PROG_TYPE_SOCK_OPS类型定义。
当你创建一个这种类型的BPF程序时,你的函数调用会收到一个名为op的参数,它表示内核将要通过套接字连接执行的操作,因此,你就会知道程序在连接生命周期中的哪个时间点被调用。有了这些信息,你就可以访问网络IP地址和连接端口等数据,还可以修改连接选项以设置超时并更改给定数据包的往返延迟时间。
举个例子,Facebook使用它来为同一数据中心内的连接设置较短的设置重传超时(RTO)。RTO是系统在网络连接预计发生故障后恢复的时间。这个目标也代表了系统在遭受不可连接的情况下无法使用的时间。 在Facebook的案例中,它假设同一数据中心中的机器应该具有较短的RTO,并且使用 BPF 程序修改了这个阈值。
Socket Map程序
BPF_PROG_TYPE_SK_SKB程序让你可以访问套接字映射和套接字重定向。 套接字映射允许你保留对多个套接字的引用。当你有这些引用时,你可以使用特殊的帮助器将传入的数据包从一个套接字重定向到另一个套接字。当你想使用BPF实现负载均衡功能时,可以通过跟踪多个套接字在它们之间转发网络数据包,而无需离开内核空间。Cillium和Facebook的Katran等项目广泛使用这些类型的程序来控制网络流量。
Cgroup Device程序
这种类型的程序允许你决定是否可以为给定设备执行cgroup中的操作。这些程序使用BPF_PROG_TYPE_CGROUP_DEVICE类型定义。 cgroups (v1)的第一个实现允许你为特定设备设置权限,然而,cgroups(v2) 缺少这个特性。引入这种类型的程序是为了提供该功能。同时,能够编写BPF程序可以让你在需要时更灵活地设置这些权限。
Socket Message Delivery程序
这些类型的程序可以控制是否应该传递发送到套接字的消息。它们使用BPF_PROG_TYPE_SK_MSG类型定义。当内核创建socket时,它会将socket存储在socket map中。该map使内核可以快速访问特定的socket组。当你将套接字消息的BPF程序附着到socket map时,发送到这些socket的所有消息都将在传递它们之前被程序过滤。在过滤消息之前,内核会复制消息中的数据,以便可以处理它。这些程序有两个返回值:SK_PASS和SK_DROP。 如果你希望内核将消息发送到socket,则使用第一个,如果你希望内核忽略该消息,则使用后一个。
RAW Tracepoint程序
我们之前谈到了一种访问内核中跟踪点的程序。内核开发人员添加了一个新的跟踪点程序来解决访问内核保存的原始格式的跟踪点参数。这种格式让你可以访问有关内核正在执行的任务的更详细信息,但是,它的性能开销很小。 大多数情况下你会希望在程序中使用常规跟踪点来避免这种性能开销,你也可以在需要时使用原始跟踪点访问原始参数。这些类型的程序被定义为BPF_PROG_TYPE_RAW_TRACE POINT
Cgroup Socket Address程序
当用户空间程序由特定的cgroup控制时,这种类型的程序允许你操作用户空间程序所附加的IP地址和端口号。 当你希望确保一组特定的用户空间程序使用相同的IP地址和端口时,你的系统会使用多个IP地址。当你将这些用户空间程序放在同一个cgroup中时,这些BPF程序使你可以灵活地操作这些绑定。这确保了来自这些应用程序的所有传入和传出连接都使用BPF程序提供的IP和端口。这些程序类型定义为BPF_PROG_TYPE_CGROUP_SOCK_ADDR
Socket Reuseport程序
SO_REUSEPORT是内核中的一个选项,它允许同一主机中的多个进程绑定到同一端口。 当你想要跨多个线程分配负载时,此选项允许在接受的网络连接中获得更高的性能。BPF_PROG_TYPE_SK_REUSEPORT程序类型允许你编写BPF程序hook到内核来决定是否重用端口。如果你的BPF程序返回SK_DROP,你可以阻止程序重用同一个端口。当BPF程序返回SK_PASS时,你可以通知内核使用它自己的重用例程。
Flow Dissection程序
流解析器是内核的一个组件,它跟踪网络数据包需要通过的不同层,从到达系统到交付到用户空间程序。 它允许你使用不同的分类方法来控制数据包的流动。内核中内置的解析器称为Flower分类器,防火墙和其他过滤设备使用它来决定如何处理特定的数据包。
BPF_PROG_TYPE_FLOW_DISSECTOR程序旨在hook流解析器路径中的逻辑。 它们提供了内置解析器无法提供的安全保证,例如确保程序始终终止,这在内置解析器中可能无法保证。 这些BPF程序可以修改网络数据包在内核中所遵循的流。
Other BPF程序
我们已经讨论了在不同环境中使用的程序类型,但还有一些其他的BPF程序类型我们还没有涉及。 在这里仅简要提及
Traffic classifier程序
BPF_PROG_TYPE_SCHED_CLS和BPF_PROG_TYPE_SCHED_ACT是两种类型的BPF程序,它们允许对网络流量进行分类并修改套接字缓冲区中数据包的某些属性。Lightweight tunnel程序
BPF_PROG_TYPE_LWT_IN、BPF_PROG_TYPE_LWT_OUT、BPF_PROG_TYPE_LWT_XMIT 和 BPF_PROG_TYPE_LWT_SEG6LOCAL是允许将代码附着到内核的轻量级隧道基础设施的BPF程序类型。Infrared device程序
BPF_PROG_TYPE_LIRC_MODE2程序允许通过连接到红外设备(例如遥控器)来附着BPF程序。
以上这些程序是专门的,它们的使用尚未被社区广泛采用。
接下来,我们将讨论BPF如何确保你的程序在内核加载它们后不会导致系统发生灾难性故障。
BPF校验器
允许任何人在Linux内核中执行任何代码乍一听是一件很疯狂的事情。如果没有BPF验证器,在生产系统中运行BPF程序的风险会太高。用内核网络维护者之一Dave S. Miller的话来说,“唯一介于eBPF程序和一个黑暗破坏鸿沟之间的是eBPF验证器。”
显然,BPF验证器也是一个运行在系统上的程序,它能够仔细审查以确保正确完成它的工作。在过去几年中,安全研究人员在验证程序中发现了一些漏洞,这些漏洞允许攻击者访问内核中的随机内存,即使是非特权用户。你可以在CVE目录中阅读有关此类漏洞的更多信息。 例如,CVE-2017-16995描述了任何用户如何读写内核内存并绕过BPF验证程序。
验证程序执行的第一个检查是对虚拟机将要加载的代码的静态分析。 第一次检查的目的是确保程序有预期的结束。为此,验证器使用代码创建有向无环图 (DAG)。验证器分析的每条指令都成为图中的一个节点,每个节点都链接到下一条指令。验证器生成此图后,会执行深度优先搜索(DFS),以确保程序完成并且代码不包含危险路径。 这意味着它将遍历图的每个分支,一直到分支的底部,以保证没有递归循环。
以下是验证器在第一次检查期间的一些条件:
- 程序不包括控制循环。为了确保程序不会陷入无限循环,验证器拒绝任何类型的控制循环。已经有人提议在 BPF 程序中允许循环,但在撰写本文时,还没有一个被采用。
- 程序不会尝试执行超过内核允许的最大值的指令。此时,要执行的最大指令数为4096。这个限制是为了防止BPF永远运行。
- 程序不包含任何无法访问的指令,例如从未执行的条件或函数。这可以防止在虚拟机中加载死代码,这也会延迟BPF程序的终止。
- 程序不会试图跳出它的界限。
验证器执行的第二项检查是BPF程序的试运行。 这意味着验证器将尝试分析程序将要执行的每条指令,以确保它不会执行任何无效指令。此次执行还检查所有内存指针是否被正确访问和取消引用。最后,试运行会通知验证器程序中的控制流,以确保无论程序采用哪条控制路径,它都到达BPF_EXIT指令。为此,验证器会跟踪堆栈中所有访问过的分支路径,并在采用新路径之前对其进行评估,以确保它不会多次访问特定路径。在这两项检查通过后,验证器认为程序是可以安全执行的。
如果你对如何分析程序感兴趣,bpf系统调用允许你进行调试验证程序的检查。 当你使用此系统调用加载程序时,可以设置几个属性,使验证程序打印其操作日志:
1 | union bpf_attr attr = { |
log_level字段告诉验证器是否打印任何日志。设置为1时会打印其日志,设置为0时不会打印任何内容。如果要打印验证器日志,还需要提供日志缓冲区及其大小。这个缓冲区是一个多行字符串,你可以打印它来检查验证器所做出的决定。
下一节将介绍BPF如何在内存中构造程序信息。程序的结构方式将有助于弄清楚如何访问BPF内部,帮助你更好的调试和理解程序的行为方式。
BPF类型格式
BPF类型格式(BTF)是元数据结构的集合,可增强BPF 程序、映射和函数的调试信息。BTF包含源信息,因此我们在后续所讨论的BPFTool等工具可以向你展示对BPF数据的更丰富的解释。这些元数据存储在二进制程序中一个特殊的“.BFT”元数据部分下。BTF信息有助于使你的程序更易于调试,但它会显著增加二进制文件的大小,因为它需要跟踪程序中声明的所有内容的类型信息。BPF验证器也使用此信息来确保你的程序定义的结构类型是正确的。
BTF专门用于注释C语言类型。 像LLVM这样的BPF编译器知道如何为你包含这些信息,因此你无需完成将这些信息添加到每个结构的繁琐任务。然而,在某些情况下,工具链仍然需要一些注释来增强程序。在后续章节,我们将描述这些注释是如何发挥作用的,以及像BPFTool这样的工具是如何显示这些信息的。
BPF尾调用
BPF程序可以通过尾调用调用其他BPF程序。 这是一个强大的功能,因为它允许你通过组合更小的BPF函数来组装更复杂的程序。5.2之前的内核版本对BPF程序可以生成的机器指令的数量有硬性限制。此限制设置为4096,以确保程序可以在合理的时间内终止。然而,随着人们构建更复杂的BPF程序,他们需要一种方法来扩展内核强加的指令限制,这就是尾调用发挥作用的地方。从内核版本5.2开始,指令限制增加到一百万条指令。尾调用嵌套也受到限制,在本例中为32个调用,这意味着你可以在一个链中组合多达32个程序来为遇到的问题提供解决方案。
