第五章节
BPF实用程序
到目前为止,我们已经讨论了如何编写BPF程序以在系统中获得更多可见性。多年来,许多开发人员都使用BPF构建了用于相同目的的工具。在本章中,我们将讨论一些你可以每天使用的现成工具。其中许多工具是你已经见过的一些BPF程序的高级版本。还有一些工具可以帮助你直接了解自己的BPF程序。
本章介绍了一些工具,可以在BPF的日常工作中对你有所帮助。我们首先介绍BPFTool,这是一个命令行实用程序,用于获取有关 BPF 程序的更多信息。我们涵盖了BPFTrace和kubectl-trace,它们会让你使用简洁的领域特定语言(DSL)有效地编写BPF程序。最后,我们谈谈eBPF Exporter,一个将BPF与Prometheus集成的开源项目。
BPFTool
BPFTool是一个用于检查BPF程序和映射的内核实用程序。默认情况下,该工具不会安装在任何Linux发行版上,而且它正在大量开发中,因此需要最能支持你的Linux内核版本。这里我们介绍Linux 5.1版的BPFTool。
在接下来的部分中,我们将讨论如何将BPFTool安装到你的系统上,以及如何使用它来观察和更改BPF程序的行为和终端中的映射。
安装
1 | 获取内核源码。源码下载地址如下 |
可以通过检查其版本来检查BPFTool是否已正确安装:
1 | [root@VM-16-14-centos ~]# bpftool --version |
功能展示
你可以使用BPFTool执行的基本操作之一是扫描系统以了解可以访问哪些BPF功能。 当你不记得哪个版本的内核引入了哪种程序或是否启用了BPF JIT编译器时,这种方法非常有用。要找出这些问题以及许多其他问题的答案,请运行以下命令:
1 | [root@VM-16-14-centos ~]# bpftool feature |
在此输出中可以看到我们的系统允许非特权用户执行syscall bpf,此调用仅限于某些操作。 还可以看到JIT已启用。较新版本的内核默认启用此JIT,它对编译BPF程序有很大帮助。 如果你的系统没有启用它,您可以运行以下命令来启用它:
1 | echo 1 > /proc/sys/net/core/bpf_jit_enable |
功能输出还显示了系统中启用了哪些程序类型和映射类型。这个命令提供的信息比我们在这里展示的要多得多,比如程序类型和许多其他配置指令支持的BPF助手。
检查BPF程序
BPFTool为你提供有关内核上BPF程序的直接信息。它允许调查系统中已经运行的内容。还允许加载和固定以前从命令行编译的新的BPF程序。
学习如何使用BPFTool处理程序的最佳起点是检查你在系统中运行的内容。为此,可以运行命令bpftool prog show。 如果你使用Systemd作为你的init系统,那么可能已经加载了一些BPF程序并附加到一些cgroup;我们稍后再讨论这些。 运行该命令的输出将如下所示:
1 | [root@VM-16-14-centos ~]# bpftool prog show |
左侧冒号前的数字是程序标识符;我们稍后会使用它们来调查这些程序的全部内容。从这个输出中还可以了解系统正在运行哪些类型的程序。在当前这种情况下,系统正在运行三个附加到cgroup套接字缓冲区的BPF程序。如果这些程序实际上是由Systemd启动的,则加载时间可能会与你启动系统时匹配。你还可以查看这些程序当前使用了多少内存以及与它们关联的映射的标识符。 所有这些乍一看都很有用,而且因为我们有程序标识符,我们可以更深入地进行研究。
你可以将程序标识符作为额外参数添加到前面的命令中:bpftool prog show id 52。这样,BPFTool将显示你之前看到的相同信息,但仅针对由ID 52标识的程序; 这样可以过滤掉你不需要的信息。 此命令还支持--json标志来生成一些JSON输出。如果你想操作输出,这个JSON输出非常方便。例如,像jq这样的工具会为你提供更结构化的数据格式:
1 | bpftool prog show --json id 52 | jq |
当你知道程序标识符时,你还可以使用BPFTool获取整个程序的转储;当你需要调试编译器生成的BPF字节码时,这会很方便:
1 | bpftool prog dump xlated id 52 |
这个由Systemd加载到我们内核中的程序正在使用帮助程序bpf_skb_load_bytes检查数据包数据。
如果你想要这个程序更直观的表示,包括指令跳转,你可以在这个命令中使用visual关键字。 这将生成一种格式化的输出,你可以使用dot之类的工具或任何其他可以绘制图形的程序将其转换为图形表示:
1 | bpftool prog dump xlated id 52 visual &> output.out |
如果你运行的是5.1或更新版本的内核,还可以访问运行时统计信息。它们告诉你内核在你的BPF程序上花费了多长时间。默认情况下,系统中可能未启用此功能;你需要先运行这个命令,让内核知道它需要向你展示这些数据:
1 | sysctl -w kernel.bpf_stats_enabled=1 |
启用统计信息后,你将在运行BPFTool时获得另外两条信息:内核运行该程序所花费的总时间(run_time_ns),以及运行该程序的次数(run_cnt):
1 | 52: cgroup_skb tag 7be49e3934a125ba run_time_ns 14397 run_cnt 39 |
但是BPFTool不仅允许你检查程序的运行情况;它还允许你将新程序加载到内核中并将其中一些附加到套接字和 cgroup。 例如,我们可以加载我们以前的程序之一并将其固定到BPF文件系统,使用以下命令:
1 | [root@VM-16-14-centos cpt1]# bpftool prog load bpf_program.o /sys/fs/bpf/bpf_prog |
检查BPF映射
除了允许检查和操作BPF程序之外,BPFTool还可以让您访问这些程序正在使用的BPF映射。 列出所有映射并按其标识符过滤映射的命令,类似之前看到的show命令。 除了让BPFTool显示prog的信息,还可以显示map的信息:
1 | bpftool map show |
这些映射与之前看到的附加到程序的标识符相匹配。还可以按ID过滤映射。
你可以使用BPFTool创建和更新映射并列出映射中的所有元素。创建新映射所需的信息与你在初始化映射时提供的信息相同。我们需要指定要创建的映射类型、键和值的大小及其名称。因为我们没有将映射与程序一起初始化,所以我们还需要将它固定到BPF文件系统,以便我们以后可以使用它:
1 | [root@VM-16-14-centos bpf]# bpftool map create /sys/fs/bpf/counter type array key 4 value 4 entries 5 name counter |
如果在运行该命令后列出系统中的映射,将在列表底部看到新映射:
1 | [root@VM-16-14-centos bpf]# bpftool map |
创建映射后可以像在BPF程序中那样更新和删除元素。
如果要向映射添加新元素或更新现有元素,可以使用映射更新命令。你可以从前面的示例中获取映射标识符:
1 | [root@VM-16-14-centos bpf]# bpftool map update id 45 key 1 0 0 0 value 1 0 0 0 |
如果你尝试使用无效的键或值更新元素,BPFTool将返回错误:
1 | [root@VM-16-14-centos bpf]# bpftool map update id 45 key 1 0 0 0 value 1 0 0 |
如果需要检查其值,BPFTool可以提供映射中所有元素的转储。在创建固定大小的数组映射时,可以看到BPF如何将所有元素初始化为空值:
1 | [root@VM-16-14-centos bpf]# bpftool map dump id 45 |
BPFTool提供的最强大的选项之一是,你可以将预先创建的映射附加到新程序,并用这些预先分配的映射替换它们初始化的映射。这样你可以从一开始就让程序访问保存的数据,即使你没有编写程序来从BPF文件系统读取映射。 为此,你需要在使用BPFTool加载程序时设置要初始化的映射。可以通过程序加载它时的有序标识符来指定映射,例如,0表示第一个映射,1表示第二个映射,依此类推。还可以通过名称指定映射,这通常更方便:
1 | [root@VM-16-14-centos cpt1]# bpftool prog load bpf_program.o /sys/fs/bpf/bpf_prog_2 map name counter pinned /sys/fs/bpf/counter |
在这个例子中,我们将刚刚创建的映射附加到一个新程序中。在这种情况下,我们将映射替换为它的名称,因为我们知道程序初始化了一个名为counter的映射。 你还可以使用关键字idx使用映射的索引位置,如idx 0。
当您需要实时调试消息传递时,直接从命令行访问BPF映射很有用。 BPFTool让你以一种更方便的方式直接访问。 除了自省程序和映射之外,你还可以使用BPFTool从内核中提取更多信息。 接下来让我们看看如何访问特定的接口。
检查附着到特定接口的程序
有时你会发现自己想知道哪些程序附加到特定接口。BPF 可以加载在cgroup、Perf事件和网络数据包之上工作的程序。子命令cgroup、perf 和 net可以帮助你追溯这些接口上的附着程序。
perf子命令列出所有附加到系统中跟踪点的程序,如kprobes、uprobes和tracepoints; 你可以通过运行 bpftool perf show来查看该列表。
net子命令列出了附加到XDP和Traffic Control的程序。其他附着程序,如套接字过滤器和重用端口程序,只能通过使用iproute2访问。 您可以使用bpftool net show列出XDP和TC的附着程序,就像在其他BPF对象中看到的一样。
最后,cgroup子命令列出所有附加到cgroup的程序。 这个子命令与你看到的其他命令有些不同。bpftool cgroup show需要你检查的cgroup路径。如果要列出系统中所有cgroup中的所有附着程序,则需要使用bpftool cgroup tree,如下例所示:
1 | bpftool cgroup tree |
至此,我们已经讨论了如何在终端中输入不同的命令来调试BPF程序。但是,当你最需要这些命令时,记住所有这些命令可能会很麻烦。接下来,我们将描述如何从纯文本文件加载几个命令,以便你可以构建一组方便使用的脚本。
在批处理模式下加载命令
当你尝试分析一个或多个系统的行为时,经常反复运行多个命令。最终可能会得到一组经常在工具链中使用的命令。 如果你不想每次都输入这些命令,BPFTool的批处理模式就很适合你。
使用批处理模式可以将要执行的所有命令写入文件并一次运行所有命令。还可以通过以#开头的行在此文件中写入注释。但是,这种执行模式不是原子的。BPFTool逐行执行命令,如果其中一个命令失败,它将中止执行,使系统处于运行最新成功命令后的状态。
以下是批处理模式可以处理的文件的简短示例:
1 | Create a new hash map |
如果将这些命令保存在名为/tmp/batch_example.txt的文件中,则可以使用bpftool batch file /tmp/batch_example.txt加载它。 当你第一次运行这个命令时,你会得到类似于下面的代码片段的输出,但是如果你再次尝试运行它,这个命令将会退出并且没有输出,因为我们已经有一个名为hash_map的映射在系统,并且批处理执行将在第一行失败:
1 | [root@VM-16-14-centos tmp]# bpftool batch file /tmp/batch_example.txt |
显示BTF信息
BPFTool可以显示任何给定二进制对象存在的BPF类型格式(BTF)信息。BTF使用元数据信息对程序结构进行注释,以帮助你调试程序。
例如,当你将关键字linum添加到prog dump时,它可以为你提供BPF程序中每条指令的源文件和行号。
BPFTool的最新版本包括一个新的btf子命令,帮助你深入了解程序。此命令的初始重点是可视化结构类型。例如,bpftool btf dump id 54显示了ID为54的程序的所有BTF类型。
BPFTrace
BPFTrace是BPF的高级跟踪语言。允许你使用简洁的DSL编写BPF程序,并将它们保存为可以执行的脚本,而无需手动编译和加载它们到内核中。该语言受到其他知名工具的启发,例如awk和DTrace。
与直接使用BCC或其他BPF工具编写程序相比,使用BPFTrace的优势之一是BPFTrace提供了许多你不需要自己实现的内置功能,例如聚合信息和创建直方图。
以Centos8为例,如果你安装了epel-release支持,那么一条dnf就可以安装bpftrace
1 | [root@VM-16-14-centos ~]# dnf install bpftrace |
BPFTrace执行的程序具有简洁的语法。我们可以将它们分为三个部分:header, action blocks, and footer。 header是BPFTrace在加载程序时执行的特殊块;它通常用于在输出顶部打印一些信息,例如序言。同样,footer是一个特殊的块,BPFTrace在终止程序之前执行一次。 header和footer都是BPFTrace程序中的可选部分。一个 BPFTrace程序必须至少有一个action block。action block是我们指定要跟踪的探针以及内核触发这些探针的事件时执行的操作的地方。下一个示例我们将展示这三个部分:
1 | BEGIN |
header部分总是用关键字BEGIN标记,而footer部分总是用关键字END标记。 这些关键字由BPFTrace保留。 action block标识符定义了你希望将BPF操作附加到的探测器。在前面的示例中,我们在内核每次打开文件时打印一行日志。
除了识别程序部分之外,我们已经可以在前面的示例中看到有关语言语法的更多细节。BPFTrace提供了一些帮助程序,这些帮助程序在程序编译时被翻译成BPF代码。 帮助程序printf是C函数printf的包装器,它在你需要时打印程序详细信息。str是一个内置的辅助函数,它将C指针转换为其字符串表示形式。许多内核函数接收指向字符的指针作为参数。这个辅助函数会为你翻译那些指向字符串的指针。
BPFTrace可以被认为是一种动态语言,因为它不知道内核执行探针时可能收到的参数数量。这就是BPFTrace提供参数辅助函数来访问内核处理的信息的原因。BPFTrace根据块接收的参数数量动态生成这些帮助程序,可以通过其在参数列表中的位置访问信息。在前面的示例中,arg1是对open系统调用中第二个参数的引用,它引用了文件路径。
要执行此示例,可以将其保存在文件中并使用文件路径作为第一个参数运行BPFTrace:
1 | [root@VM-16-14-centos ~]# bpftrace /tmp/example.bt |
BPFTrace语言在设计时考虑了脚本。在前面的示例中,您已经看到了该语言的简洁版本。 但是,你也可以无需将这些单行程序存储在文件中即可执行它们;可以在执行BPFTrace时使用选项-e运行它们。 如下所示
1 | [root@VM-16-14-centos ~]# bpftrace -e "kprobe:do_sys_open { @opens[arg1] = count() }" |
过滤
当你运行前面的例子时,你可能会得到一个系统不断打开的文件流,直到你按下Ctrl-C退出程序。 那是因为我们告诉BPF打印内核打开的每个文件描述符。在某些情况下,你只想针对特定条件执行action block。 BPFTrace称之为过滤。
你可以将一个过滤器关联到每个action block。 它们像action block一样评估,但如果过滤器返回false值,则操作不会执行。他们还可以访问该语言的其余部分,包括探测参数和辅助函数。 这些过滤器封装在动作标头之后的两个斜杠中:
1 | kprobe:do_sys_open /str(arg1) == "/tmp/example.bt"/ |
在这个例子中,我们将我们的动作块优化为仅当内核打开的文件是我们用来存储这个例子的文件时才执行。如果你用新的过滤器运行程序,你会看到它打印了标题,但它在那里停止打印。 这是因为由于我们的新过滤器,之前触发我们操作的每个文件现在都被跳过了。如果你在不同的终端中多次打开示例文件,你将看到当过滤器匹配我们的文件路径时内核如何执行操作:
1 | [root@VM-16-14-centos ~]# bpftrace /tmp/example.bt |
动态映射
BPFTrace实现的一项方便的功能是动态映射关联。 它可以动态生成BPF映射,你可以将其用于本书中看到的许多操作。所有映射关联都以字符@开头,后面跟要创建的映射的名称。 还可以通过为它们分配值来关联这些映射中的更新元素。
如果我们以本节开头的示例为例,我们可以汇总系统打开特定文件的频率。为此,我们需要计算内核在特定文件上运行open系统调用的次数,然后将这些计数器存储在映射中。为了识别这些聚合,我们可以使用文件路径作为映射的键。
1 | kprobe:do_sys_open |
执行程序后输出如下
1 | bpftrace /tmp/example.bt |
如你所见,BPFTrace在停止程序执行时打印映射的内容。它汇总了内核在我们系统中打开文件的频率。 默认情况下,BPFTrace总是会在它终止时打印它创建的每个映射的内容。 您无需指定要打印的映射;你可以通过使用内置函数clear清除END块内的映射来更改该行为。 这是因为打印映射总是发生在footer块执行之后。
kubectl-trace
kubectl-trace是Kubernetes命令行kubectl的插件。它可以帮助你在Kubernetes集群中处理BPFTrace程序,而无需安装任何额外的包或模块。它通过使用容器镜像调度一个Kubernetes job来实现这一点,该容器镜像已经安装了运行程序所需的一切。 此镜像称为trace-runner,它也可以在公共Docker中使用。å
安装
你需要使用Go的工具链从其源存储库安装kubectl-trace,因为其开发人员不提供任何二进制包:
1 | go get -u github.com/iovisor/kubectl-trace/cmd/kubectl-trace |
在Go的工具链编译程序并将其放入路径后,kubectl的插件系统会自动检测到这个新插件。kubectl-trace会在你第一次执行它时自动下载它在集群中运行的Docker镜像。
检查k8s节点
可以使用kubectl-trace来定位运行容器的节点和pod,也可以使用它来定位在这些容器上运行的进程。在第一种情况下,你几乎可以运行任何你想要的BPF程序。但是,在第二种情况下只能运行将用户空间探测器附加到这些进程的程序。
如果要在特定节点上运行BPF程序,则需要一个适当的标识符,以便Kubernetes将作业安排在适当的位置。有了这个标识符之后,运行程序就和运行你之前看到的程序类似。 如下所示我们运行单行来计算文件打开次数:
1 | kubectl trace run node/node_identifier -e \ |
我们使用命令kubectl trace run将其安排在特定的集群节点中。 我们使用语法node/...来告诉kubectl-trace我们正在针对集群中的一个节点。如果我们想针对特定的pod,我们可以将node/替换为pod/。
在特定容器上运行程序更加复杂
1 | kubectl trace run pod/pod_identifier -n application_name -e <<PROGRAM |
在这个命令中有两件事情需要强调。第一个是我们需要容器中运行的应用程序的名称才能找到它的进程; 这对应于我们示例中的application_name, 需要使用在容器中执行的二进制文件的名称,例如nginx或memc ached。 通常,容器只运行一个进程,但这为我们提供了额外的保证,即我们将程序附加到正确的进程。第二个方面是在BPF程序中包含$container_pid。 这不是BPFTrace辅助函数,而是kubectl-trace用作进程标识符替换的占位符。在运行BPF程序之前,trace-runner用适当的标识符替换占位符,并将我们的程序附加到正确的进程。
在本节和前面几节中,我们专注于更有效地运行BPF程序的工具,即使在容器环境中也是如此。 在下一节中,我们将讨论一个更好的工具,它将BPF程序收集的数据与开源监控系统Prometheus集成在一起。
eBPF Exporter
eBPF Exporter是一个允许你自定义BPF跟踪指标导出到Prometheus的工具。Prometheus是一个高度可扩展的监控和警报系统。与其他监控系统不同的一个关键因素是它使用拉取策略来获取指标,而不是期望客户端将指标推送给它。这允许用户编写可以从任何系统收集指标的自定义导出器,Prometheus使用API模式提取它们。eBPF Exporter实现此API以从BPF程序中获取跟踪指标并将它们导入Prometheus。
安装
尽管eBPF Exporter提供二进制包,但我们建议从源代码安装它,因为通常没有新版本。从源代码构建还可以让你访问BCC(BPF 编译器集合)之上构建的更新功能。
要从源代码安装eBPF Exporter,你需要在计算机上已经安装BCC和Go的工具链。 有了这些先决条件后可以使用Go下载和构建二进制文件:
1 | go get -u github.com/cloudflare/ebpf_exporter/... |
从BPF导出指标
eBPF Exporter使用YAML文件进行配置,你可以在其中指定要从系统收集的指标、生成这些指标的BPF程序以及它们如何转换为Prometheus。当 Prometheus向eBPF Exporter发送请求以提取指标时,此工具会将BPF程序正在收集的信息转换为指标值。eBPF Exporter捆绑了许多系统收集非常有用的信息的程序,例如周期指令(IPC)和CPU缓存命中率。
eBPF Exporter的简单配置文件包括三个主要部分。在第一部分中定义了希望Prometheus从系统中提取的指标。 在这里可以将BPF映射中收集的数据转换为Prometheus理解的指标。 如下示例所示:
1 | programs: |
我们定义了一个名为timer_start_total的指标,它聚合了内核启动定时器的频率。我们还指定我们希望从名为counts的BPF映射中收集此信息。 最后,我们为映射的键定义了一个翻译函数。 这是必要的,因为映射键通常是指向信息的指针,我们希望向Prometheus发送实际的函数名称。
本例中的第二部分描述了我们想要将BPF程序附加到的探针。在这种情况下,我们要跟踪计时器开始调用; 我们使用tracepoint timer:timer_start:
1 | tracepoints: |
这里我们告诉eBPF Exporter,我们希望将BPF函数tracepoint__timer__timer_start附加到这个特定的跟踪点。 接下来让我们看看如何声明该函数:
1 | code: | |
eBPF Exporter使用BCC编译程序,因此我们可以访问它的所有宏和帮助程序。前面的代码片段使用宏TRACEPOINT_PROBE生成最终函数,我们将附加到名为tracepoint__timer__timer_start的跟踪点。
Cloudflare使用eBPF Exporter来监控其所有数据中心的指标。
结论
在本章中,我们讨论了一些系统分析工具。当你需要调试系统上的任何异常时,这些工具可以随时使用。所有工具都抽象了我们在前几章中看到的概念,以帮助你使用BPF即便你的环境还没有准备好。这是BPF与其他众多分析工具相比的优势之一;因为任何现代Linux内核都包含BPF虚拟机,所以你可以在其上构建利用这些强大功能的新工具。
还有许多其他工具将BPF用于类似目的,例如Cilium和Sysdig,我们鼓励你去尝试使用它们。
在接下来的章节中,我们将深入探讨它的网络功能。我们将展示如何分析任何网络中的流量以及如何使用BPF来控制网络中的消息。
第六章节
Linux网络和BPF
从网络的角度来看,我们将BPF程序用于两个用途:数据包捕获和过滤。
这意味着用户空间程序可以将过滤器附加到任何套接字并提取有关流经它的数据包的信息,并允许/禁止/重定向某些类型的数据包,因为它们在该级别可以看到。
本章的目的是解释BPF程序在Linux内核网络堆栈中网络数据路径的不同阶段如何与Socket Buffer结构进行交互。 我们将确定两种类型的程序作为常见用例
- 与套接字相关的程序类型
- 基于BPF的流量控制分类器编写的程序
Socket Buffer结构,也称为SKB或sk_buff,是内核中为每个发送或接收的数据包创建和使用的结构。通过读取SKB可以传递或丢弃数据包并填充BPF映射以创建有关当前流量的统计信息和流量指标。
此外,一些BPF程序允许你操作SKB,并通过扩展转换最终数据包,以重定向或改变它们的基本结构。例如,在仅使用IPv6的系统上可以编写一个程序,将所有收到的数据包从IPv4转换为 IPv6,这可以通过修改数据包的SKB来完成。
理解网络中的BPF和eBPF的关键是需要了解我们可以编写的不同类型的程序之间的差异,以及不同的程序如何导致相同的结果;在下一节中,我们将介绍在套接字级别进行过滤的两种方法:使用经典的BPF过滤器,以及使用附加到套接字的eBPF程序。
BPF和包过滤
如前所述,BPF过滤器和eBPF程序是BPF程序在网络环境中的主要用例。然而最开始BPF程序是包过滤的同义词。
包过滤仍然是最重要的用例之一,并且已经从经典的BPF (cBPF)扩展到Linux 3.19中的eBPF,并在过滤程序类型BPF_PROG_TYPE_SOCKET_FILTER中添加了与映射相关的功能。
过滤器主要可用于三个高级场景:
- 实时流量丢弃(例如,仅允许用户数据报协议UDP流量,丢弃其他任何内容)
- 实时观察流入系统的一组过滤数据包
- 使用
pcap格式对实时系统上捕获的网络流量进行回顾分析
术语pcap来自两个词的结合:数据包(packet)和捕获(capture)。pcap格式在数据包捕获库 libpcap的库中实现,是用于数据包捕获的特定域API。 当你希望在实时系统上捕获的一组数据包能够直接保存到文件中,方便后续使用pcap格式导出的数据包流的工具进行分析时,这种格式在调试场景中很有用。
在接下来的部分中,我们将展示两种不同的方式来应用BPF程序的包过滤。首先,我们展示了像tcpdump这样的常见且广泛使用的工具如何充当用作过滤器的BPF程序的更高级的接口。然后我们使用BPF_PROG_TYPE_SOCKET_FILTERBPF程序类型编写并加载我们自己的程序。
tcpdump和BPF表达式
说到实时流量分析和观察,每个人都知道的命令行工具之一就是tcpdump。 本质上是libpcap的前端,它允许用户定义高级过滤表达式。tcpdump所做的是从你选择的网络接口(或任何接口)读取数据包,然后将接收到的数据包的内容写入标准输出或文件。然后可以使用pcap过滤器语法过滤数据包流。pcap过滤器语法是一种DSL,使用一组原语组成的高级表达式集过滤数据包,这些原语通常比BPF汇编更容易记住。解释pcap过滤器语法中所有可能的原语和表达式超出了本章的范围,具体可以使用man 7 pcap-filter查看。
场景是我们在一个Linux机器中,它在端口8080上公开了一个Web服务器;这个Web服务器没有记录它接收到的请求,我们想知道它是否正在接收任何请求以及这些请求是如何流入的,因为所服务应用程序的客户抱怨在浏览时无法获得任何响应产品页面。在这一点上,我们只知道客户正在使用由该Web服务器提供的Web应用程序连接到我们的产品页面,并且总是发生这种情况,我们不知道是什么原因,因为最终用户通常不会调试服务,不幸的是我们没有在这个系统中部署任何日志记录或错误报告策略,因此我们在调查问题时完全是盲目的。幸运的是,有一个工具可以帮助我们!它是tcpdump,可以告诉它只过滤在我们系统中流动的IPv4数据包,这些数据包在端口8080上使用传输控制协议 (TCP)。因此,我们将能够分析Web服务器的流量。
以下是使用tcpdump进行过滤的命令:
1 | [root@VM-16-14-centos ~]# tcpdump -n 'ip and tcp port 8080' |
让我们看看这个命令中发生了什么:
-n是为了告诉tcpdump不要将地址转换为各自的名称,我们想查看源地址和目标地址。ip and tcp port 8080是tcpdump用于过滤数据包的pcap过滤器表达式。ip表示IPv4,它是一个连词,表示一个更复杂的过滤器,以允许添加更多表达式来匹配,然后我们指定我们只对来自tcp端口8080或到达端口8080的tcp数据包感兴趣。在这种情况下,更好的过滤器应该是tcp dst port 8080,因为我们只对目标端口为8080的数据包感兴趣,而不是来自它的数据包。
其输出如下:
1 | tcpdump: verbose output suppressed, use -v or -vv for full protocol decode |
可以看到,我们有一堆请求进展顺利,返回200 OK状态代码,但在/api/products端点上还有一个带有500内部服务器错误代码的请求。表示我们在列出产品时服务器遇到问题!