当你从另一个BPF程序调用一个BPF程序时,内核会完全重置程序上下文。记住这一点很重要,因为你可能需要一种在程序之间共享信息的方法。每个BPF程序作为其参数接收的上下文对象不会帮助我们解决这个数据共享问题。 在下一章中,我们将讨论BPF map作为在程序之间共享信息的一种方式。我们还会展示如何使用尾调用从一个BPF程序跳转到另一个的示例。
参考
- http://vinin.me/2022/04/10/Hello-eBPF/
- https://mirrors.edge.kernel.org/pub/linux/kernel/v5.x/
- https://blog.csdn.net/Xiongzhizhu/article/details/51816243
- https://blog.csdn.net/weixin_43847470/article/details/122145676
第三章节
BPF映射
在程序中调用行为的消息传递是软件工程中广泛使用的技术。 一个程序可以通过发送消息来修改另一个程序的行为,这也允许在这些程序之间交换信息。 BPF最令人痴迷的一方面是,内核代码和被加载的代码可以在运行时使用消息传递相互通信。
在本章中,我们将介绍BPF程序和用户空间程序如何相互通信。我们描述了内核和用户空间之间的不同通信管道,以及它们如何存储信息。 我们还向你展示了这些管道的用例,以及如何使这些管道中的数据在程序初始化之间进行持久化。
BPF映射是驻留在内核中的key/value存储。 任何知道它们的BPF程序都可以访问它们。在用户空间中运行的程序也可以通过使用文件描述符来访问这些映射。只要事先正确指定数据大小,就可以在map中存储任何类型的数据。 内核将键和值视为二进制类型的大对象(blob),它不关心你在map中保留的内容。BPF 验证器包含多种保护措施,以确保你所创建和访问map的方式是安全的。
创建BPF映射
创建BPF映射最直接的方法是使用bpf系统调用。当调用的第一个参数是BPF_MAP_CREATE时,是在告诉内核你想要创建一个新的映射。此调用将返回与你刚创建的BPF Maps关联的文件描述符标识符。系统调用中的第二个参数是此映射的配置:
1 | union bpf_attr { |
系统调用中的第三个参数是此配置属性的大小。例如,你可以创建一个hash map来存储无符号整数作为键和值,如下所示:
1 | union bpf_attr my_map { |
如果调用失败,内核将返回值-1。 失败的原因可能有三个。如果其中一个属性无效,内核将errno变量设置为EINVAL。 如果执行操作的用户没有足够的权限,内核会将errno变量设置为EPERM。 最后,如果没有足够的内存来存储映射,内核将errno变量设置为ENOMEM。
创建BPF映射的ELF约定
内核包含一些约定和助手来生成和使用BPF maps。 你可能会发现这些约定比直接执行系统调用更频繁地出现,因为它们更具可读性且更容易遵循。请记住,这些约定仍然使用bpf系统调用来创建map,即使直接在内核中运行也是如此,如果不知道事先需要哪种map,你会发现直接使用系统调用更有用。
helper函数bpf_map_create包装了刚才看到的代码,以便更容易根据需要初始化map。我们可以使用它创建先前定义的map,只需一行代码:
1 | int fd; |
如果你知道你的程序需要哪种map,你也可以预先定义它。这有助于在程序预先使用的map中获得更高的可见性:
1 | struct bpf_map_def SEC("maps") my_map = { |
当您以这种方式定义map时,您使用的是所谓的section属性,在本例中为SEC("maps")。 这个宏告诉内核这个结构是一个BPF映射,它应该被相应地创建。你可能已经注意到,在这个新示例中,我们没有与map关联的文件描述符标识符。 在这种情况下,内核使用一个名为map_data的全局变量来存储有关程序中map的信息。 这个变量是一个结构数组,它按照你在代码中指定每个映射的方式排序。例如,如果前一个map是你的代码中指定的第一个map,你将从数组中的第一个元素获取文件描述符标识符:
1 | fd = map_data[0].fd; |
你还可以从此结构中访问map的名称及其定义, 此信息有时可用于调试和跟踪目的。初始化map后,你可以开始使用它们在内核和用户空间之间发送消息。 现在让我们看看如何使用这些map所存储的数据进行工作。
与BPF映射工作
内核和用户空间之间的通信将成为你编写的每个BPF程序的基础部分。 为内核编写代码时访问映射的API与为用户空间程序编写代码时不同。 本节介绍每个实现的语义和具体细节。
更新BPF映射中的元素
创建任何map后,你可能希望用信息填充它。为此,内核助手提供了函数bpf_map_update_elem。 如果你在内核运行的程序中从bpf/bpf_helpers.h加载这个函数,与在用户空间运行的程序中从tools/lib/bpf/bpf.h加载它,这个函数的签名是不同的。这是因为在内核中工作时可以直接访问map,但在用户空间中工作时需要使用文件描述符引用它们。行为也略有不同,内核上运行的代码可以直接访问内存中的map,并且可以就地原子地更新元素。但是,在用户空间中运行的代码必须将消息发送到内核,内核会在更新map之前复制提供的值,这使得更新操作不是原子的。此函数在操作成功时返回0,在操作失败时返回负数。 在失败的情况下,全局变量errno将填充失败原因。 我们将在本章后面列出更多上下文的失败案例。
内核中的bpf_map_update_elem函数有四个参数。第一个是指向我们已经定义的map的指针。 第二个是指向我们要更新的键的指针。 因为内核不知道我们要更新的键的类型,所以这个方法被定义为一个指向void的不透明指针,这意味着我们可以传递任何数据。第三个参数是我们要插入的值。 此参数使用与key参数相同的语义。 在本书中,我们展示了一些如何利用不透明指针的高级示例。 你可以使用此函数中的第四个参数来更改map的更新方式。这个参数可以取三个值:
- 如果你传递0,你告诉内核你想要更新元素如果它存在或不存在它都应该在映射中创建元素。
- 如果你传递1,你告诉内核只在元素不存在时创建它。
- 如果你传递2,内核只会在元素存在时更新它。
这些值被定义为你可以使用的常量,而不必记住整数语义。值为BPF_ANY表示0,BPF_NOEXIST表示1,BPF_EXIST表示2。
让我们使用在上一节中定义的映射来编写一些示例。 在我们的第一个示例中,我们向map添加了一个新值。 因为map是空的,我们可以假设任何更新行为都是正常的:
1 | int key, value, result; |
在这个例子中,我们使用strerror来描述errno变量中的错误集。 你可以使用man strerror在手册页上了解有关此功能的更多信息。现在让我们看看当我们尝试创建具有相同键的元素时会得到什么结果:
1 | int key, value, result; |
因为我们已经在map中创建了一个键为1的元素,调用bpf_map_update_elem的结果将为-1,errno值为EEXIST。 该程序将在屏幕上打印以下内容:
1 | Failed to update map with new value: -1 (File exists) |
同样,让我们更改此程序以尝试更新一个不存在的元素:
1 | int key, value, result; |
使用标志BPF_EXIST,此操作的结果将再次为-1。 内核会将errno变量设置为ENOENT,程序将打印以下内容:
1 | Failed to update map with new value: -1 (No such file or directory) |
这些示例展示了如何从内核程序中更新映射。 你还可以从用户空间程序中更新映射。 执行此操作的助手与我们刚刚看到的类似, 唯一的区别是它们使用文件描述符来访问映射,而不是直接使用指向映射的指针。我们知道,用户空间程序总是使用文件描述符访问映射。 因此,在我们的示例中,我们将参数my_map替换为全局文件描述符标识符map_data[0].fd。 在这种情况下,原始代码如下所示:
1 | int key, value, result; |
读取BPF映射中的元素
BPF还提供了两个不同的帮助器来根据你的代码运行的位置从映射中读取。 这两个助手都称为 bpf_map_lookup_elem。 和更新助手一样,它们的第一个参数不同, 内核方法采用对映射的引用,而用户空间助手采用映射的文件描述符标识符作为其第一个参数。两种方法都返回一个整数来表示操作是失败还是成功,就像更新助手一样。 这些帮助器中的第三个参数是指向代码中变量的指针,该变量将存储从映射中读取的值。 我们根据上一节中看到的代码提供两个示例。
第一个示例是BPF程序在内核上运行时读取插入到映射中的值:
1 | int key, value, result; // value is going to store the expected element's value |
如果我们试图读取的键bpf_map_lookup_elem返回一个负数,它将errno变量中设置错误。 例如,如果我们在尝试读取并没有插入的值,内核将返回“未找到”错误ENOENT。
第二个示例与刚刚看到的示例类似,但这次我们从运行在用户空间的程序中读取映射:
1 | int key, value, result; // value is going to store the expected element's value |