此时,你可能会问,如果BPF程序有自己的语法,所有这些pcap过滤内容和tcpdump有什么关系?Linux上的Pcap过滤器被编译为BPF程序!而且因为tcpdump使用pcap过滤器进行过滤,这意味着每次使用过滤器执行tcpdump时,实际上是在编译和加载BPF程序来过滤数据包。幸运的是,通过将-d标志传递给tcpdump,你可以转储在使用指定过滤器时将加载的BPF指令:
1 | [root@VM-16-14-centos ~]# tcpdump -d 'ip and tcp port 8080' |
该过滤器与上一个示例中使用的过滤器相同,但由于-d标志,现在输出是一组BPF汇编指令。
输出如下
1 | (000) ldh [12] |
分析如下
ldh [12]:在偏移量12处从累加器加载(ld)一个(h)半字(16 位),这是Ethertype字段,第二层以太网帧结构如下图所示。

jeq #0x800 jt 2 jf 12:如果 (eq) 相等则跳转(j) ;检查上一条指令中的Ethertype值是否等于0x800(这是 IPv4 的标识符),然后使用跳转目标,如果为真(jt)则为2,如果为假(jf)则为12,因此这将继续到下一个如果Internet协议是IPv4的指令——否则它将跳转到末尾并返回零。
ldb [23]:加载字节(ldb),将从IP帧中加载更高层协议字段,该字段可在偏移量23处找到——偏移量23来自以太网第2层帧中头的14个字节的添加加上协议在IPv4头中的位置,即第9个,因此14+9=23。
jeq #0x6 jt 4 jf 12:如果相等,再跳一次。这种情况下,我们检查之前提取的协议是0x6,即TCP。如果是,我们跳到下一条指令(4)或者我们走到最后(12)——如果不是,我们丢弃数据包。
ldh [20]:这是另一个加载半字指令——在这种情况下,它是从IPv4头加载数据包偏移量+分片偏移量的值。
jset #0x1fff jt 12 6:如果我们在分片偏移中找到的任何数据为真,则此jset指令将跳转到12——否则,跳转到6,即下一条指令。指令0x1fff之后的偏移量告诉jset指令只查看最后13个字节的数据。(扩展为 0001 1111 1111 1111)
ldxb 4*([14]&0xf):将(b)加载(ld)到x中。该指令会将IP标头长度的值加载到x中。
ldh [x+14]:另一个加载半字指令将获取偏移量(x + 14)处的值,IP标头长度+14,这是数据包中源端口的位置。
jeq #0x1f90 jt 11 jf 9:如果(x + 14)处的值等于0x1f90(十进制的 8080),这意味着源端口将是8080,继续11或继续检查目标端口是否在端口8080上,如果是错误的,继续9 .
ldh [x + 16]:这是另一个加载半字指令,它将获取偏移量(x + 16)处的值,这是数据包中目标端口的位置。
jeq #0x1f90 jt 11 jf 12:这里如果相等再跳转一次,这次用来检查目的地是否为8080,跳转到11;如果不是,转至12并丢弃该数据包。
ret #262144:到达此指令时,会找到匹配项,从而返回匹配的快照长度。 默认情况下,此值为262144字节。 可以使用tcpdump中的-s参数对其进行调整。
如果只考虑以8080作为目标的数据包,而不是作为源的数据包,tcpdump示例如下:
1 | [root@VM-16-14-centos ~]# tcpdump -d 'ip and tcp dst port 8080' |
除了像我们那样分析从tcpdump生成的程序集之外,你可能还想编写自己的代码来过滤网络数据包。事实证明,在这种情况下,最大的挑战将是实际调试代码的执行以确保它符合我们的期望; 在这种情况下,在内核源代码树中,tools/bpf中有一个名为bpf_dbg.c的工具,它本质上是一个调试器,允许加载程序和pcap文件以逐步测试执行。
tcpdump也可以直接从.pcap文件中读取,并对其应用BPF过滤器。
原始套接字的数据包过滤
BPF_PROG_TYPE_SOCKET_FILTER程序类型允许你将BPF程序附加到套接字。它接收到的所有数据包都会以sk_buff结构体的形式传递给程序,然后程序可以决定是丢弃还是允许。这种程序还具有访问和处理映射的能力。
让我们看一个例子,看看如何使用这种BPF程序。
我们示例程序的目的是计算在观察下流经接口的TCP、UDP和互联网控制消息协议(ICMP)数据包的数量。为此,我们需要以下内容:
- 可以看到数据包流动的BPF程序
- 加载程序并将其附加到网络接口的代码
- 用于编译程序并启动加载程序的脚本
此时我们可以通过两种方式编写BPF程序:作为C代码然后编译为ELF文件,或者直接作为BPF程序集。对于这个例子,我们选择使用C代码来展示更高层次的抽象以及如何使用Clang来编译程序。
BPF程序
这里BPF程序的主要职责是访问它接收到的数据包;检查其协议是TCP、UDP还是ICMP,然后在找到的协议的特定键上增加映射数组上的计数。
对于这个程序,我们将利用位于内核源码中samples/bpf/bpf_load.c中的帮助程序解析ELF文件的加载机制。 加载函数load_bpf_file能够识别某些特定的ELF节头,并将它们与相应的程序类型相关联。 代码如下:
1 | bool is_socket = strncmp(event, "socket", 6) == 0; |
代码所做的第一件事是在节头和内部变量之间创建关联——就像SEC("socket")一样,我们最终会得到bool is_socket=true
之后在同一个文件中,我们看到了一组if指令,它们创建了header和实际prog_type之间的关联,因此对于is_socket,我们最终得到BPF_PROG_TYPE_SOCKET_FILTER:
1 | if (is_socket) { |
因为我们想编写一个BPF_PROG_TYPE_SOCKET_FILTER程序,我们需要指定一个SEC("socket")作为我们函数的ELF头,它将作为BPF程序的入口点。
正如从该列表中看到的那样,有多种与套接字和一般网络操作相关的程序类型。在本章中,我们将展示BPF_PROG_TYPE_SOCKET_FILTER的示例;此外,后面我们将讨论程序类型为 BPF_PROG_TYPE_XDP的XDP程序。
我们想要存储遇到的每个协议的数据包计数,需要创建一个键/值映射,其中协议是键,数据包计数为值。为此可以使用BPF_MAP_TYPE_ARRAY:
1 | struct bpf_map_def SEC("maps") countmap = { |
该映射是使用bpf_map_def结构定义的,它将被命名为countmap以供程序中引用。
此时,我们可以编写一些代码来实际计算数据包。BPF_PROG_TYPE_SOCKET_FILTER类型的程序是我们的选择之一,因为通过使用这样的程序,我们可以看到所有流经接口的数据包。因此我们使用SEC("socket")将程序附加到正确的头部:
1 | SEC("socket") |
在ELF头附加之后,我们可以使用load_byte函数从sk_buff结构中提取协议部分。然后使用协议ID作为键来执行bpf_map_lookup_elem操作以从计数映射中提取当前计数器值,以便我们可以将其递增,如果它是第一个数据包,我们可以将其设置为1。现在我们可以使用 bpf_map_update_elem用增加的值更新映射。
完整的bpf_program.c程序如下
1 |
|
编译如下
1 | [root@VM-16-14-centos cpt6]# clang -O2 -target bpf -c bpf_program.c -o bpf_program.o |
报错如下
1 | [root@VM-16-14-centos cpt6]# clang -O2 -target bpf -c bpf_program.c -o bpf_program.o |
解决办法如下
https://github.com/cilium/cilium/issues/368
重新编译
1 | [root@VM-16-14-centos cpt6]# clang -O2 -target bpf -c bpf_program.c -o bpf_program.o |
加载并附加到网络接口
加载程序是实际打开我们编译的BPF ELF二进制文件bpf_program.o的程序,并将定义的BPF程序及其映射附加到一个套接字,该套接字是针对所观察的接口创建的,在我们的例子中是环回接口。
loader最重要的部分是ELF文件的加载:
1 | if (load_bpf_file(filename)) { |
这将通过添加一个元素来填充prog_fd数组,该元素是我们加载的程序的文件描述符,我们现在可以将其附加到使用open_raw_sock打开的环回接口的套接字描述符上。
通过将选项SO_ATTACH_BPF设置为为接口打开的原始套接字来完成附加。
此时,我们的用户空间加载器能够在内核发送映射元素时查找它们:
1 | for (i = 0; i < 10; i++) { |
为了进行查找,我们使用for循环和bpf_map_look_elem附加到数组映射,以便我们可以分别读取和打印TCP、UDP和ICMP数据包计数器的值
loader.c程序完整代码如下
1 |
|
因为这个程序使用的是libbpf,所以我们需要在下载的源码中编译它:
1 | [root@VM-16-14-centos bpf]# pwd |
接着我们可以使用如下脚本编译加载器:
build-loader.sh代码如下
1 | KERNEL_SRCTREE=$1 |
该脚本包含一堆头文件和内核本身的libbpf库,因此它必须知道在哪里可以找到内核源码。 为此可以在其中替换$KERNEL_SRCTREE或将该脚本写入文件并使用它:
1 | [root@VM-16-14-centos cpt6]# ./build-loader.sh /root/linux-5.4 |
报错如下
1 | /tmp/loader-19267c.o:(.bss+0x0): multiple definition of `bpf_log_buf' |
解决方法如下
https://stackoverflow.com/questions/12511044/bss0x0-multiple-definition-of-proxies
即在全局变量前声明extern,这里我们在char bpf_log_buf[BPF_LOG_BUF_SIZE]处声明
1 | extern char bpf_log_buf[BPF_LOG_BUF_SIZE]; |
之后重新编译会创建一个loader-bin文件,最终可以启动BPF程序的ELF文件:
1 | [root@VM-16-14-centos cpt6]# ./loader-bin bpf_program.o |
程序加载并启动后,将执行10次转储,每秒一次显示三个协议中的每一个的数据包计数。因为程序连接到环回设备lo,所以你可以与加载程序一起运行ping并看到ICMP计数器增加。
运行ping来生成到localhost的ICMP流量:
1 | [root@VM-16-14-centos cpt6]# ping -c 100 127.0.0.1 |
输出如下:
1 | PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data. |
在另一个终端中运行我们的BPF程序:
1 | [root@VM-16-14-centos cpt6]# ./loader-bin bpf_program.o |
基于BPF的流量控制分类器
流量控制是内核数据包调度子系统架构。由决定数据包如何流动以及如何被接受的机制和排队系统组成。流量控制的一些用例包括但不限于以下内容:
- 优先处理某些类型的数据包
- 丢弃特定类型的数据包
- 带宽分配
一般来说,当你需要重新分配系统中的网络资源时,流量控制是一种可行的方法,为了充分利用它,应该根据你想要运行的应用程序类型部署特定的流量控制配置。流量控制提供了一个可编程的分类器,称为cls_bpf,让钩子进入不同级别的调度操作,它们可以读取和更新套接字缓冲区和数据包元数据,以执行流量整形、跟踪、预处理等操作。
cls_bpf中对eBPF的支持是在内核4.1中实现的,这意味着这种程序可以访问eBPF映射,支持尾调用,可以访问IPv4/IPv6隧道元数据,并且通常使用eBPF附带的帮助程序和实用程序。
用于与流量控制相关的网络配置进行交互的工具是iproute2套件的一部分,其中包含ip和tc,它们分别用于操作网络接口和流量控制配置。
术语
如前所述,Traffic Control和BPF程序之间存在交互点,因此你需要了解一些Traffic Control概念。 如果你已经掌握相关术语,请直接进入示例。
Queueing disciplines
排队规则(qdisc)定义了调度对象,通过更改发送方式对进入接口的数据包排队;这些对象可以是无类的或有类的。
默认的qdisc是pfifo_fast,它是无类的,将数据包入队到三个FIFO(先进先出)队列中,这些队列根据它们的优先级出队;此qdisc不用于虚拟设备,例如使用noqueue的环回(lo)或虚拟以太网设备(veth)。除了作为其调度算法的默认值外,pfifo_fast也不需要任何配置即可工作。
通过访问/sys伪文件系统,可以将虚拟接口与物理接口(设备)区分开来:
1 | [root@VM-16-14-centos cpt6]# ls -la /sys/class/net/ |
如果你从未听说过qdiscs,可以使用ip a命令显示当前系统中配置的网络接口列表:
1 | [root@VM-16-14-centos cpt6]# ip a |
从上述结果我们可以看到
- 在我们的系统中有两个网络接口:
lo和eth0 lo接口是一个虚拟接口,所以它是qdisc noqueueeth0是一个物理接口。 这里的qdisc是fq_codel(公平队列控制延迟)默认不应该是pfifo_fast吗? 事实证明,我们正在测试命令的系统正在运行Systemd,它使用内核参数net.core.default_qdisc以不同的方式设置默认qdisc。
noqueue qdisc没有类、调度程序或分类器。它的作用是尝试立即发送数据包。如前所述,虚拟设备默认使用noqueue,但当你删除其当前关联的qdisc时,它也是对任何接口生效的。
fq_codel是一个无类别的qdisc,它使用随机模型对传入的数据包进行分类,以便能够以公平的方式对流量进行排队。
我们使用ip命令来查找有关qdiscs的信息,但事实证明,在iproute2工具中还有一个名为tc的工具,它具有qdiscs的特定子命令,查看方式如下所示:
1 | [root@VM-16-14-centos cpt6]# tc qdisc ls |
对于lo,我们基本上看到与ip a相同的信息,但对于eth0,它具有以下信息:
- 它有能够处理10240个传入数据包的限制。
- 如前所述,
fq_codel使用的随机模型希望将流量排队到不同的流中,此输出包含有关我们拥有多少个流的信息,即1024。
在下一节中我们可以仔细研究有类和无类qdiscs以了解它们的区别以及哪些适合BPF程序。
Classful qdiscs, filters, and classes
Classful qdiscs允许为不同类型的流量定义类,以便对它们应用不同的规则。拥有一个 qdisc的类意味着它可以包含更多的qdisc。有了这种层次结构,我们可以使用过滤器(分类器)通过确定数据包应该入队的下一个类别来对流量进行分类。
过滤器用于根据数据包的类型将数据包分配给特定的类。 过滤器在一个有类的qdiscs中用于确定数据包应该在哪个类中排队,并且两个或多个过滤器可以映射到同一个类,如下图所示。 每个过滤器都使用分类器根据数据包的信息对数据包进行分类。
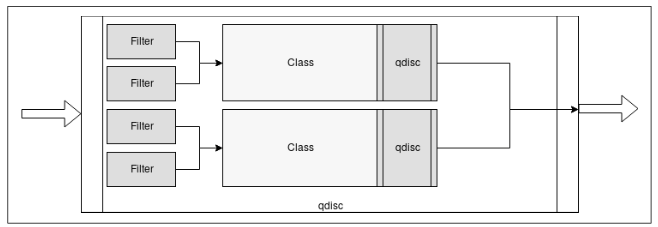
如前所述,cls_bpf是我们想用来为流量控制编写BPF程序的分类器——下一节中有一个具体的例子来说明如何使用它。
Classes是只能存在于有类qdisc中的对象;Classes在交通控制中用于创建层次结构。一个类可以附加过滤器,这样就可以实现复杂的层次结构,然后可以将其用作另一个class或qdisc的入口点。
Classless qdiscs
无类的qdisc不能有任何孩子的qdisc,因为它不允许有任何关联的类。这意味着不可能将过滤器附加到无类qdisc。我们不能给它们添加过滤器和分类器,从BPF的角度来看,无类 qdisc并不有趣,但对于简单的流量控制需求仍然有用。
在积累了一些关于qdiscs、过滤器和类的知识之后,我们将展示如何为cls_bpf分类器编写BPF程序。
使用cls_bpf的流量控制分类器程序
流量控制是一种强大的机制,分类器使得它变得更加强大;但是,在所有分类器中,有一个允许你对网络数据路径cls_bpf分类器进行编程。这个分类器很特别,因为它可以运行BPF程序,这意味着cls_bpf将允许你直接在入口和出口层中hookBPF程序,并且运行hook到这些层的BPF程序能够访问相应数据包的sk_buff结构。
为了更好地理解流量控制和BPF程序之间的这种关系,请参见下图使用流量控制加载BPF程序,它显示了如何根据cls_bpf分类器加载BPF程序。
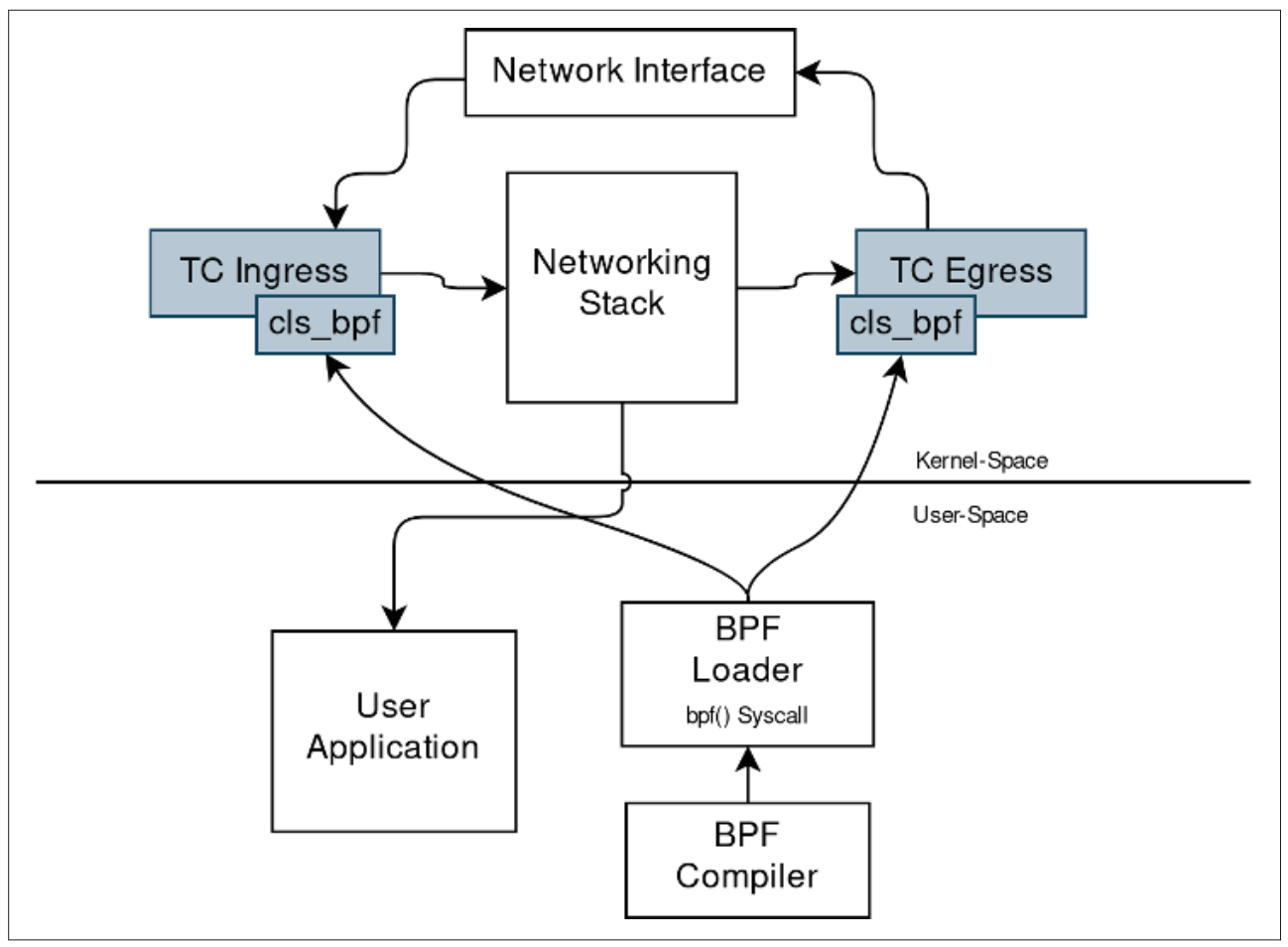
你会注意到此类程序被hook到入口和出口qdiscs。还描述了上下文中的其他交互。通过将网络接口作为网络流量的入口点,你会看到以下内容:
- 流量首先进入流量控制的入口钩子。
- 然后内核将为每个进入的请求执行从用户空间加载到入口的BPF程序。
- 入口程序执行后,控制权交给网络堆栈,通知用户应用程序有关网络事件。
- 在应用程序给出响应后,控制权会通过另一个执行的BPF程序传递给
Traffic Control的出口,并在完成后将控制权交还给内核。 - 给客户端一个响应。
你可以使用C语言编写用于流量控制的BPF程序,并使用带有BPF后端的LLVM/Clang编译它们。
为了使这个例子工作,你需要在一个直接用cls_bpf编译的内核上运行它,或者作为一个模块运行它。要验证是否拥有所需的一切,可以执行以下操作:
1 | cat /proc/config.gz| zcat | grep -i BPF |
报错如下
1 | [root@VM-16-14-centos ~]# cat /proc/config.gz| zcat | grep -i BPF |
对此我们可以从系统/usr/src/kernel目录下获取
1 | 确保至少得到以下带有 y 或 m 的输出:[root@VM-16-14-centos ~]# uname -r |
确保至少得到以下带有y或m的输出:
1 | CONFIG_BPF=y |
现在我们看看如何编写分类器:
1 | SEC("classifier") |
我们分类器主要是分类功能。这个函数用一个称为classifier的节标题进行注释,以便tc可以知道这是要使用的分类器。
此时,我们需要从skb中提取一些信息;数据成员包含当前数据包的所有数据及其所有协议细节。为了让我们写的程序知道其中的内容,需要将其转换为以太网帧(在我们的例子中,使用 *eth变量)。为了让静态验证器满意,我们需要检查数据,加上eth指针的大小,不超过 data_end所在的空间。之后,我们可以从*eth中的h_proto成员中获取协议类型:
1 | if (h_proto == bpf_htons(ETH_P_IP)) { |
有了协议后,我们需要从主机转换它,检查它是否和我们的IPv4协议相等,如果是,我们使用我们自己的is_http函数检查内部数据包是否为HTTP,如果是HTTP的话,我们打印一条调试消息,说明我们找到了一个HTTP数据包:
1 | void *data_end = (void *)(long)skb->data_end; |
is_http函数类似于我们的分类器函数,但它会通过已知的IPv4协议数据的起始偏移量来从skb开始。正如我们之前所做的,我们需要在使用*iph变量访问IP协议数据之前进行检查,以让静态验证者知道我们的目的。完成后,我们只需检查IPv4头是否包含TCP数据包,以便我们继续。如果数据包的协议是IPPROTO_TCP类型,我们需要再次进行一些检查以获取*tcph变量中的实际TCP头:
1 | plength = ip_total_length - ip_hlen - tcp_hlen; |
获得TCP头之后,我们可以继续从skb结构中加载前七个字节,位于TCP有效负载poffset的偏移量处。此时我们可以检查字节数组是否是一个表示HTTP的序列;第7层协议是HTTP,返回1,否则返回0。
classifier.c完整程序如下
1 |
|
实用Clang编译如下
1 | clang -O2 -target bpf -c classifier.c -o classifier.o |
tc返回码说明
1 | TC_ACT_OK (0) , will terminate the packet processing pipeline and |
现在我们可以在eth0上安装程序。
第一个命令将替换eth0设备的默认qdisc,第二个命令将我们的cls_bpf分类器加载到ingress的有类qdisc。这意味着我们的程序将处理进入该接口的所有流量。如果我们想处理传出流量,我们需要使用egress qdisc代替:
1 | tc qdisc add dev eth0 handle 0: ingress |
程序现在已被加载——我们需要向该接口发送一些HTTP流量。直接python起一个服务器
1 | [root@VM-16-14-centos tc]# python3 -m http.server |
之后通过tc获取调试信息
1 | [root@VM-16-14-centos tc]# tc exec bpf dbg |
最后通过tc卸载分类器
1 | [root@VM-16-14-centos tc]# tc qdisc del dev eth0 ingress |
关于act_bpf以及cls_bpf的不同之处的说明
你可能已经注意到BPF程序存在另一个名为act_bpf的对象。act_bpf是一个动作,而不是分类器。在操作上与分类器有所不同,因为动作是附加到过滤器的对象,因此它不能直接执行过滤,需要流量控制所有数据包。对于此属性,通常最好使用cls_bpf分类器而不是act_bpf操作。
TC和XDP的区别
尽管tc的cls_bpf和XDP程序看起来非常相似,但它们却大不相同。XDP程序在进入主内核网络堆栈之前在入口数据路径中较早执行,因此我们的程序无法像tc那样访问套接字缓冲区结构 sk_buff。XDP程序取而代之的是一个称为xdp_buff的不同结构,它是没有元数据的数据包表示。例如,即使在内核代码之前执行,XDP程序也可以有效地丢弃数据包。 与tc程序相比XDP程序只能附加到进入系统的流量。
你可能会问什么时候使用XDP?答案是,由于XDP程序不包含所有内核丰富的数据结构和元数据的性质,因此更适合OSI模型的1到4层。
结论
现在你应该很清楚BPF程序对于在网络数据路径的不同级别获得可见性和控制很有用。也已经了解了如何利用它们来过滤数据包,使用生成BPF程序集的高级工具。然后我们将程序加载到网络套接字,最后我们将程序附加到流量控制入口qdisc以使用BPF程序进行流量分类。在本章中,我们还简要讨论了XDP,后续我们会通过扩展 XDP 程序的构建方式、XDP程序的类型以及如何编写和测试它们来完整学习XDP。
第七章节
Express Data Path
快速数据路径(XDP)是Linux网络数据路径中安全、可编程、高性能、内核集成的数据包处理器,当NIC驱动程序接收到数据包时,它会执行BPF程序。这允许XDP程序在尽可能早的时间点就对接收到的数据包做出决定(丢弃、修改或仅允许)。
执行点并不是使XDP程序快速运行的唯一方面;其他设计决策在其中也发挥作用:
- 使用XDP进行数据包处理时没有内存分配。
- XDP程序仅适用于线性的、未分段的数据包,并且含有数据包的开始和结束指针。
- 无法访问完整的数据包元数据,这就是为什么这种程序接收的输入上下文将是
xdp_buff类型,而不是在之前遇到的sk_buff结构。 - 因为是eBPF程序,所以XDP程序具有有限的执行时间,其结果是它们的使用在网络管道中具有固定成本。
谈到XDP时,重要的是要记住它不是内核绕过机制;它旨在与其他内核组件和内部Linux安全模型集成。
1 | xdp_buff结构用于向使用XDP框架提供的直接数据包访问机制的BPF程序提供数据包上下文。可以将其视为sk_buff的“轻量级”版本。 |
XDP程序概述
从本质上讲,XDP程序所做的是对接收到的数据包做出决定,然后编辑接收到的数据包的内容或仅返回结果代码。结果代码用于以操作的形式确定数据包发生的情况。你可以丢弃这个包,可以把它从同一个接口传输出去,或者可以把它传递给网络栈的其余部分。此外,为了与网络栈协作,XDP程序可以推送和拉取数据包的头部;例如,如果当前内核不支持封装格式或协议,XDP程序可以将其解封装或翻译协议并将结果发送给内核进行处理。
但是XDP和eBPF之间有什么关联呢?