这就是我们能够访问BPF映射中的信息所需的全部内容。 我们将在后面的章节中研究不同的工具包是如何简化这一点的,以使访问数据变得更加简单。 接下来我们来谈谈从映射中删除数据。
删除BPF映射中的元素
我们可以在map上执行的第三个操作是删除元素。 与写入和读取元素一样,BPF为我们提供了两个不同的帮助器来删除元素,都称为bpf_map_delete_element。和前面的例子一样,当你在内核上运行的程序中使用这些助手时,它们使用对映射的直接引用,当你在运行用户空间的程序中使用它们时,它们使用映射的文件描述符标识。
第一个示例是BPF程序在内核上运行时删除了插入到映射中的值:
1 | int key, result; |
如果你尝试删除的元素不存在,内核将返回一个负数。 在这种情况下,它还会使用“未找到”错误ENOENT填充errno变量。
第二个示例是当BPF程序运行在用户空间时删除元素`
1 | int key, result; |
迭代BPF映射中的元素
我们在本节中看到的最后一个操作可以帮助你在BPF程序中找到任意元素。 有时你不知道要查找的元素的确切键,或者只想查看map中的内容。BPF为此提供了一个名为bpf_map_get_next_key的指令。 此指令仅适用于在用户空间运行的程序。
这个帮助器为你提供了一种确定的方式来迭代map上的元素,但它不如大多数编程语言中的迭代器那么直观。 它需要三个参数。第一个是map的文件描述符标识符,第二个参数key是要查找的标识符,第三个参数next_key是映射中的下一个键。我们更喜欢将第一个参数称为lookup_key。 当你调用这个帮助器时,BPF会尝试在这个map中使用作为查找键传递的键来查找元素, 然后,它将next_key参数设置为映射中的相邻键。 所以如果你想知道key 1之后是哪个key,你需要设置1作为你的查找key,如果map有一个与这个key相邻的key,BPF会将它设置为next_key参数的值。
在查看bpf_map_get_next_key的工作原理之前,让我们在map中多添加一些元素:
1 | int new_key, new_value, it; |
如果要打印映射中的所有值,可以将bpf_map_get_next_key与映射中不存在的查找键一起使用。 这会强制BPF从map的开头开始:
1 | int next_key, lookup_key; |
上述代码输出如下
1 | The next key in the map is: '1' |
你可以看到在循环结束时将下一个键分配给lookup_key, 这样,我们继续遍历map,直到终点。 当bpf_map_get_next_key到达map末尾时,返回值为负数,errno变量设置为ENOENT。 这将中止循环执行。
bpf_map_get_next_key可以查找从map中任意点开始的键,如果你只想要另一个特定键的下一个键,则不需要从map的开头开始。
许多编程语言在遍历其元素之前会复制映射中的值。 如果你的程序中的某些其他代码试图改变map,这样可以防止一些未知行为。如果该代码从map中删除元素,这将会是一个危险的操作。BPF在使用bpf_map_get_next_key循环之前不会复制映射中的值。如果程序的另一部分在循环遍历值时从map中删除了一个元素,则bpf_map_get_next_key将重新开始进行遍历。 让我们看一个例子:
1 | int next_key, lookup_key; |
该程序的打印输出如下
1 | The next key in the map is: '1' |
查找和删除元素
内核公开的另一个用于处理map的函数是bpf_map_lookup_and_delete_elem。此函数在map中搜索给定键并从中删除元素。同时,它把元素的值写入一个变量供程序使用。 当你使用队列和堆栈映射时,此函数会派上用场,而且,它不仅限于与这些类型的映射一起使用。 让我们看一个示例,说明如何将它与我们在之前示例中使用的map一起使用:
1 | int key, value, result, it; |
在这个例子中,我们尝试从map中获取相同的元素两次。在第一次遍历中,这段代码将打印map中元素的值。 但是,因为我们使用的是bpf_map_lookup_and_delete_element,所以第一次遍历也会从map中删除元素。 循环第二次尝试获取元素时,此代码将失败,并将使用“未找到”错误ENOENT填充errno变量。
并发访问map元素
使用BPF map的挑战之一是许多程序可以同时访问相同的map。这可能会在我们的BPF程序中引入竞争条件,并使map中的资源访问变得不可预测。 为了防止竞争条件,BPF引入了BPF自旋锁的概念,它允许你在操作map元素时锁定对它的访问。 自旋锁仅适用于数组、散列和cgroup存储映射。
有两个BPF辅助函数可用于处理自旋锁:bpf_spin_lock用于锁定一个元素,bpf_spin_unlock可以解锁该元素。这些辅助函数使用信号量的结构来访问包含此信号量的元素。 当信号量被锁定时,其他程序无法访问元素的值,它们会一直等到信号量被解锁。 同时,BPF自旋锁引入了一个新的标志,用户空间程序可以使用它来改变锁的状态。该标志称为BPF_F_LOCK。使用自旋锁我们需要做的第一件事是创建我们想要锁定访问的元素,然后添加我们的信号量:
1 | struct concurrent_element { |
我们会把这个结构存储在BPF map中,并在元素中使用信号量来防止对它的不当访问。 现在,我们可以声明将包含这些元素的map。 此map必须使用BPF类型格式(BTF)进行注释,以便验证器知道结构。 类型格式通过向二进制对象添加调试信息,使内核和其他工具对BPF数据结构有更丰富的理解。因为这段代码将在内核中运行,我们可以使用libbpf提供的内核宏来注释这个并发映射:
1 | struct bpf_map_def SEC("maps") concurrent_map = { |
在BPF程序中,我们可以使用两个锁辅助函数来保护这些元素免受竞争条件的影响。即使信号量被锁定,我们的程序也保证能够安全地修改元素的值:
1 | int bpf_program(struct pt_regs *ctx) { |
上述代码通过初始化我们的并发映射来锁定对其值的访问。 然后,它从映射中获取该值并锁定其信号量,以便它可以保存计数值,从而防止数据竞争。 使用完该值后,它会释放锁,以便其他映射可以安全地访问该元素。
在用户空间,我们可以通过使用标志BPF_F_LOCK来保存对并发映射中元素的引用。你可以将此标志与bpf_map_update_elem和bpf_map_lookup_elem_flags辅助函数一起使用。 这个标志允许你更新元素而不用担心数据竞争。
自旋锁并不总是有用。 如果您只是在map中聚合值,则不需要使用自旋锁。 但是,如果你想确保并发程序在对它们执行多个操作时不会更改映射中的元素,从而保持原子性,那么自旋锁就很有用。
BPF映射类型
哈希表映射
哈希表映射是第一个添加到BPF的通用映射。 它们使用BPF_MAP_TYPE_HASH类型定义。你可以使用任何大小的键和值, 内核会根据需要分配和释放它们。当你在哈希表映射上使用bpf_map_update_elem时,内核会自动替换元素。哈希表映射经过优化,查找速度非常快,它们对于保存经常读取的结构化数据很有用。让我们看一个使用它们来跟踪网络IP及其速率限制的示例程序:
1 |
|
在这段代码中,我们声明了一个结构化的key,我们将使用它来保存有关IP地址的信息。 我们定义了我们的程序将用来跟踪速率限制的映射。你可以看到我们在此映射中使用IP地址作为键。 这些值将是我们的BPF程序从特定IP地址接收网络数据包的频率次数。
我们可以编写一个代码片段来更新内核中的这些计数器:
1 | uint64_t update_counter(uint32_t ipv4) { |
该函数获取从网络数据包中提取的IP地址,并使用我们声明的复合键执行映射查找。 在这种情况下,我们假设我们之前已经用零值初始化了计数器; 否则,bpf_map_lookup_elem调用将返回一个负数。
数组映射
数组映射是添加到内核的第二种类型的BPF映射。 它们使用BPF_MAP_TYPE_ARRAY类型定义。 当你初始化一个数组映射时,它的所有元素都预先分配在内存中并设置为零值。 因为这些映射是由一个元素切片支持的,所以键是数组中的索引,它们的大小必须正好是四个字节。使用数组映射的一个缺点是无法删除映射中的元素,并且无法使数组小于实际值。如果你尝试在数组映射上使用map_delete_elem,调用将失败,结果会收到错误EINVAL。
数组映射通常用于存储可以改变值的信息,但它的行为通常是固定的。 人们使用它来存储具有预定义分配规则的全局变量。因为你不能删除元素,所以可以假设特定位置的元素总是代表同一个元素。要记住的另一件事是map_update_elem不是原子的,就像你在哈希表映射中看到的那样。如果正在进行更新,同一程序可以同时从同一位置读取不同的值。 如果将计数器存储在数组映射中,则可以使用内核的内置函数__sync_fetch_and_add对映射的值执行原子操作。
程序数组映射
程序数组映射是第一个添加到内核的专用映射。它们使用BPF_MAP_TYPE_PROG_ARRAY类型定义。 你可以使用这种类型的映射来存储对BPF程序的文件描述符标识符的引用。 与辅助函数bpf_tail_call结合使用,此映射允许你在程序之间跳转,绕过单个BPF程序的最大指令限制并降低复杂性。