事实证明,XDP程序是通过bpf系统调用控制并使用程序类型BPF_PROG_TYPE_XDP加载的。 此外,执行驱动程序挂钩也要执行BPF字节码。
编写XDP程序时要理解的一个重要概念是它们将运行的上下文也称为操作模式。
操作模式
XDP具有三种操作模式,以适应测试功能、供应商定制硬件以及无需定制硬件的常用构建内核。
原生XDP
这是默认模式。在这种模式下,XDP BPF程序直接在网络驱动程序的接收路径之外运行。使用此模式时,请务必检查驱动程序是否支持。 您可以通过对给定内核版本的源代码树执行以下命令来检查:
1 | [root@VM-16-14-centos ~]# cd linux-4.18/ |
可以看到,内核 4.18 支持以下内容:
- Broadcom NetXtreme-C/E network driver bnxt
- Caviumthunderxdriver
- Inteli40driver
- Intelixgbeandixgvevfdrivers
- Mellanoxmlx4andmlx5drivers
- Netronome Network Flow Processor
- QLogic qede NIC Driver
- TUN/TAP
- Virtio
卸载XDP
在这种模式下,XDP BPF程序直接卸载到NIC中,而不是在主机CPU上执行。 通过将执行从CPU中推开,这种模式比原生XDP具有更高的性能提升。
通过在源码中查找XDP_SETUP_PROG_HWs来检查4.18中哪些NIC驱动程序支持硬件卸载:
1 | [root@VM-16-14-centos linux-4.18]# git grep -l XDP_SETUP_PROG_HW drivers/ |
这仅显示了Netronome网络流处理器(nfp),意味着它还可以通过支持硬件卸载和本机XDP两种模式运行。
如果我没有网卡和驱动程序来尝试我的XDP程序时,我该怎么办? 答案很简单,通用XDP!
通用XDP
这是为想要编写和运行XDP程序但不具备本机或卸载XDP功能的开发人员提供的一种测试模式。从内核版本4.12开始支持通用XDP。例如可以在veth设备上使用此模式而无需购买特定的硬件来跟随。
但是谁是负责协调所有组件和操作模式的参与者呢? 下一节我们将学习数据包处理器。
数据包处理器
XDP数据包处理器可以在XDP数据包上执行BPF程序并协调它们与网络堆栈之间的交互。数据包处理器是XDP程序的内核组件,它直接处理接收(RX)队列上的数据包,因为它们由NIC呈现。它确保数据包是可读和可写的,并允许以数据包处理器操作的形式附加后处理判决。可以在运行时完成对数据包处理器的原子程序更新和新程序加载,而不会在网络和相关流量方面造成任何服务中断。在运行时,XDP可以在“忙轮询”模式下使用,允许保留必须处理每个RX队列的CPU;这避免了上下文切换,并允许在到达时立即响应数据包,而不管IRQ亲缘关系如何。 XDP可以使用的另一种模式是“中断驱动”模式,另一方面,它不保留CPU,而是作为事件媒介的中断通知CPU必须处理新事件,同时仍可以做正常的处理。
在下图中可以看到RX/TX、应用程序、数据包处理器和应用于数据包的BPF程序之间的交互点。
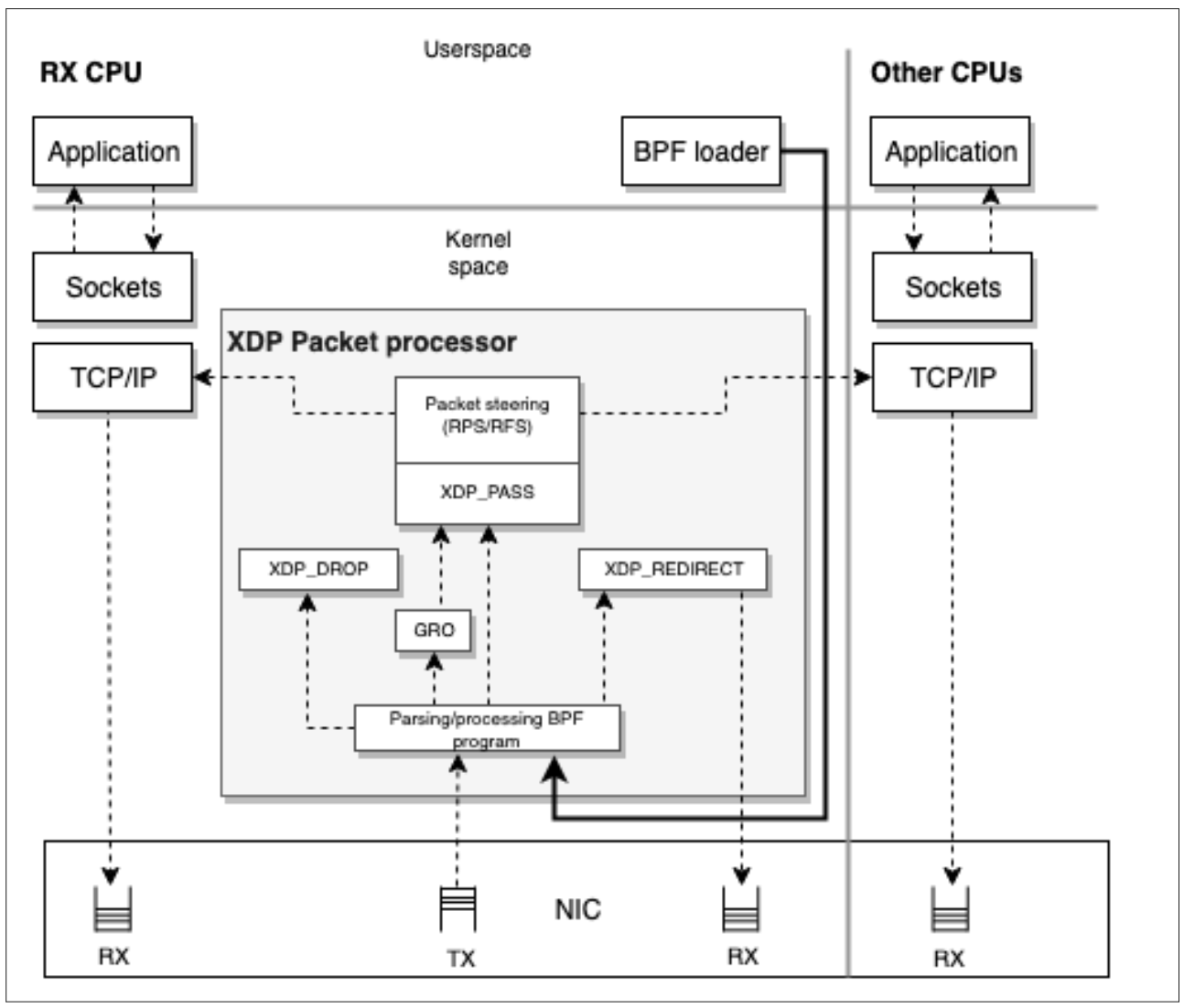
请注意在上图中有几个带有XDP_前缀的字符串方块。 这些是我们接下来介绍的XDP结果代码。
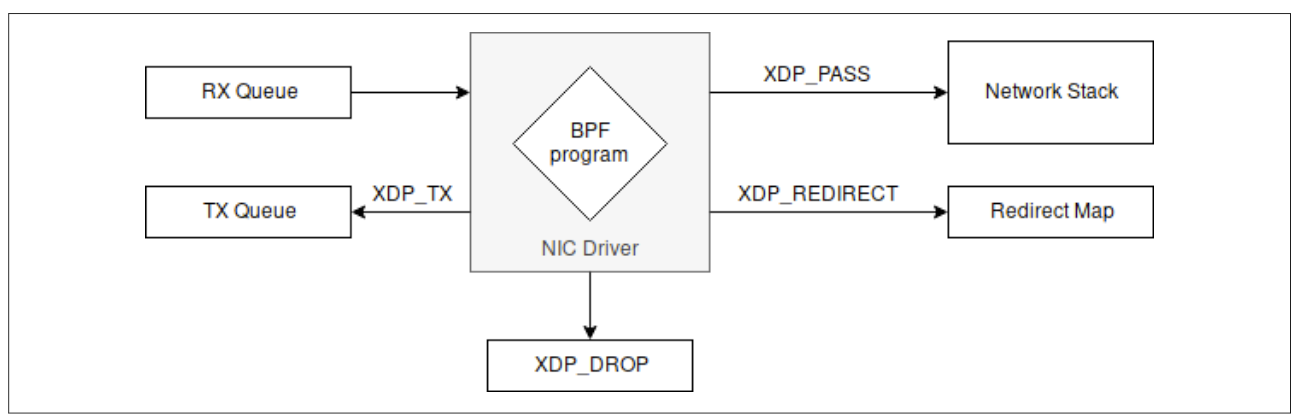
XDP结果代码(数据包处理器操作)
在数据包处理器对数据包做出决定后,可以使用五个返回代码之一来表示,然后可以指示网络驱动程序如何处理数据包:
DROP(XDP_DROP)
丢弃数据包。这发生在驱动程序中最早的RX阶段;丢弃一个数据包只是意味着将它回收到它刚刚“到达”的RX环形队列中。尽早丢弃数据包是缓解拒绝服务(DoS)的关键。这样,丢弃的数据包会使用尽可能少的CPU处理时间和功率。
Forward (XDP_TX)
转发数据包。 这可能发生在数据包被修改之前或之后。转发数据包意味着将接收到的数据包页面弹回它到达的同一个NIC。
Redirect (XDP_REDIRECT)
与
XDP_TX类似,它能够传输XDP数据包,但它是通过另一个NIC或BPF cpumap来传输的。在BPF cpumap的情况下,在NIC的接收队列上为XDP服务的CPU可以继续这样做,并将用于处理上层内核堆栈的数据包推送到远程CPU。这类似于XDP_PASS,但XDP BPF程序可以继续为传入的高负载提供服务。Pass(XDP_PASS)
将数据包传递给正常的网络堆栈进行处理。这相当于没有XDP的默认数据包处理行为。 通过以下两种方式之一完成:
- 正常接收分配元数据(sk_buff),将数据包接收到堆栈上,并将数据包引导到另一个 CPU进行处理。 它允许用户空间的原始接口。 这可能发生在数据包被修改之前或之后。
- 通用接收卸载(GRO)可以接收大数据包并合并同一连接的数据包。GRO在处理后最终将数据包通过“正常接收”流程。
Code error (XDP_ABORTED)
表示eBPF程序错误并导致数据包被丢弃。 它不是函数式程序应该用作返回码的东西。例如,如果程序除以零,将返回XDP_ABORTED。 XDP_ABORTED的值将始终为零。它通过
trace_xdp_exception跟踪点可以额外监视该跟踪点以检测不当行为。
这些动作代码在linux/bpf.h头文件中表示如下:
1 | enum xdp_action { |
因为XDP动作决定了不同的行为并且它是一种数据包处理器的内部机制,所以可以查看如下图的简化版本,仅关注返回动作。
XDP程序的一个有趣之处在于,你通常不需要编写加载程序来加载它们。在大多数Linux机器中都有通过ip命令实现的比较好的加载程序。下一节将介绍如何使用它。
XDP和iproute2作为加载器
iproute2中可用的ip命令能够充当前端来加载编译成ELF文件的XDP程序,并且完全支持映射、映射重定位、尾调用和对象固定。
因为加载XDP程序可以表示为对现有网络接口的配置,所以加载程序作为ip link命令的一部分实现,该命令用于配置网络设备。
接下来让我们尝试一个例子
场景是我们有一个系统,在端口8000上有一个Web服务器,我们希望通过禁止所有 TCP 连接来阻止对其在服务器的面向公众的NIC上的任何页面的访问。
首先我们可以通过python起一个简单的服务器
1 | [root@VM-16-14-centos ~]# python3 -m http.server |
在网络服务器启动后,它的开放端口将显示在使用ss的开放套接字中。网络服务器绑定到任何接口 *:8000,因此到目前为止,任何可以访问我们公共接口的外部调用者都可以看到它的内容!
1 | [root@VM-16-14-centos ~]# ss -tulpn |
1 | 套接字统计信息,终端中的 ss,是一个命令行实用程序,用于调查 Linux 中的网络套接字。 它实际上是netstat 的现代版本,其用户体验类似于 Netstat,这意味着您可以传递相同的参数并获得可比较的结果。 |
你可以使用nmap检查远程主机上的开放端口,如下所示:
1 | [root@VM-16-14-centos ~]# ip a |
通过nmap可以看到8000端口,现在我们要封锁该端口
我们的程序将包含一个名为program.c的源文件,它需要使用IPv4 iphdr和以太网帧ethhdr 标头结构以及协议常量和其他结构。 让我们包含所需的标题,如下所示:
1 |
包含头文件后,我们可以使用在前面章节中已经遇到的SEC宏,用于声明ELF属性。
1 |
现在我们可以声明程序的主入口点myprogram及ELF节名称mysection。 我们的程序将xdp_md结构指针作为输入上下文,它是驱动程序内xdp_buff的BPF等价物。 通过使用它作为上下文,我们定义接下来将使用的变量,例如数据指针、以太网和IP层结构:
1 | SEC("mysection") |
因为数据包含以太网帧,我们现在可以从中提取IPv4层。我们还检查IPv4层的偏移量是否不超过整个指针空间,以便能够通过静态验证器。当超出地址空间时,我们会丢弃数据包:
1 | ipsize = sizeof(*eth); |
在所有的验证和设置之后,我们可以实现程序的真正逻辑,它基本上丢弃每个TCP数据包,同时允许其他任何东西:
1 | if (ip->protocol == IPPROTO_TCP) { |
至此我们的程序就完成了,program.c完整程序代码如下
1 |
|
下一步是使用Clang从我们的程序中编译出ELF文件program.o。我们可以在目标机器之外执行此编译步骤,因为BPF ELF二进制文件不依赖于平台,对program.c编译如下
1 | [root@VM-16-14-centos cpt7]# clang -g -c -O2 -target bpf -c program.c -o program.o |
现在我们可以使用ip实用程序和set命令将program.o加载到公共网络接口eth0上,加载XDP程序的语法很简单:
1 | [root@VM-16-14-centos cpt7]# ip link set dev eth0 xdp obj program.o sec mysection |
对上述命令的分析如下
ip:调用ip命令
link:配置网络接口
set:更改设备属性
dev eth0:指定我们要在其上操作和加载XDP程序的网络设备
xdp obj program.o:从名为program.o的ELF文件(对象)加载XDP程序。 此命令的xdp部分告诉系统在可用时使用本机驱动程序,否则回退到通用驱动程序。你可以通过使用更具体的选择器来强制使用一种或另一种模式:
- xdpgeneric to use generic XDP
- xdpdrv to use native XDP
- xdpoffload to use offloaded XDP
sec mysection:指定包含要从ELF文件中使用的BPF程序的节名mysection; 如果未指定,将使用名为prog的部分。 如果程序中未指定任何部分,则必须在ip调用中指定sec .text。
在这个阶段,如果该命令返回零作为退出代码且没有错误,我们可以检查网络接口以查看程序是否已正确加载:
1 | [root@VM-16-14-centos ~]# ip a show eth0 |
通过ip a输出了新的细节;在MTU后面显示xdpgeneric/id:32,它显示了两个有趣的信息:
- 曾经使用过的驱动,xdpgeneric
- XDP程序的ID,32
最后一步是验证加载的程序是否确实在做它应该做的事情。我们可以通过在外部机器上再次执行nmap来观察端口8000不再可访问来验证这一点:
1 | [root@VM-16-14-centos ~]# nmap -sS 10.0.16.14 |
另一个验证它是否正常工作的测试是尝试通过浏览器访问程序或执行任何HTTP请求。 以10.0.16.14为目标时,任何类型的测试都应该失败。 这样我们就成功加在了第一个XDP程序!
如果您在需要恢复到原始状态的机器上执行了所有这些步骤,则可以随时分离程序并关闭设备的XDP:
1 | ip link set dev eth0 xdp off |
在使用iproute2作为加载器时可以跳过自己编写加载器的部分。在这个例子中,我们的重点是iproute2,它已经为XDP程序实现了一个加载器。这些程序实际上是BPF程序,因此即使iproute2有时很方便,你可以使用 BCC 加载程序,例如在下一节你可以直接使用bpf系统调用。拥有自定义加载器的优点是允许管理程序的生命周期及其与用户空间的交互。
XDP和BCC
与其他BPF程序一样,可以使用BCC编译、加载和运行XDP程序。 接下来的示例显示了一个XDP程序,它与我们用于iproute2的程序类似,但它具有BCC制作的自定义用户空间加载程序。在这种情况下需要加载程序是因为要计算在丢弃TCP数据包时遇到的数据包数量。
首先还是创建一个名为program.c的内核空间程序。
在iproute2示例中,我们的程序需要为与BPF和协议相关的结构和函数定义导入所需的头文件。这里我们做同样的事情,但我们还使用BPF_TABLE宏声明了BPF_MAP_TYPE_PERCPU_ARRAY类型的映射。 该映射将包含每个IP协议索引的数据包计数器,这就是大小为256的原因(IP规范仅包含256个值)。 我们想使用BPF_MAP_TYPE_PERCPU_ARRAY类型,因为它可以保证CPU级别的计数器的原子性:
1 |
|
之后声明主函数myprogram,它将xdp_md结构作为参数。 首先需要包含的是以太网IPv4帧的变量声明:
1 | int myprogram(struct xdp_md *ctx) { |
在我们完成所有变量声明并且可以访问包含以太网帧的数据指针和带有IPv4数据包的ip指针之后,我们可以检查内存空间是否超出范围。 如果是,我们丢弃数据包。 如果内存空间没问题,我们提取协议并查找packetcnt数组以获取变量idx中当前协议的数据包计数器的先前值。然后将计数器加一。处理完增量后,我们可以继续检查协议是否为TCP。 如果是,我们就直接丢弃数据包:
1 | if (data + ipsize > data_end) { |
program.c完整程序如下
1 |
|
现在可以编写加载程序loader.py
它由两部分组成:实际加载逻辑和打印数据包的循环计数。
对于加载逻辑,我们通过读取文件program.c打开程序。 通过load_func指示bpf系统调用使用程序类型 BPF.XDP将myprogram函数用作“main”。 这代表`BPF_PROG_TYPE_XDP 。
加载后,我们可以使用get_table访问名为packetcnt的BPF映射。
1 | #!/usr/bin/python |
我们需要编写的剩余部分是打印数据包计数的实际循环。我们有两个循环。 外部循环获取键盘事件并在有信号中断程序时终止。当外循环中断时,将调用remove_xdp函数,并将接口从XDP程序中释放出来。
在外循环中,内循环的职责是从packetcnt映射中取回值并格式化打印它们:counter pkt/s:
1 | prev=[0]*256 |
loader.py程序完整如下
1 | #!/usr/bin/python3 |
现在我们可以通过简单地使用执行加载程序来测试该程序:
1 | [root@VM-16-14-centos bcc]# python3 loader.py |
现在我们已经加载了程序,可以通过eth0接口发送一些数据包,ping是一个很好的尝试方法。
1 | [root@VM-16-14-centos bcc]# ping 10.0.16.14 |
之后可以看到程序开始打印结果。
1 | Printing packet counts per IP protocol-number, hit CTRL+C to stop |
测试XDP程序
在开发XDP程序时,最困难的部分是为了测试实际的数据包流需要重现一个环境,其中所有组件都对齐以提供正确的数据包。尽管现在使用虚拟化技术,创建工作环境确实是一件容易的事,但复杂的设置也会限制测试环境的可重复性和可编程性,这也是事实。 除此之外,在虚拟化环境中分析XDP程序的性能方面时,虚拟化的成本使测试无效,因为它比实际的数据包处理要可观得多。
幸运的是,内核开发人员有一个解决方案。他们实现了一个可用于测试XDP程序的命令,称为BPF_PROG_TEST_RUN。
本质上,BPF_PROG_TEST_RUN让XDP程序连同一个输入包和一个输出包一起执行。 程序执行时,会填充输出数据包变量,并返回XDP代码。 这意味着你可以在断言测试中使用输出数据包和返回代码!这种技术也可以用于skb程序。
为了完整测试这个示例,我们使用Python及其单元测试框架。
使用Python单元测试框架测试XDP程序
使用BPF_PROG_TEST_RUN编写XDP测试并将它们与Python单元测试框架unittest集成是一个好主意,原因如下:
- 你可以使用Python BCC库加载和执行BPF程序
- Python拥有最好的数据包制作和自省库之一:
scapy - Python通过
ctypes与C结构集成
如前所述,我们需要导入所有需要的库;这是我们将在名为test_xdp.py的文件中做的第一件事:
1 | from bcc import BPF, libbcc |
导入所有需要的库后,我们可以继续并创建一个名为XDPExampleTestCase的测试用例类。 这个测试类将包含我们所有的测试用例和成员方法(_xdp_test_run),我们将使用它来进行断言并调用bpf_prog_test_run。
1 | def _xdp_test_run(self, given_packet, expected_packet, expected_return): |
该函数有三个参数
given_packet:这是我们测试XDP程序的数据包; 它是接口接收到的原始数据包。
expected_packet:这是我们期望在XDP程序处理后收到的数据包;当XDP程序返回XDP_DROP或XDP_ABORT时,我们希望它为None;在所有其他情况下,数据包与given_packet保持相同或可以修改。
expected_return:这是处理我们的given_packet后XDP程序的预期返回。
除了参数之外,这个方法的主体很简单。它使用ctypes库转换为C类型,然后调用与BPF_PROG_TEST_RUN等效的libbcc,libbcc.lib.bpf_prog_test_run,使用我们的数据包及其元数据作为测试参数。然后根据测试调用的结果以及给定的值执行所有断言。
有了这个功能之后,我们基本上可以通过制作不同的数据包来测试它们在通过我们的XDP程序时的行为方式来编写测试用例,但在此之前,我们需要为我们的测试做一个setUp方法。
这部分至关重要,因为安装程序通过打开并编译名为program.c的源文件(这是我们的XDP代码所在的文件)来执行名为myprogram的BPF程序的实际加载:
1 | def setUp(self): |
设置完成后,下一步是编写我们要观察的第一个行为。我们想测试一下我们是否会丢弃所有TCP数据包。
所以我们在given_packet中制作了一个数据包,它只是一个基于IPv4的TCP数据包。 然后,使用我们的断言方法_xdp_test_run,我们只是验证给定我们的数据包,我们将返回一个没有返回数据包的 XDP_DROP:
1 | def test_drop_tcp(self): |
我们还想明确测试是否允许所有UDP数据包。 然后我们制作两个UDP数据包,一个用于given_packet,一个用于expected_packet,它们本质上是相同的。 通过这种方式,我们测试UDP数据包在XDP_PASS允许的情况下不会被修改:
1 | def test_pass_udp(self): |
为了让事情变得更复杂一点,我们决定这个系统将允许TCP数据包在它们到达端口9090的条件下。它们将被重写以更改目标MAC地址以重定向到特定的网络。地址为08:00:27:dd:38:2a的工作接口。
1 | def test_transform_dst(self): |
有了大量的测试用例,我们现在为我们的测试程序编写入口点,它只会调用 unittest.main() 然后加载并执行我们的测试:
1 | if __name__ == '__main__': |
test_xdp.py完整程序如下
1 | from bcc import BPF, libbcc |
我们已经为XDP程序编写了测试!现在我们已经将测试作为我们想要的特定示例,我们可以通过创建一个名为program.c的文件来编写实现它的XDP程序。
程序很简单。它只包含myprogram XDP函数和我们刚刚测试的逻辑。与往常一样,我们需要做的第一件事是包含所需的标题。有一个BPF程序将处理通过以太网传输的TCP/IP:
1 |
同样,与本章中的其他程序一样,我们需要检查数据包三层的偏移量和填充变量:ethhdr、iphdr和 tcphdr,分别用于以太网、IPv4和TCP:
1 | int myprogram(struct xdp_md *ctx) { |
一旦有了值,我们就可以实现相应逻辑。
第一件要做的事是检查协议是否为TCP ip->protocol == IPPROTO_TCP。 如果是,我们总是做一个XDP_DROP; 否则,对其他所有内容执行XDP_PASS。
在检查TCP协议时,我们做另一个控制来检查目标端口是否为9090,th->dest == htons(9090); 如果是,我们在以太网层改变目的MAC地址,返回XDP_TX,通过同一个网卡反弹数据包:
1 | if (ip->protocol == IPPROTO_TCP) { |
program.c完整程序如下
1 |
|
现在可以运行我们的测试程序
1 | [root@VM-16-14-centos prog-test-run]# python3 test_xdp.py |
XDP用例
监控
现在,大多数网络监控系统要么通过编写内核模块来实现,要么通过从用户空间访问proc文件来实现。 编写、分发和编译内核模块并不是每个人的任务。 它们也不容易维护和调试。 然而,替代方案可能更糟。 要获得相同类型的信息,例如一张卡在一秒钟内收到多少个数据包,您需要打开并分割一个文件,在本例中是 /sys/class/net/eth0/statistics/rx_packets。 这似乎是一个好主意,但它需要大量的计算才能获得一些简单的信息,因为在某些情况下使用开放系统调用并不便宜。
因此我们需要一个解决方案,能够实现与内核模块类似的功能,而不会损失性能。XDP是完美的,因为我们可以使用XDP程序发送我们想要在映射中提取的数据。然后映射被加载器使用,加载器可以将指标存储到存储后端并对其应用算法或将结果绘制在图中。
缓解DDoS
能够在NIC级别查看数据包可确保在第一阶段拦截任何可能的数据包,此时系统尚未花费足够的计算能力来了解数据包是否对系统有用。在典型的场景中,bpf map可以指示XDP程序从某个源XDP_DROP数据包。在分析通过另一个映射接收到的数据包之后,可以在用户空间中生成该数据包列表。一旦流入XDP程序的数据包与列表中的元素匹配,就会发生缓解。 数据包被丢弃,内核甚至不需要花费一个CPU周期来处理它。这导致攻击者的目标难以实现,因为在这种情况下,它无法浪费任何昂贵的计算资源。
负载均衡
XDP程序的一个有趣用例是负载平衡。 但是,XDP只能在数据包到达的同一个NIC上重新传输数据包。这意味着XDP不是实现经典负载均衡器的最佳选择,该负载均衡器位于所有服务器之前并将流量转发给它们。但是,这并不意味着XDP不适合这个用例。 如果我们将负载平衡从外部服务器转移到为应用程序提供服务的同一台机器上,则可以看到NIC是如何完成这项工作。
通过这种方式,我们可以创建一个分布式负载均衡器,其中每台托管应用程序的机器都有助于将流量分散到适当的服务器。
防火墙