使用此专用映射时需要考虑一些事项。要记住的第一个方面是键和值的大小都必须是四个字节。要记住的第二个方面是,当你跳转到一个新程序时,新程序将重用相同的内存堆栈,因此程序不会消耗所有可用内存。最后,如果你尝试跳转到映射中不存在的程序,则尾调用将失败,当前程序将继续执行。让我们深入研究一个详细的示例,以了解如何更好地使用这种类型的映射:
1 | struct bpf_map_def SEC("maps") programs = { |
首先,我们需要声明我们的新程序映射(正如我们前面提到的,键和值的大小总是四个字节)
1 | intkey=1; |
我们需要声明我们要跳转到的程序。 在这种情况下,我们正在编写一个BPF程序,其唯一目的是返回0。我们使用bpf_prog_load将其加载到内核中,然后将其文件描述符标识符添加到我们的程序映射中。
现在我们已经存储了该程序,我们可以编写另一个将跳转到它的BPF程序。 BPF程序只有在同类型的情况下才能跳转到其他程序,在这种情况下,我们将程序附加到kprobe跟踪
1 | SEC("kprobe/seccomp_phase1") |
使用bpf_tail_call和BPF_MAP_TYPE_PROG_ARRAY最多可以链接 32 个嵌套调用。 这样可以防止无限循环和内存耗尽。
Perf事件数组映射
这些类型的映射将perf_events数据存储在环形缓冲区中,该环形缓冲区在BPF程序和用户空间程序之间进行实时通信。 它们使用BPF_MAP_TYPE_PERF_EVENT_ARRAY类型定义。 旨在将内核跟踪工具发出的事件转发给用户空间程序以做进一步处理。用户空间程序充当监听器,等待来自内核的事件,因此你需要确保你写的代码在内核中的BPF程序初始化之前开始监听。
让我们看一个示例,说明如何跟踪计算机执行的所有程序。 在进入BPF程序代码之前,我们需要声明我们将从内核发送到用户空间的事件结构:
1 | struct data_t { |
现在,我们需要创建将事件发送到用户空间的映射:
1 | struct bpf_map_def SEC("maps") events = { |
在我们声明了数据类型和映射后,我们可以创建捕获数据并将其发送到用户空间的BPF程序:
1 | SEC("kprobe/sys_exec") |
在此代码段中,我们使用bpf_perf_event_output将数据附着到map中。 因为这是一个实时缓冲区,所以你不必担心map中元素的键,内核负责将新元素添加到map并在用户空间程序处理它后刷新它。
Per-CPU哈希映射
这种类型的映射是BPF_MAP_TYPE_HASH的改进版本。 这些映射使用BPF_MAP_TYPE_PERCPU_HASH类型定义。 当你分配其中一个映射时,每个CPU都会看到它自身隔离版本的映射,这使得高性能查找和聚合更加高效。 如果你的BPF程序收集指标并将它们聚合到哈希表映射中,使用这种类型的映射就很有用。
Per-CPU数组映射
这种类型的地图也是BPF_MAP_TYPE_ARRAY的改进版本。 它们使用BPF_MAP_TYPE_PERCPU_ARRAY类型定义。
堆栈跟踪映射
这种类型的映射存储正在运行的进程的堆栈跟踪。 它们使用BPF_MAP_TYPE_STACK_TRACE类型定义。 除了这个映射,内核开发人员已经添加了帮助程序bpf_get_stackid来帮助你使用堆栈跟踪填充这个映射。此帮助程序将映射作为参数和一系列标志,以便你可以指定是否只需要来自内核、只来自用户空间或两者的跟踪。帮助器返回与添加到map中的元素关联的键。
Cgroup数组映射
这种类型的映射存储对cgroups的引用。Cgroup数组映射使用BPF_MAP_TYPE_CGROUP_ARRAY类型定义。 本质上,它们的行为类似于BPF_MAP_TYPE_PROG_ARRAY,但它们存储指向cgroup的文件描述符标识符。
当你希望在BPF map之间共享cgroup引用以控制流量、调试和测试时,该映射会非常有用。 让我们看一个如何填充此映射的示例。 我们从映射定义开始:
1 | struct bpf_map_def SEC("maps") cgroups_map = { |
我们可以通过打开包含cgroup信息的文件来拿到cgroup的文件描述符。 我们将打开控制Docker容器的基本CPU额度的cgroup,并将该cgroup存储在我们的映射中:
1 | int cgroup_fd, key = 0; |
LRU哈希和Per-CPU哈希映射
这两种类型的映射是哈希表映射,但它们也实现了内部LRU缓存。 LRU代表最近最少使用,这意味着如果映射已满,这些映射将删除不经常使用的元素,以便为映射中的新元素腾出空间。 因此,你可以使用这些映射来插入超出最大限制的元素,只要不介意丢失最近未使用的元素。 它们使用BPF_MAP_TYPE_LRU_HASH和BPF_MAP_TYPE_LRU_PERCPU_HASH类型定义。
此映射的per cpu版本与之前看到的其他per cpu映射略有不同。 该映射只保留一个哈希表来存储映射中的所有元素,并且每个CPU使用不同的LRU缓存,这样可以确保每个CPU中最常用的元素保留在映射中。
LPM Trie映射
LPM trie映射是使用最长前缀匹配(LPM)来查找映射中元素的映射类型。LPM是一种算法,它从树中的任何其他匹配项中选择与最长查找键匹配的元素。此算法用于保留流量转发表以将IP地址与特定路由的路由器和其他设备进行匹配。 这些映射使用BPF_MAP_TYPE_LPM_TRIE类型定义。
这些映射要求key的大小为8的倍数,范围为8到2048。 如果你不想实现自己的key,内核提供了一个结构体,可以将其用于这些keys,称为bpf_lpm_trie_key。
在下一个示例中,我们将两个转发路由添加到映射并尝试将IP地址匹配到正确的路由。 首先我们需要创建映射:
1 | struct bpf_map_def SEC("maps") routing_map = { |
我们将使用三个转发路由填充此映射: 192.168.0.0/16、192.168.0.0/24 和 192.168.1.0/24:
1 | uint64_t value_1 = 1; |
现在,我们使用相同的keys结构来查找IP地址192.168.1.1/32的正确匹配:
1 | uint64_t result; |
在此示例中,192.168.0.0/16和192.168.1.0/24都可以匹配查找IP,因为该IP都在这两个范围内。 但是,由于该映射使用LPM 算法,结果将填充键为192.168.1.0/24的值。
数组映射和哈希映射
BPF_MAP_TYPE_ARRAY_OF_MAPS和BPF_MAP_TYPE_HASH_OF_MAPS是存储对其它映射的引用的两种类型的映射。 它们仅支持一级间接引用,因此不能使用它们来存储映射的映射的映射。 这可确保不会因意外存储无限链式映射而消耗所有内存。
当你希望在运行时替换整个映射时,这些类型的映射很有用。 如果你的所有映射都是全局映射的子集,那么可以创建全状态快照。 内核确保父映射中的任何更新操作都等到所有旧的子映射的引用都被删除后才完成操作。
Device Map映射
这种特殊类型的映射存储对网络设备的引用。这些映射使用BPF_MAP_TYPE_DEVMAP类型定义。 它们对想在内核级别操纵流量的网络应用程序很有用。你可以构建指向特定网络设备的端口虚拟映射,然后使用帮助器bpf_redirect_map重定向数据包。
CPU Map映射
BPF_MAP_TYPE_CPUMAP是另一种允许转发网络流量的映射。在这种情况下,映射存储对主机中不同CPU的引用。 与之前的映射类型一样,你可以将其与bpf_redirect_map帮助程序一起使用来重定向数据包。但是,此映射将数据包发送到不同的CPU。这允许将特定CPU分配给网络堆栈以实现可扩展性和隔离目的。
Open Socket映射
BPF_MAP_TYPE_XSKMAP是一种存储对打开套接字的引用的映射。 与之前的映射一样,这些映射对于套接字之间转发数据包很有用。
Socket Array和Hash映射
BPF_MAP_TYPE_SOCKMAP和BPF_MAP_TYPE_SOCKHASH是两个专门的映射,它们存储对内核中打开套接字的引用。 与前面的映射一样,这种类型的映射与帮助程序bpf_redirect_map一起使用,将套接字缓冲区从当前XDP程序转发到不同的套接字。
它们的主要区别在于其中一个使用数组来存储套接字,而另一个使用哈希表。使用哈希表的好处是你可以直接通过它的键访问一个套接字,而不需要遍历完整的映射来找到它。内核中的每个套接字都由一个五元组键标识。 这五个元组包含建立双向网络连接所需的信息。 当使用此映射的哈希表版本时,你可以将此键用作映射中的查找键。
Cgroup Storage and Per-CPU Storage映射
引入这两种类型的映射是为了帮助开发人员使用附着到cgroup的BPF程序。 你可以将BPF程序与控制组连接和分离,并使用BPF_PROG_TYPE_CGROUP_SKB将它们的运行时隔离到特定的cgroup。 这两个映射使用 BPF_MAP_TYPE_CGROUP_STORAGE和BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE类型定义。
从开发人员的角度来看,这些类型的映射类似于哈希表映射。内核提供了一个结构助手来为这个映射生成键,bpf_cgroup_storage_key,其中包括有关cgroup节点标识符和附加类型的信息。 你可以在此映射中添加任何想要的值,它的访问权限将仅限于附加cgroup内的BPF程序。
这些映射有两个限制。首先是你不能从用户空间在映射中创建新元素。内核中的BPF程序可以使用bpf_map_update_elem创建元素,但是如果你在用户空间使用此方法并且key不存在,则 bpf_map_update_elem将失败,并且errno将被设置为ENOENT。 第二个限制是你不能从此映射中删除元素。bpf_map_delete_elem总是失败并将errno设置为EINVAL。
这两种类型的映射之间的主要区别是BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE为每个CPU保留不同的哈希表。
Reuseport Socket映射
这种特殊类型的映射存储对系统中的开放端口重用的套接字的引用。它们使用BPF_MAP_TYPE_REUSE PORT_SOCKARRAY类型定义。这些映射主要用于BPF_PROG_TYPE_SK_REUSEPORT程序类型。 结合起来,你可以控制决定如何过滤和处理来自网络设备的传入数据包。例如,可以决定哪些数据包发送到哪个套接字,即使两个套接字都连接到同一个端口。
Queue映射
队列映射使用先进先出(FIFO)存储将元素保留在映射中。它们使用BPF_MAP_TYPE_QUEUE类型定义。FIFO意味着当从映射中获取元素时,结果将是映射中存在时间最长的元素。
对于这种数据结构,bpf映射帮助器以一种可预测的方式工作。当使用bpf_map_lookup_elem时,此映射始终在映射中查找最旧的元素。 当使用bpf_map_update_elem时,此映射始终将元素附加到队列的末尾,因此你需要先读取映射中的其余元素,然后才能获取此元素。 当然你还可以使用帮助程序bpf_map_lookup_and_delete获取较旧的元素并以原子方式将其从映射中删除。此映射不支持帮助函数bpf_map_delete_elem和bpf_map_get_next_key。 如果尝试使用它们,它们将失败并将errno变量设置为EINVAL。
关于这些类型的映射,需要记住的是它们不使用映射键进行查找,并且在初始化这些映射时键大小必须始终为 0。 当你将元素推送到这些映射时,键必须是空值。
接下来看一个如何使用这类映射的例子:
1 | struct bpf_map_def SEC("maps") queue_map = { |
接着我们在这个映射中插入几个元素,并按照我们插入的顺序检索它们:
1 | int i; |
程序输出如下
1 | Value read from the map: '0' |
如果我们再尝试从映射中弹出一个新元素,bpf_map_lookup_and_delete将返回一个负数,并且errno变量将设置为ENOENT。
Stack映射
堆栈映射使用先进后出 (FILO)存储将元素保留在映射中。 它们使用BPF_MAP_TYPE_STACK类型定义。 FILO意味着当你从映射中获取元素时,结果将是最近添加到映射中的元素。
对于这种数据结构,bpf映射助手也以可预测的方式工作。当你使用bpf_map_lookup_elem时,此映射总是寻找最新的元素。当你使用bpf_map_update_elem时,此映射始终将元素附加到堆栈顶部,因此它是第一个获取的元素。你还可以使用帮助程序bpf_map_lookup_and_delete获取最新元素并以原子方式将其从映射中删除。此映射不支持帮助函数bpf_map_delete_elem和bpf_map_get_next_key。 如果你尝试使用它们,它们将始终失败并将 errno变量设置为EINVAL。
接下来看一个如何使用这类映射的例子:
1 | struct bpf_map_def SEC("maps") stack_map = { |
接着我们在这个映射中插入几个元素,并按照我们插入的顺序检索它们:
1 | int i; |
程序输出如下
1 | Value read from the map: '4' |
如果我们再尝试从映射中弹出一个新元素,bpf_map_lookup_and_delete将返回一个负数,并且errno变量将设置为ENOENT。
正如我们前面提到的,BPF映射作为常规文件存储在你的操作系统中。但是我们还没有讨论内核用来保存映射和程序的文件系统的具体特征。下一部分将介绍BPF文件系统,以及可以从中获得的持久性类型。
BPF虚拟文件系统
BPF映射的一个基本特征是基于文件描述符,这意味着当一个描述符关闭时,映射和它所保存的所有信息都会消失。BPF映射的最初实现专注于时间短且隔离的程序,它们之间不共享任何信息。在这些情况下,当文件描述符关闭时擦除所有数据很有意义。然而,随着内核中引入更复杂的映射和集成,其开发人员意识到他们需要一种方法来保存映射所持有的信息,即使在程序终止并关闭映射的文件描述符之后也是如此。Linux内核4.4版引入了两个新的系统调用,允许从虚拟文件系统固定和获取映射和BPF程序。 固定到该文件系统的Map和BPF程序将在创建它们的程序终止后保留在内存中。 在本节中,我们将解释如何使用这个虚拟文件系统。
BPF虚拟文件系统的默认目录是/sys/fs/bpf,一些Linux发行版默认不挂载这个文件系统,因为它们假设内核不支持BPF。你可以使用mount命令自行挂载
1 | mount -t bpf /sys/fs/bpf /sys/fs/bpf |
与其他文件层次结构一样,文件系统中的BPF持久化对象由路径标识。你可以以任何方式组织这些路径使得程序有意义。例如,如果你想在程序之间共享带有IP信息的特定映射,你可以将其存储在/sys/fs/bpf/shared/ips中。正如我们前面提到的,有两种类型的对象可以保存在这个文件系统中:BPF映射和完整的BPF程序。这两者都由文件描述符标识,因此使用它们的接口是相同的。 这些对象只能由bpf系统调用操作。 尽管内核提供了高级助手来帮助你与它们交互,但是不能做诸如尝试使用open系统调用打开这些文件之类的操作。
BPF_PIN_FD是在这个文件系统中保存BPF对象的命令。当命令成功时,该对象将在你指定的路径中的文件系统中可见。如果命令失败,则返回一个负数,并使用错误代码设置全局errno变量。
BPF_OBJ_GET是获取已固定到文件系统的BPF对象的命令。 此命令使用你分配的对象路径来加载它。 当此命令成功时,它会返回与对象关联的文件描述符标识符。 如果失败,则返回一个负数,并使用特定的错误代码设置全局errno变量。
让我们看一个例子,说明如何使用内核提供的辅助函数在不同的程序中利用这两个命令。首先,我们要编写一个程序来创建一个映射,用几个元素填充它,并将它保存在文件系统中:
map_pinning_save.c程序如下
1 |
|
首先,我们创建一个固定大小元素的哈希表映射。 然后我们更新映射以仅添加该元素。 如果我们尝试添加更多元素,bpf_map_update_elem将会失败,因为映射会溢出。
我们使用辅助函数bpf_obj_pin将映射保存在文件系统中。
Makefile程序如下
1 | CLANG = clang |
执行程序前查看/sys/fs/bpf路径下的目录
1 | [root@VM-16-14-centos cpt2]# ls -la /sys/fs/bpf/ |
开始执行该程序
第一步执行make save
1 | [root@VM-16-14-centos cpt2]# make save |
第二步执行生成的可执行文件
1 | [root@VM-16-14-centos cpt2]# ./save |
在程序执行结束后,再次检查该路径下是否有一个新文件:
1 | [root@VM-16-14-centos cpt2]# ls -la /sys/fs/bpf/ |
接着我们可以编写一个类似的程序,从文件系统加载该映射并打印我们插入的元素。 这样我们就可以验证是否正确保存了映射:
map_pinning_fetch.c程序如下
1 |
|
编译并执行,结果如下
1 | [root@VM-16-14-centos cpt2]# make fetch |
将BPF对象保存在文件系统中使得数据和程序不再依赖于单个执行线程。信息可以由不同的应用程序共享,BPF程序甚至可以在创建它们的应用程序终止后运行。这为它们提供了额外的级别或可用性,如果没有BPF文件系统,完成这些操作是不可能的。
结论
在内核和用户空间之间建立通信通道是充分利用BPF程序的基础。 在本章中,我们学习了如何创建BPF映射来建立这种通信以及如何使用它们。我们还描述了可以在程序中使用的映射类型。 接着我们学习到了更具体的映射示例。最后我们学习了如何将整个映射固定到系统中,以使得它们所保存的信息能够经受住崩溃和中断的影响。
BPF映射是内核和用户空间之间通信的中心总线。在本章中,我们建立了理解它们所需的基本概念。在下一章中,我们将更广泛地使用这些数据结构来共享数据。我们还会介绍一些其他工具,这些工具将使BPF映射的使用更加高效。
在下一章中将看到BPF程序和映射如何协同工作,从内核的角度为你提供系统上的跟踪功能。 我们探索了将程序附加到内核中不同入口点的不同方法。最后,我们将介绍如何以一种使应用程序更易于调试和观察的方式表示多个数据点。
第四章节
使用 BPF 进行跟踪
在软件工程领域,跟踪是一种通过收集数据进行分析和调试的方法。目标是在运行时提供有用的信息以供将来分析。使用BPF进行跟踪的主要优点是可以访问来自Linux内核和应用程序的任何信息。与其他跟踪技术相比,BPF减少了系统性能和延迟,并且不需要开发人员为了从应用程序收集数据而修改他们的应用程序。
Linux内核提供了多种可与BPF结合使用的检测功能。在本章我们将讨论这些不同的功能。我们将展示内核如何在操作系统中暴露这些功能,以便你知道如何找到可用于BPF程序的信息。
跟踪的最终目标是通过获取所有可用数据并以有用的方式呈现,从而让你更加深入的了解系统。 我们将讨论几种不同的数据表示以及如何在不同的场景中使用它们。