当人们想到Linux上的防火墙时,通常会想到iptables或网络过滤器。 使用XDP可以直接在NIC或其驱动程序中以完全可编程的方式获得相同的功能。通常,防火墙是位于网络堆栈顶部或节点之间的昂贵机器,用于控制其通信。然而,当使用XDP时,因为XDP程序非常便宜和快速,我们可以将防火墙逻辑直接实现到节点的NIC中,而不是使用一组专用机器。一个常见的用例是有一个XDP加载器来控制一个映射,其中包含一组通过远程过程调用API更改的规则。 然后,映射中的一组规则会动态地传递给加载到每台特定机器中的XDP程序,以控制它可以接收什么、从谁以及在什么情况下接收。
这种替代方案不仅降低了防火墙成本; 它还允许每个节点部署自己的防火墙级别,而无需依赖用户空间软件或内核来执行此操作。当使用offloaded的XDP作为操作模式进行部署时会有更大优势,因为处理甚至不需要主节点CPU完成。
结论
从现在开始,XDP将帮助你以一种完全不同的方式思考网络流。处理网络数据包时不得不依赖iptables或其他用户空间工具等工具令人沮丧。XDP则很有趣,因为它具有直接的数据包处理能力,因此速度更快,而且你可以编写自己的逻辑来处理网络数据包。因为所有这些代码都可以与映射一起使用并与其他BPF程序交互。
第八章节
Linux内核Security、Capabilities和Seccomp
BPF是一种在不影响稳定性、安全性和速度的情况下扩展内核的强大方法。出于这个原因,内核开发人员认为,通过实现由BPF 程序(也称为 Seccomp BPF)支持的Seccomp过滤器,利用其多功能性来改善 Seccomp中的进程隔离会是一件好事。在本章中,我们将研究Seccomp是什么以及如何使用它。 然后你会学习如何使用BPF程序编写Seccomp过滤器。 最后将探索内核为Linux安全模块提供的内置BPF挂钩。
Linux安全模块 (LSM) 是一个框架,它提供了一组功能,可用于以标准化方式实现不同的安全模型。LSM可以直接在内核源代码树中使用,例如Apparmor、SELinux和Tomoyo
Capabilities
Linux功能的处理是你需要为非特权进程提供执行特定任务的权限,但你不想将suid权限授予二进制文件或以其他方式使进程具有特权,因此只需通过减少攻击面赋予流程完成特定任务的特定能力。例如,如果你的应用程序需要打开一个特权端口,比如 80,而不是以root身份启动进程,你可以给它CAP_NET_BIND_SERVICE能力。
考虑如下main.go程序
1 | package main |
该程序在端口80(一个特权端口)上为HTTPserver提供服务。
我们通常会做的是在使用以下代码编译后直接运行该程序:
1 | [elssm@VM-16-14-centos ~]$ go build -o capabilities main.go |
但是,由于我们没有授予root权限,因此绑定端口时该代码会输出错误:
在这种情况下,如上所述,我们可以通过允许cap_net_bind_service功能以及程序已经拥有的所有其他功能来允许特权端口的绑定,而不是给予完全的root权限。 为此,我们可以使用capsh包装我们的程序运行:
1 | [root@VM-16-14-centos cpt8]# capsh --caps='cap_net_bind_service+eip cap_setpcap,cap_setuid,cap_setgid+ep' --keep=1 --user="nobody" --addamb=cap_net_bind_service -- -c "./capabilities" |
capsh:使用capsh作为装饰器
—caps=’cap_net_bind_service+eip cap_setpcap,cap_setuid,cap_setgid+ep’:因为我们需要更改用户(我们不想以root身份运行),所以我们需要指定cap_net_bind_service以及实际将用户ID从root 更改为nobody的能力,即cap_setuid和cap_setgid:
—keep=1:当从root切换完成时,我们希望保留设置的功能
—user=’nobody’:运行我们程序的最终用户将是任何人
—addamb=cap_net_bind_service:我们设置了环境功能,因为这些功能在从root切换后会被清除。
— -c “./capabilities”:一切就绪,运行程序
此时你可能会问在--caps选项中的功能之后的+eip是什么:
- 需要激活该功能(p)
- 该能力是可用的(e)
- 该能力可以由子进程继承(i)
因为我们要使用我们的cap_net_bind_service,所以需要将它设为e; 然后在我们的命令中启动了一个 shell。启动了capabilities二进制文件,我们需要设置为i。 最后,我们希望使用p激活该功能(不是因为我们更改了 UID)。 最终成为cap_net_bind_service+eip。
您可以使用ss进行验证。 我们将剪切输出以使其适合此页面,但它会显示绑定端口和用户ID,而不是 0,在本例中为 65534:
1 | [root@VM-16-14-centos ~]# ss -tulpn -e -H | cut -d' ' -f17- |
我们在本例中使用了capsh,你也可以使用libcap编写包装器;有关详细信息,请参阅man 3 libcap
为了更好地理解我们程序使用的功能,我们可以使用BCC提供的功能工具,该工具在内核函数cap_capable 上设置kprobe:
1 | [root@VM-16-14-centos cpt8]# /usr/share/bcc/tools/capable |
我们可以使用bpftrace和cap_capable内核函数上的单线kprobe来完成相同的操作:
1 | [root@VM-16-14-centos cpt8]# bpftrace -e \ 'kprobe:cap_capable {time("%H:%M:%S "); printf("%-6d %-6d %-16s %-4d %d\n", uid, pid, comm, arg2, arg3); }' | grep -i capabilities |
Capabilities通常用于容器运行时,如runC或Docker,以使容器无特权并仅允许运行大多数应用程序所需的功能。 当应用程序需要特定功能时,在Docker中可以使用--cap-add来完成:
1 | docker run -it --rm --cap-add=NET_ADMIN ubuntu ip link add dummy0 type dummy |
此命令将为该容器提供CAP_NET_ADMIN功能,允许它设置网络链接以添加dummy0接口。
下一节将展示如何实现过滤等功能,但要使用另一种技术,以编程方式实现自己的过滤器。
Seccomp
Seccomp代表安全计算,它是在Linux内核中实现的安全层,允许开发人员过滤特定的系统调用。尽管Seccomp可以与capabilities相媲美,但它控制特定系统调用的能力相比于capabilities更加灵活。
Seccomp和capabilities不相互排斥; 它们经常一起使用 例如,你希望为进程提供CAP_NET_ADMIN功能,但不允许它通过阻止accept和accept4系统调用来接受套接字上的连接。
Seccomp过滤器的方式基于SECCOMP_MODE_FILTER模式的BPF过滤器,并且系统调用过滤的完成方式与对数据包的过滤方式相同。
Seccomp过滤器通过PR_SET_SECCOMP操作使用prctl加载;这些过滤器以BP 程序的形式表示,该程序在使用seccomp_data结构表示的每个Seccomp数据包上执行。该结构包含参考架构、系统调用时的CPU指令指针以及最多六个以uint64表示的系统调用参数。
以下是seccomp_data结构在linux/seccomp.h内核源码中的样子:
1 | struct seccomp_data { |
我们可以基于系统调用、基于其参数或基于它们的组合进行过滤。
在接收到每个Seccomp数据包后,过滤器有责任进行处理以做出最终决定,告诉内核下一步该做什么。最终决定通过它可以给出的返回值(状态代码)之一表示,如下所述:
SECCOMP_RET_KILL_PROCESS:它会在过滤系统调用后立即终止整个进程,因此不会执行
SECCOMP_RET_KILL_THREAD:它会在过滤系统调用后立即终止当前线程,因此不会执行
SECCOMP_RET_KILL:这是SECCOMP_RET_KILL_THREAD的别名,以保持兼容性
SECCOMP_RET_TRAP:系统调用被禁止,SIGSYS信号被发送到调用它的任务
SECCOMP_RET_ERRNO:系统调用未执行,过滤器返回值的SECCOMP_RET_DATA部分作为errno值传递给用户空间。根据错误的原因,返回不同的errno
SECCOMP_RET_TRACE:这用于通知使用PTRACE_O_TRACESECCOMP的ptrace跟踪器在调用系统调用观察和控制系统调用执行时进行拦截。如果没有附加跟踪器,则返回错误,将errno设置为-ENOSYS,并且不执行系统调用
SECCOMP_RET_LOG:系统调用被允许并被记录
SECCOMP_RET_ALLOW:系统调用被允许
1 | ptrace是一个系统调用,用于在进程上实现跟踪机制,称为tracee,其效果是能够观察和控制进程的执行。跟踪器程序可以有效地影响执行并更改被跟踪者的内存寄存器。在Seccomp的上下文中,ptrace在由SECCOMP_RET_TRACE状态码触发时使用;因此,跟踪器可以阻止系统调用执行并实现自己的逻辑。 |
Seccomp错误
有时,在使用Seccomp时会遇到由SECCOMP_RET_ERRNO类型的返回值给出的不同错误。为了通知发生错误,seccomp系统调用将返回-1而不是0。
可能的错误如下:
EACCESS:不允许调用者进行系统调用,这通常是因为它没有CAP_SYS_ADMIN权限或没有使用prctl设置 no_new_privs
EFAULT:传递的参数(seccomp_data结构中的参数)没有有效地址
EINVAL:它可以有四种含义
- 此内核在其当前配置中不知道或不支持请求的操作
- 指定的标志对请求的操作无效
- 操作包括
BPF_ABS,但是指定的偏移量有问题,可能超过seccomp_data结构的大小 - 传递给过滤器的指令数超过了最大指令数
ENOMEM:没有足够的内存来执行程序
EOPNOTSUPP:该操作使用SECCOMP_GET_ACTION_AVAIL指定,但实际上内核不支持参数中的返回操作
ESRCH:同步另一个线程时出现问题
ENOSYS:SECCOMP_RET_TRACE操作没有附着跟踪器
1 | prctl是一个系统调用,它允许用户空间程序控制(设置和获取)进程的特定方面,例如字节序、线程名称、安全计算 (Seccomp) 模式、权限、Perf事件等。 |
Seccomp可能听起来像是一种沙盒机制,但事实并非如此。Seccomp是一个实用程序,可让其用户开发沙盒机制。接下来我们将介绍如何编写程序来使用Seccomp系统调用直接调用的过滤器来编写自定义交互。
Seccomp BPF过滤器示例
在此示例中,我们展示了如何将前面描述的两个操作放在一起:
- 编写Seccomp BPF程序以用作过滤器,基于做出的决定返回不同的代码
- 使用
prctl加载过滤器
首先,该示例需要来自标准库和Linux内核的一些头文件:
1 |
在尝试执行这个例子之前,我们需要确保我们的内核已经将CONFIG_SECCOMP和 CONFIG_SECCOMP_FILTER设置为y。可以通过以下方式进行检查:
1 | cat /proc/config.gz| zcat | grep -i CONFIG_SECCOMP |
其余代码是install_filter函数,由两部分组成。 第一部分包含BPF过滤指令列表:
1 | static int install_filter(int nr, int arch, int error) { |
这些指令是使用linux/filter.h中定义的BPF_STMT和BPF_JUMP宏设置的。
让我们看一下说明:
BPF_STMT(BPF_LD + BPF_W + BPF_ABS (offsetof(struct seccomp_data, arch))):以字BPF_W与BPF_LD 的形式一起加载和累加,并且数据包数据包含在固定的BPF_ABS偏移量中
BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, arch, 0, 3):使用BPF_JEQ检查累加器常量BPF_K中的架构值是否等于arch。 如果是,它将以偏移量0跳转到下一条指令;否则,它将以偏移量3跳转并给出错误
BPF_STMT(BPF_LD + BPF_W + BPF_ABS (offsetof(struct seccomp_data, nr))):以字BPF_W与BPF_LD的形式一起加载并累加,这是包含在固定BPF_ABS偏移处的系统调用数值数据
BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, nr, 0, 1):将系统调用号中的值与nr变量中的值进行比较。如果相等,将转到下一条指令并禁止系统调用;否则将允许带有SECCOMP_RET_ALLOW的系统调用
BPF_STMT(BPF_RET + BPF_K, SECCOMP_RET_ERRNO | (error & SECCOMP_RET_DATA)):这将使用 BPF_RET终止程序并作为结果给出错误SEC COMP_RET_ERRNO,并带有来自err变量的指定错误号
BPF_STMT(BPF_RET + BPF_K, SECCOMP_RET_ALLOW):使用BPF_RET终止程序并允许使用 SECCOMP_RET_ALLOW执行系统调用
1 | 你可能会想为什么要使用指令列表而不是编译后的ELF对象或JIT编译的C程序? |
在socket_filter结构体中定义过滤器代码后,我们需要定义一个sock_fprog包含过滤器代码和过滤器本身的计算长度。需要此数据结构作为声明流程操作的参数:
1 | struct sock_fprog prog = { |
现在我们在install_filter函数中只剩一件事要做:加载程序本身! 为此,我们使用PR_SET_SECCOMP 作为选项使用prctl,因为我们想进入安全计算模式。 然后我们指示模式使用SECCOMP_MODE_FILTER加载过滤器,该过滤器包含在我们的sock_fprog类型的prog变量中:
1 | if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog)) { |
最后,我们可以利用install_filter函数,但是在使用它之前,我们需要使用prctl设置当前执行的 PR_SET_NO_NEW_PRIVS以避免子进程可以拥有比父进程更广泛的权限。这样我们可以在没有root权限的情况下在install_filter函数中进行prctl调用。
现在可以调用install_filter函数。 我们将阻止所有与X86-64体系结构相关的写入系统调用,并且只会授予拒绝所有尝试的权限。过滤器安装后,我们只需使用第一个参数继续执行:
1 | int main(int argc, char const *argv[]) { |
编译程序可以使用clang或gcc;
1 | clang main.c -o filter-write |
我们已经阻止了程序中的所有写入。为了测试它,我们需要一个可以写的程序;ls似乎是一个不错的选择,下面是它的正常运行方式:
1 | [root@VM-16-14-centos seccomp]# ls -la |
接着我们只需将要测试的程序作为第一个参数传递:
1 | [root@VM-16-14-centos seccomp]# ./filter-write "ls -la" |
执行后输出为空,我们可以使用strace来查看发生了什么:
1 | [root@VM-16-14-centos seccomp]# strace -f ./filter-write "ls -la" |
以下输出结果去掉了很多无用的输出,相关部分显示写入被EPERM错误阻止,这与我们设置的相同。 这意味着程序是执行成功的,因为它现在无法访问该系统调用:
1 | [pid 390331] write(2, "ls: ", 4) = -1 EPERM (Operation not permitted) |
现在你已经了解了Seccomp BPF的运作方式以及您可以用它做什么。 但是,如果有一种方法可以使用eBPF而不是cBPF实现同样的效果,那不是很好吗?