从本章开始,我们将使用一种强大的工具包来编写BPF程序,BPF编译收集器(BCC)。BCC 是一组使构建BPF程序更可预测的组件。即使你掌握了Clang和LLVM,你也不想花费不必要的时间来构建相同的实用程序,除此之外还要确保BPF验证器不会拒绝你编写的程序。BCC为常见结构(如Perf事件映射)提供可重用组件,并与LLVM后端集成以提供更好的调试选项。最重要的是,BCC包括多种编程语言的绑定, 我们将在示例中使用Python。 这些绑定允许你用高级语言编写BPF程序的用户空间部分,从而产生更有用的程序。我们还在后面的章节中使用BCC来使示例代码更加简洁。
BCC工具安装
1 | yum install bcc-tools |
BCC工具安装在/usr/share/bcc/tools/目录中。
1 | [root@VM-16-14-centos ~]# ll /usr/share/bcc/tools/ |
能够在Linux内核中跟踪程序的第一步是确定它为你提供的附加BPF程序的扩展点。这些扩展点通常称为探针(probes)。
探针
英语词典中对探针一词的定义之一如下:
一种无人探索航天器,旨在传输有关其环境的信息。
这个定义在我们脑海中唤起了对科幻电影和史诗般的NASA任务的回忆。 当我们谈论跟踪探针时,我们可以使用非常相似的定义。
跟踪探针是探索性程序,旨在传输有关执行它们的环境的信息。
他们在你的系统中收集数据,供你探索和分析。传统上,在Linux中使用探针涉及编写编译到内核模块中的程序,这可能会导致生产系统中的灾难性问题。多年来,它们发展到执行起来很安全,但编写和测试仍然很麻烦。像SystemTap这样的工具建立了新的协议来编写探针。
BPF搭载跟踪探测来收集信息以进行调试和分析。BPF程序的安全性使得它们比依赖重新编译内核的工具更有吸引力。重新编译内核以包含外部模块可能会引起由于代码行为不当而导致崩溃的风险。BPF验证器通过在加载到内核之前分析程序来消除这种风险。BPF开发人员利用探针定义并修改内核,从而当代码执行找到其中一个定义时执行的是BPF程序而不是内核模块。
了解可以定义的不同类型的探针对于探索系统中发生的事情至关重要。在本节中,我们对不同的探针定义进行分类,如何在系统中发现它们,以及如何将BPF程序附着到它们。
在本章中,我们介绍了四种不同类型的探针:
Kernel probes
这些使您可以动态访问内核中的内部组件
Tracepoints
这些提供对内核内部组件的静态访问
User-space probes
这些使您可以动态访问在用户空间中运行的程序
User statically defined tracepoints
这些允许静态访问在用户空间中运行的程序
接下来让我们从内核探针开始详细的学习
Kernel probes
内核探针允许你在几乎任何内核指令中以最小的开销设置动态标志或中断。当内核到达这些标志之一时,它会执行附加到探针的代码,然后恢复其正常例程。内核探针可以为你提供有关系统中发生的任何事情的信息,例如系统中打开的文件和正在执行的二进制文件。关于内核探针需要记住的重要一点是它们没有稳定的应用程序二进制接口 (ABI),这意味着它们可能会在内核版本之间发生变化。如果你尝试将相同的探测器附加到具有两个不同内核版本的两个系统,则相同的代码可能会停止工作。
内核探针分为两类:kprobes和kretprobes。 它们的使用取决于你在执行周期中插入BPF程序的位置。 本节将指导你如何使用它们中的每一个将BPF程序附加到这些探针并从内核中提取信息。
Kprobes
Kprobes允许你在执行任何内核指令之前插入BPF程序。你需要知道你想要破解的函数签名,正如我们之前提到的,这不是一个稳定的ABI,所以如果你要运行相同的程序,你需要在不同的内核版本中小心设置这些探针。 当内核执行到达你设置探针的指令时,它会避开你的代码,运行你的BPF程序,并将执行返回到原始指令。
为了展示如何使用kprobes,我们将编写一个BPF程序,该程序打印系统中执行的任何二进制文件的名称。在本例中,我们将为BCC工具使用Python前端,但你可以使用任何其他BPF工具编写它:
kprobes.py代码如下
1 | from bcc import BPF |
1:BPF程序开始执行,辅助函数bpf_get_current_comm将获取内核正在运行的当前命令的名称,并将其存储在我们的comm变量中。我们将其定义为固定长度数组,因为内核对命令名称有16个字符的限制。获得命令名称后,我们将其打印在调试跟踪中,这样运行Python脚本的人就可以看到BPF捕获的所有命令。
2:加载BPF程序到内核中
3:将程序与execve系统调用相关联。这个系统调用的名称在不同的内核版本中发生了变化,并且BCC提供了一个函数来检索这个名称,而无需记住你正在运行的内核版本。
4:该代码输出跟踪日志,因此你可以看到使用该程序跟踪的所有命令。
执行结果如下
1 | [root@VM-16-14-centos cpt3]# python3 kprobes.py |
Kretprobes
当内核指令在执行后返回一个值时,Kretprobes将插入你的BPF程序。通常,你会希望将kprobes和kretrobes组合到一个BPF程序中,以便全面了解指令的行为。
我们将使用与上一节中的示例类似的示例来展示kretprobes的工作原理:
kretprobes.py代码如下
1 | from bcc import BPF |
1:定义实现BPF程序的函数。 内核将在execve系统调用完成后立即执行它。 PT_REGS_RC是一个宏,它将从BPF寄存器中读取此特定上下文的返回值。我们还使用bpf_trace_printk在调试日志中打印命令及其返回值
2:初始化BPF程序并将其加载到内核中
3:将附着函数更改为attach_kretprobe
执行结果如下
1 | [root@VM-16-14-centos cpt3]# python3 kretprobes.py |
内核探针是访问内核的一种强大方法。但正如我们之前提到的,它们可能不太稳定,因为你附着到内核源代码中的动态点,这些动态点可能会从一个版本更改或消失到另一个版本。因此我们需要一种更安全的将程序附着到内核的方法。
Tracepoints
跟踪点是内核代码中的静态标记,可用于将代码附着到正在运行的内核中。与kprobe的主要区别在于,它们是由内核开发人员在实现内核更改时编写的;这就是为什么我们将它们称为静态的。因为它们是静态的,所以跟踪点的ABI更稳定;内核始终保证旧版本中的跟踪点将存在于新版本中。但是,鉴于开发人员需要将它们添加到内核中,它们可能不会涵盖构成内核的所有子系统。
正如我们在之前提到的,你可以通过列出/sys/kernel/debug/tracing/events中的所有文件来查看系统中所有可用的跟踪点。
该输出中列出的每个子目录都对应一个跟踪点,我们可以将BPF程序附着到该跟踪点。但是那里还有两个附加文件。enable文件允许你启用和禁用BPF子系统的所有跟踪点。 如果文件内容为0,则禁用跟踪点;如果文件的内容为1,则启用跟踪点。filter文件允许你编写内核中的Trace子系统将用于过滤事件的表达式。
编写BPF程序利用跟踪点类似于使用kprobes进行跟踪。 这是一个使用BPF程序来跟踪系统中加载其他BPF程序的所有应用程序的示例:
1 | from bcc import BPF |
1:声明定义BPF程序的函数
2:该程序的主要区别在于:我们不是将程序附着到kprobe,而是将其附着到跟踪点。 BCC遵循命名跟踪点的约定; 首先,需要指定要跟踪的子系统(在本例中为bpf),后跟一个冒号,然后是子系统中的跟踪点 pbf_prog_load。 这意味着每次内核执行函数bpf_prog_load时,这个程序都会接收到事件,并打印出正在执行 bpf_prog_load指令的应用程序的名称。
内核探针和跟踪点使你能够完全访问内核。我们建议你尽可能使用跟踪点,但不要仅仅因为跟踪点更安全而坚持使用跟踪点。利用内核探针的动态特性。在下一节中,我们将讨论如何在用户空间运行的程序中获得类似级别的可见性。
User-Space Probes
用户空间探针允许你在用户空间运行的程序中设置动态标志。它们相当于内核探针,用于检测在内核外运行的程序。当你定义一个uprobe时,内核会在附加的指令周围创建一个陷阱。 当你的应用程序到达该指令时,内核会触发一个事件,该事件将你的探测函数作为回调函数。Uprobes还允许你访问程序链接到的任何库,如果你知道指令的正确名称,就可以跟踪这些调用。
像内核探针一样,用户空间探针也分为两类,uprobes和uretprobes,这取决于你在程序执行周期中插入BPF程序的位置。 让我们直接看一些例子。
uprobes
一般来说,uprobes是内核在执行特定指令之前插入到程序指令集中的钩子。将uprobes附加到同一程序的不同版本时需要小心,因为函数签名可能会在这些版本之间内部发生变化。保证BPF程序在两个不同版本中运行的唯一方法是确保签名没有更改。你可以在Linux中使用命令nm列出ELF目标文件中包含的所有符号,这是检查你正在跟踪的指令是否仍然存在程序中的好办法,例如:
main.go程序如下
1 | package main |
接着使用go build -o hello-bpf main.go编译这个Go程序。
1 | [root@VM-16-14-centos cpt3]# go build -o hello-bpf main.go |
最后使用命令nm获取有关二进制文件包含的所有指令点的信息。nm是GNU开发工具中包含的一个程序,它列出了目标文件中的符号。 如果你过滤名称中带有main的符号,会得到一个类似如下的列表:
1 | [root@VM-16-14-centos cpt3]# nm hello-bpf | grep main |