在考虑eBPF程序时,大多数人认为只是编写它们并以root权限加载它们。 尽管这句话通常是正确的,但内核实现了一套机制来保护各个级别的eBPF对象。 这些机制称为BPF LSM钩子。
BPF LSM钩子
为了提供对系统事件的独立于体系结构的控制,LSM实现了钩子的概念。从技术上讲,钩子调用类似于系统调用。然而,独立于系统并与LSM框架集成使得钩子变得有趣,因为它提供的抽象层很方便,并且可以避免在不同架构上使用系统调用时可能发生的麻烦。
在撰写本文时,内核有七个与BPF程序相关的钩子,而SELinux是唯一实现它们的in-tree LSM。你可以在此文件的内核源码中看到这一点:include/linux/security.h:
1 | extern int security_bpf(int cmd, union bpf_attr *attr, unsigned int size); |
每一个钩子都将在执行的不同阶段被调用:
1 | security_bpf:对已执行的BPF系统调用进行初始检查 |
结论
安全性不是一种以通用方式为你想要保护的所有内容实施的东西。能够以不同的方式在不同的层次上保护系统是很重要的,保护系统的最好方法是以不同的视角堆叠不同的层,这样一个受损的层就不会有能力访问整个系统。内核开发人员为我们提供了一组不同的层和交互点,我们希望能让你很好地理解层是什么以及如何使用BPF程序与它们进行交互。
第九章节
Sysdig eBPF God Mode
制作同名开源Linux故障排除工具的公司Sysdig于2017年开始在内核4.11下使用eBPF。
过去该公司一直使用内核模块来提取和完成所有内核端工作,但随着用户群的增加以及越来越多的公司开始试验,该公司承认在许多方面对大多数外部行为是一种限制:
- 越来越多的用户无法在他们的机器上加载内核模块。 云原生平台对运行时程序的功能越来越严格
- 新贡献者(甚至老贡献者)不了解内核模块的体系结构。这减少了贡献者的总数,并成为了项目本身发展的一个限制因素
- 内核模块的维护很困难,不仅仅是因为编写代码,还需要努力保持它的安全和组织良好
出于这些动机,Sysdig决定尝试编写与模块中相同的一组功能,但改用eBPF程序的方法。 采用eBPF自动带来的另一个好处是Sysdig可以进一步利用其他不错的eBPF跟踪功能。 例如,使用用户探针将eBPF程序附加到用户空间应用程序中的特定执行点相对容易。
此外,该项目现在可以在eBPF程序中使用原生辅助函数功能来捕获正在运行的进程的堆栈跟踪,以增强典型的系统调用事件流。为用户提供了更多故障排除信息。
由于eBPF虚拟机的限制,Sysdig在开始最初面临一些挑战,因此该项目的首席架构师Gianluca Borello决定通过为内核本身提供上游补丁来改进它,包括:
后者对于处理系统调用参数尤其重要,这或许是该工具中可用的最重要的数据源。
如下所示是Sysdig中的eBPF架构图
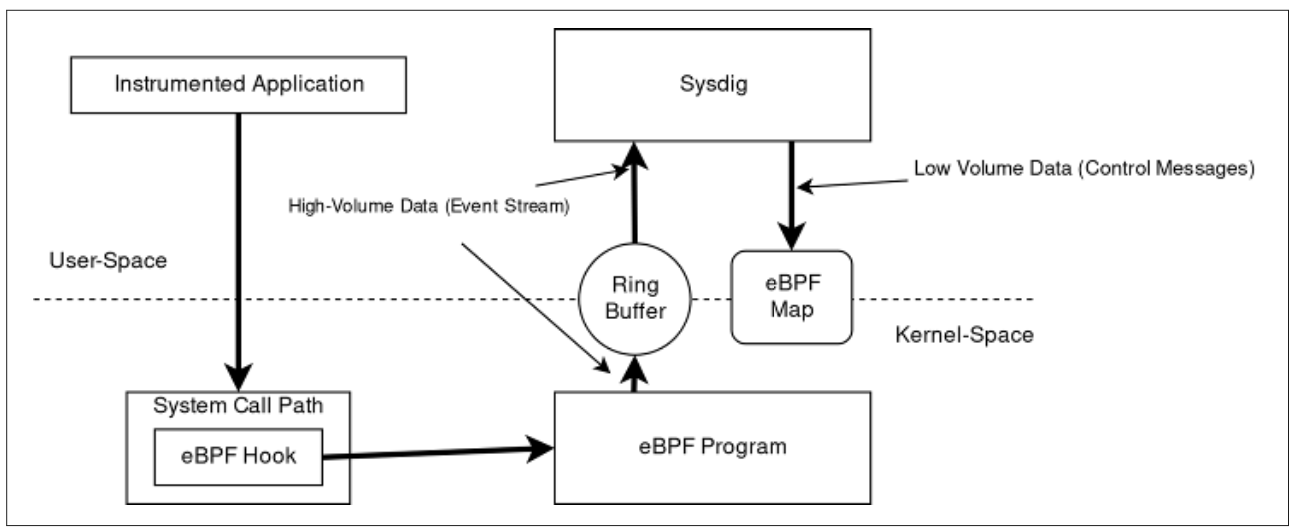
实现的核心是负责检测的自定义eBPF程序的集合。 这些程序是用C语言的一个子集编写的。 们是使用最新版本的Clang和LLVM编译的,它们将高级C代码转换为eBPF字节码。
Sysdig检测内核的每个不同执行点都有一个eBPF程序。目前,eBPF程序附加到以下静态跟踪点:
- System call entry path
- System call exit path
- Process context switch
- Process termination
- Minor and major page faults
- Process signal delivery
每个程序接收执行点数据(例如,对于系统调用,调用进程传递的参数)并开始处理它们。 处理取决于系统调用的类型。 对于简单的系统调用,参数只是逐字复制到eBPF映射中,用于临时存储,直到形成整个事件框架。对于其他复杂的调用,eBPF程序包括翻译或扩充参数的逻辑。这使用户空间中的Sysdig应用程序能够充分利用数据。
一些附加数据包括以下内容:
- 与网络连接相关的数据(TCP/UDP IPv4/IPv6 元组、UNIX套接字名称等)
- 与进程相关的指标(内存计数器、页面错误、套接字队列长度等)
- 容器特定数据,例如发出系统调用的进程所属的
cgroup,以及进程所在的命名空间
在上面Sysdig的eBPF架构图中,eBPF程序为特定系统调用捕获所有需要的数据后,使用一个特殊的本地BPF函数将数据推送到一组CPU的环形缓冲区,用户空间应用程序可以以非常高的吞吐量读取。 这不同于使用eBPF映射与用户空间共享内核空间中生成的“小数据”的典型范例。
Flowmill
Flowmill是一家可观测性初创公司,其创始人乔纳森·佩里(Jonathan Perry)从一个名为Flowtune的学术研究项目中脱颖而出。Flowtune研究了如何在拥塞的数据中心网络中有效地调度单个数据包。这项工作所需的核心技术之一是以极低的开销收集网络遥测数据的方法。Flowmill最终采用了这项技术来观察、聚合和分析分布式应用程序中每个组件之间的连接,以执行以下操作:
- 提供服务如何在分布式系统中交互的准确视图
- 统计流量速率、错误或延迟显着变化的区域
Flowmill使用eBPF内核探针来跟踪每个打开的套接字并定期捕获它们的操作系统指标。这很复杂,原因有很多:
- 在建立 eBPF 探针时,有必要检测新连接和已经打开的现有连接。 此外,它必须考虑到TCP和UDP以及通过内核的IPv4和IPv6代码路径。
- 对于基于容器的系统,每个套接字都必须归属于相应的
cgroup,并与来自Kubernetes或Docker等平台的编排器元数据相结合。 - 必须对通过
conntrack执行的网络地址转换进行检测,以建立套接字与其外部可见IP地址之间的映射。 例如,在Docker中,常见的网络模型使用源NAT来伪装主机IP地址和Kubernetes后面的容器,并使用服务虚拟IP地址来表示一组容器。 - eBPF程序收集的数据必须经过后处理,以按服务提供聚合并匹配在连接两侧收集的数据。
然而,添加eBPF内核探针提供了一种更有效和更强大的方式来收集这些数据。它消除了丢失连接的风险,并且可以在秒级间隔内以低开销在每个套接字上完成。Flowmill的方法依赖一个代理,该代理结合了一组eBPF kprobes和用户空间指标收集以及机外聚合和后处理。该实现大量使用Perf环将在每个套接字上收集的指标传递到用户空间以做进一步处理。此外,它使用哈希映射来跟踪打开的TCP和UDP套接字。
例如,tcp_v4_do_rcv捕获所有已建立的TCP RX流量并可以访问struct sock,但调用量非常大。相反,用户可以检测处理ACK、乱序数据包处理、RTT预测等功能,从而允许处理影响已知指标的特定事件。
使用这种跨TCP、UDP、进程、容器、conntrack和其他子系统的方法可以实现非常好的系统性能,并且开销足够低,这在大多数系统中是难以测量的。CPU开销通常为每个内核0.1%到0.25%,包括eBPF和用户空间组件,主要取决于创建新套接字的速率。
Sysdig和Flowmill是使用BPF构建监控和可观察性工具的先驱,但他们并不是唯一的。 在整本书中,我们提到了其他公司,如Cillium和Facebook,它们采用BPF作为框架来提供高度安全和高性能的网络基础设施。 对于BPF的未来我们是充满期待的!