现在你有了一个符号列表,可以跟踪它们何时执行,甚至在执行相同二进制文件的不同进程之间。
为了跟踪我们之前的 Go 示例中的 main 函数何时执行,我们将编写一个 BPF 程序,并将其附加到一个 uprobe,该 uprobe 将在任何进程调用该指令之前中断:
uprobes.py程序如下
1 | from bcc import BPF |
1:使用函数bpf_get_current_pid_tgid来获取运行我们的hello-bpf程序的进程的进程标识符 (PID)。
2:将此程序附着到uprobe。 这个调用需要知道我们要跟踪的对象hello-bpf是对象文件的绝对路径。它还需要我们在对象内部跟踪的符号,在本例中为main.main,以及我们要运行的BPF程序。 这样,每当有人在我们的系统中运行hello-bpf时,我们都会在跟踪管道中获得一个新日志。
首先执行hello-bpf程序
1 | [root@VM-16-14-centos cpt3]# ./hello-bpf |
接着查看uprobes.py程序的输出
1 | [root@VM-16-14-centos cpt3]# python3 uprobes.py |
Uretprobes
Uretprobes是kretprobes的并行探针,但用于用户空间程序。它们将BPF程序附着到返回值的指令上,并让你通过访问BPF代码中的寄存器来访问这些返回值。
结合uprobes和uretprobes可以让你编写更复杂的BPF程序。 它们可以让你更全面地了解系统中运行的应用程序。当你可以在函数运行之前和完成后立即注入跟踪代码时,可以开始收集更多数据并测量应用程序行为。一个常见的用例是测量一个函数执行需要多长时间,而无需更改应用程序中的一行代码。
uretprobes.py程序如下
1 | from bcc import BPF |
首先执行hello-bpf程序
1 | [root@VM-16-14-centos cpt3]# ./hello-bpf |
接着查看uprobes.py程序的输出
1 | [root@VM-16-14-centos cpt3]# python3 uprobes.py |
User Statically Defined Tracepoints
用户静态定义的跟踪点(USDT)为用户空间中的应用程序提供静态跟踪点。这是一种检测应用程序的便捷方式,因为它们提供了BPF提供的跟踪功能的低开销入口点。你还可以将它们用作在生产中跟踪应用程序的约定,而不管这些应用程序是使用何种编程语言编写的。
USDT由DTrace推广,DTrace最初由Sun Microsystems开发,用于Unix系统的动态检测。 由于许可问题,DTrace直到最近才在Linux中可用;但是,Linux内核开发人员从DTrace的原始工作中获得了很多灵感来实现USDT。
就像之前看到的静态内核跟踪点一样,USDT要求开发人员使用指令来检测他们的代码,内核将使用这些指令作为陷阱来执行BPF程序。 USDT的Hello World版本只有几行代码:
hello_usdt.c程序如下
1 |
|
在这个例子中,我们使用Linux提供的宏来定义我们的第一个USDT。DTRACE_PROBE将注册内核将用于注入BPF函数回调的跟踪点。该宏中的第一个参数是报告跟踪的程序。第二个是我们报告跟踪的名称。
安装在系统中的许多应用程序都可能使用这种类型的探针,以便以一种可预测的方式访问运行时跟踪数据。例如,数据库MySQL使用静态定义的跟踪点公开各种信息。你可以从服务器中执行的查询以及许多其他用户操作中收集信息。Node.js是构建在Chrome V8引擎上的JavaScript运行时,同样提供了可用于提取运行时信息的跟踪点。
在展示如何将BPF程序附着到用户定义的跟踪点之前,我们需要先谈谈可发现性。因为这些跟踪点是在可执行文件中以二进制格式定义的,所以我们需要一种方法来列出程序定义的探针,而无需深入研究源代码。提取此信息的一种方法是直接读取ELF二进制文件。首先,我们将编译我们之前的Hello World USDT示例; 我们可以为此使用 GCC:
1 | gcc -o hello_usdt hello_usdt.c |
编译报错如下
1 | hello_usdt.c:1:10: fatal error: sys/sdt.h: No such file or directory |
报错解决如下
1 | [root@VM-16-14-centos cpt3]# yum install systemtap-sdt-devel |
上述gcc命令将生成一个名为hello_usdt的二进制文件,我们可以使用该文件开始使用多个工具来发现它定义的跟踪点。 Linux提供了一个名为readelf的实用程序来显示有关ELF文件的信息。 你可以将它与我们编译的示例一起使用,readelf可以提供有关二进制文件的大量信息
1 | [root@VM-16-14-centos cpt3]# readelf -n ./hello_usdt |
发现二进制文件中定义的跟踪点的更好选择是使用BCC的tplist工具,该工具可以显示内核跟踪点和USDT。这个工具的优点是它的输出简单;仅显示跟踪点定义,而没有关于可执行文件的任何其他信息。用法类似于readelf:
1 | [root@VM-16-14-centos cpt3]# /usr/share/bcc/tools/tplist -l ./hello_usdt |
它列出了你在单独的行中定义的每个跟踪点。在我们的示例中,它仅显示一行带有我们的probe-main定义:
在你知道二进制文件中支持的跟踪点之后,你可以将BPF程序附着到它们上,就像你在前面的例子中看到的那样:
usdt.py程序如下
1 | from bcc import BPF, USDT |
1:创建一个USDT对象; USDT不是BPF的一部分,因为你可以在无需与BPF虚拟机交互的情况下使用它们。因为它们彼此独立,所以它们的使用独立于BPF代码。
2:附着BPF函数以跟踪程序执行到我们应用程序中的探针
3:使用刚刚创建的跟踪点定义初始化BPF环境。 这将通知BCC需要生成代码来连接我们的BPF程序和二进制文件中的探针定义。当它们都连接时,我们可以打印BPF程序生成的跟踪,以发现二进制示例中最新的执行。
可视化跟踪数据
到目前为止,我们已经展示了在调试输出中打印数据的示例。这在生产环境中不是很有用。 没有人喜欢理解冗长而复杂的日志。如果我们想监控延迟和CPU利用率的变化,通过查看一段时间内的图表比汇总文件流中的数字更容易。
本节探讨呈现BPF跟踪数据的不同方式。一方面,我们将展示BPF程序如何构建聚合信息。另一方面,你将学习如何以便携式表示形式导出该信息,并使用现成的工具访问更丰富的表示形式并与其他人分享。
火焰图
火焰图是帮助你可视化系统花费时间的图表。它们可以让你清楚地表示应用程序中的哪些代码执行得更频繁。火焰图的创建者Brendan Gregg维护了一组脚本,可以在GitHub上轻松生成这些可视化格式。我们使用这些脚本从本节后面使用BPF收集的数据生成火焰图。
关于火焰图显示的内容,需要记住两件重要的事情:
- x轴按字母顺序排列。每个堆栈的宽度表示它在收集数据中出现的频率,这可以与启用探查器时访问该代码路径的频率相关。
- y 轴显示在分析器读取堆栈跟踪时排序,保留跟踪层次结构。
最著名的火焰图代表了系统中最频繁消耗CPU的代码;这些被称为CPU图。另一个有趣的火焰图可视化是CPU外图;它们代表CPU在与应用程序无关的其他任务上花费的时间。通过组合on-CPU和off-CPU图表,可以全面了解系统花费CPU周期的内容。
CPU内和CPU外图都使用堆栈跟踪来指示系统花费时间的位置。 一些编程语言,如Go,总是在其二进制文件中包含跟踪信息,但其他编程语言,如 C++ 和Java,需要一些额外的工作才能使堆栈跟踪可读。在你的应用程序包含堆栈跟踪信息后,BPF程序可以使用它来聚合内核看到的最常见的代码路径。
内核中的堆栈跟踪聚合有优点也有缺点。一方面,这是一种计算堆栈跟踪频率的有效方法,因为它发生在内核中,避免将每个堆栈信息发送到用户空间并减少内核和用户空间之间的数据交换。另一方面,非CPU图表要处理的事件数量可能会非常高,因为你正在跟踪应用程序上下文切换期间发生的每个事件。如果尝试对其进行分析太长时间,这可能会在系统中产生大量开销。 使用火焰图时请记住这一点。
BCC提供了几个实用程序来帮助聚合和可视化堆栈跟踪,主要的是宏BPF_STACK_TRACE。 这个宏生成一个BPF_MAP_TYPE_STACK_TRACE类型的BPF映射来存储BPF程序累积的堆栈。最重要的是,这个BPF映射得到了增强,增加了从程序上下文中提取堆栈信息的方法,并在聚合它们后在你想使用它们时遍历累积的堆栈跟踪。
在下一个示例中,我们构建了一个简单的BPF分析器,它打印从用户空间应用程序收集的堆栈跟踪。我们使用分析器收集的轨迹生成CPU上的火焰图。为了测试这个分析器,我们将编写一个生成CPU负载的最小Go程序。main.go程序代码如下所示
1 | package main |
如果将此代码保存在名为main.go的文件中并使用go run main.go运行它您会看到系统的CPU利用率显着增加。 你可以通过按键盘上的Ctrl-C来停止执行,CPU利用率将恢复正常。
我们BPF程序的第一部分将初始化分析器结构:
1 | bpf_source = """ |
1:初始化一个结构,该结构将存储我们的分析器接收到的每个堆栈帧的引用标识符。 稍后我们使用这些标识符来找出当时正在执行的代码路径。
2:初始化一个BPF哈希映射,我们用它来聚合我们看到相同strack帧的频率。 火焰图脚本使用此聚合值来确定执行相同代码的频率。
3:初始化我们的BPF堆栈跟踪映射。 我们为此地图设置了最大尺寸,但它可能会根据要处理的数据量而有所不同。将这个值作为变量会更好,但我们知道写的Go应用程序不是很大,所以10000个元素就足够了。
接下来,我们在分析器中实现聚合堆栈跟踪的函数:
1 | bpf_source += """ |
1:验证当前BPF上下文中程序的进程ID是不是我们的Go应用程序的进程ID;否则,我们将忽略该事件。我们目前还没有定义PROGRAM_PID的值。在初始化BPF程序之前,让我们在分析器的Python部分替换这个字符串。这是BCC初始化BPF程序方式的当前限制;我们不能从用户空间传递任何变量,并且作为一种常见的做法,这些字符串在初始化之前在代码中被替换。
2:创建跟踪以汇总其使用情况。我们使用内置函数get_stackid从程序上下文中获取堆栈ID。 这是BCC添加到我们的堆栈跟踪映射的辅助函数之一。我们使用标志BPF_F_USER_STACK来表示我们想要获取用户空间应用程序的堆栈ID,我们并不关心内核内部发生了什么。
3:增加跟踪的计数器以跟踪相同代码的执行频率。
接下来,我们要将堆栈跟踪收集器附加到内核中的所有Perf事件:
1 | program_pid = int(sys.argv[1]) 1 |
1:Python程序的第一个参数是我们正在分析的Go应用程序的进程标识符。
2:使用Python的内置替换函数将BPF源中的字符串PROGRAM_ID与提供给分析器的参数交换。
3:将BPF程序附加到所有软件Perf事件,这将忽略任何其他事件,如硬件事件。我们还将BPF程序配置为使用CPU时钟作为时间源,这样我们就可以测量执行时间。
最后,我们需要实现在分析器中断时将堆栈跟踪转储到标准输出中的代码:
1 | try: |
1:遍历我们收集的所有跟踪,以便我们可以按顺序打印它们。
2:验证我们是否获得了堆栈标识符,我们可以稍后将其与特定的代码行相关联。如果我们得到一个无效值,我们将在火焰图中使用一个占位符。
3:以相反的顺序遍历堆栈跟踪中的所有条目。我们这样做是希望在顶部看到最近执行的第一个代码路径,就像在任何堆栈跟踪中所期望的那样。
4:使用BCC帮助程序符号将堆栈帧的内存地址转换为我们源代码中的函数名称。
5:格式化以分号分隔的堆栈跟踪行。这是火焰图脚本希望能够生成我们的可视化的格式。
完整的profiler.py程序如下
1 | #!/usr/bin/python |
随着我们的BPF分析器完成,我们可以将它运行以收集我们Go程序的堆栈跟踪。 我们需要将Go程序的进程ID传递给我们的分析器,以确保我们只收集此应用程序的跟踪;我们可以使用pgrep找到该PID。
首先我们需要将Go程序运行起来
1 | [root@VM-16-14-centos flamegraph]# go run main.go |
如果你将探测器保存在名为profiler.py的文件中,下面就是运行探测器的方式:
1 | [root@VM-16-14-centos flamegraph]# python3 profiler.py `pgrep -nx go` > /tmp/profile.out |
pgrep将在PID中搜索名称与go匹配的系统上运行的进程。我们将分析器的输出发送到一个临时文件,以便我们可以生成火焰图可视化。
正如我们之前提到的,我们将使用Brendan Gregg的`FlameGraph脚本为我们的图生成一个SVG文件; 你可以在GitHub中找到这些脚本。 下载后可以使用 flamegraph.pl 生成图。
1 | [root@VM-16-14-centos FlameGraph]# ./flamegraph.pl /tmp/profile.out > /tmp/flamegraph.svg |
使用浏览器打开图片如下
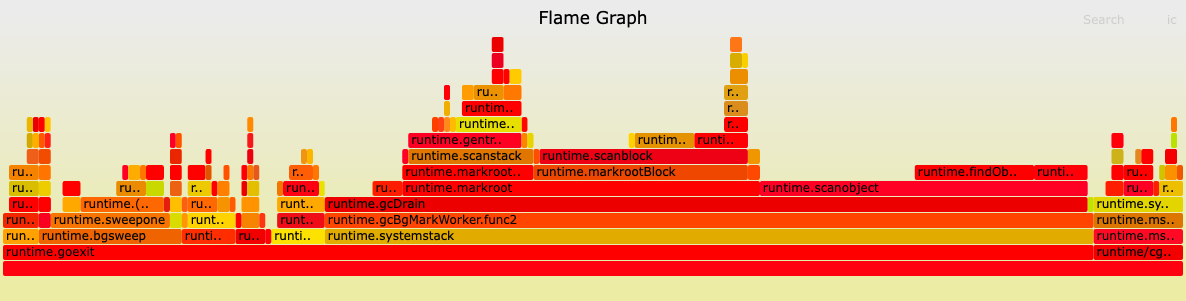
这种探查器对于跟踪系统中的性能问题很有用。 BCC已经包含一个比我们示例中的更高级的分析器,可以直接在生产环境中使用。除了分析器之外,BCC还包括了帮助生成CPU外火焰图和许多其他可视化来分析系统的工具。
直方图
直方图是显示多个值范围出现频率的图表。表示这一点的数字数据被分成桶,每个桶包含桶内任何数据点的出现次数。直方图测量的频率是每个桶的高度和宽度的组合。如果桶被分成相等的范围,这个频率匹配直方图的高度,但如果范围没有被平均划分,你需要将每个高度乘以每个宽度来找到正确的频率。
直方图是进行系统性能分析的基本组成部分。它们是表示可测量事件(如指令延迟)分布的绝佳工具,因为它们显示的信息比通过其他测量(如平均值)获得的更准确。
BPF程序可以基于许多指标创建直方图。你可以使用BPF图来收集信息,将其分类到桶中,然后为你的数据生成直方图表示。实现这个逻辑并不复杂,但是如果每次需要分析程序的输出时都想打印直方图就会变得乏味。BCC包含一个开箱即用的实现,可以在每个程序中重复使用,而无需每次手动计算分桶和频率。
作为一个有趣的实验,我们将展示如何使用BCC的直方图来可视化应用程序调用bpf_prog_load指令时加载BPF程序所引入的延迟。我们使用kprobes来收集该指令完成所需的时间,并将结果累积在一个直方图中,稍后我们将对其进行可视化。为了便于理解,我们将这个示例分成了几个部分。
第一部分包括了BPF程序的初始化
1 | bpf_source = """ |
1:使用宏创建BPF哈希映射来存储触发bpf_prog_load指令的初始时间。
2:使用新的宏创建BPF直方图。这不是原生BPF映射;BCC包含此宏,以便让你更轻松地创建这些可视化。在底层,这个BPF直方图使用数组映射来存储信息。它还有几个助手来进行分桶并创建最终图。
3:当应用程序触发我们要跟踪的指令时,使用程序 PID 来存储。
让我们看看我们如何计算延迟的增量并将其存储在我们的直方图中。
1 | bpf_source += """ |
1:计算指令被调用的时间和我们的程序到达这里的时间之间的增量; 我们可以假设这也是指令完成的时间。
2:将该增量存储在我们的直方图中。我们在这条线上做了两个操作。 首先,我们使用内置函数bpf_log2l为 delta的值生成桶标识符。此功能会随着时间的推移创建稳定的值分布。然后,我们使用增量函数向这个桶中添加一个新项目。默认情况下,如果直方图中存在bucket,则increment会将该值加1,否则会启动一个值为1的新bucket,因此无需担心该值是否存在。
我们需要编写的最后一段代码将这两个函数附加到有效的kprobe上,并在屏幕上打印直方图,以便我们可以看到延迟分布。这部分是我们初始化BPF程序并等待事件生成直方图的地方:
1 | bpf = BPF(text=bpf_source) |
正如我们在本节开头提到的,直方图可用于观察系统中的异常情况。BCC工具包括许多使用直方图表示数据的脚本。需要深入了解系统时可以查看它们。
histogram.py完整代码如下所示
1 | import sys |
Perf Events
我们相信Perf事件可能是成功使用BPF跟踪所需掌握的最重要的通信方法。我们在前一章中讨论了BPF Perf事件数组映射。它们允许你将数据放入与用户空间程序实时同步的环形缓冲区中。当你在BPF程序中收集大量数据,并希望将处理可视化工作转移到用户空间程序时,这是一个理想的选择。这将允许你对表示层进行更多控制,因为在编程能力方面不受BPF虚拟机的限制。你可以找到的大多数BPF跟踪程序的目的是使用Perf事件。
这里我们将展示如何使用它们提取有关二进制执行的信息,并对这些信息进行分类,以打印系统中执行最多的二进制文件。我们已将此示例分为两个代码块,以便你可以轻松地了解此示例。在第一块中,我们定义BPF程序并将其附加到kprobe:
1 | bpf_source = """ |
1:使用BPF_PERF_OUTPUT输出声明Perf事件映射。这是BCC提供的用于声明此类映射的宏。我们将此映射命名为events。
2:在获得内核执行的程序的名称后,将其发送到用户空间进行聚合。我们使用perf_submit来实现这一点。此函数使用我们的新信息更新Perf events映射。
3:初始化BPF程序并将其附着到kprobe,以便在系统中执行新程序时触发。
现在我们已经编写了收集系统中执行的所有程序的代码,我们需要在用户空间中聚合它们。
1 | from collections import Counter |
1:声明一个计数器来存储我们的程序信息。我们使用程序的名称作为键,值将是计数器。我们使用aggregate_ programs函数从Perf事件映射中收集数据。在本例中可以看到我们如何使用BCC宏访问映射并从堆栈顶部提取下一个传入数据事件。
2:增加我们收到具有相同程序名称的事件的次数。
3:使用函数open_perf_buffer告诉BCC,每次从Perf events映射接收到事件时,它都需要执行aggregate函数程序。
4:BCC在打开环形缓冲区后轮询事件,直到我们中断此Python程序。等待的时间越长,处理的信息就越多。可以看到我们如何使用perf_buffer_poll
5:使用most_common函数获取计数器和循环中的元素列表,以打印系统中执行次数最多的程序。
perf_events.py完整代码如下
1 | from bcc import BPF |
结论
在本章中,我们只触及了使用BPF进行跟踪的表面。Linux内核允许您访问其他工具更难以获取的信息。BPF使此过程更具可预测性,因为它提供了访问此数据的公共接口。在后面的章节中,您将看到更多使用此处描述的一些技术的示例,例如将函数附着到跟踪点。
在下一章中,我们将展示系统社区在BPF基础上构建的一些工具,用于进行性能分析和跟踪。这些专用工具可以让你访问我们看到的打包格式的大部分信息。这样你就不需要重写已经存在的工具。