前言
什么是DPDK?对于用户,是性能出色的报数据处理加速软件库;对于开发者,是一个实践包处理新想法的创新工场;对于性能调优者,是一个绝佳的成果分享平台。DPDK对于当下火热的网络功能虚拟化而言是一个重要基石。
DPDK最初的动机很简单,就是证明IA多核处理器能够支撑高性能数据包处理。随着早期目标的达成和更多通用处理器体系的加入,DPDK逐渐成为通用多核处理器高性能数据包处理的业界标杆。
主流包处理硬件平台
支持包处理的主流硬件平台大致分为三个方向。
- 硬件加速器:对于本身模块化的固化功能具有高性能低成本的特点
- 网络处理器:提供了包处理逻辑软件可编程的能力
- 多核处理器:在更为复杂多变的高层包处理上有优势
硬件加速器
硬件加速器被广泛用于包处理领域,ASIC和FPGA是其最广为采用的器件。
ASIC:一种应特定用户要求和特定电子系统的需要而设计、制造的集成电路。ASIC的优点是面向特定用户的需求,在批量生产时与通用集成电路相比体积更小、功耗更低、可靠性更高、性能提高、保密性增强、成本降低等。但ASIC的缺点也很明显,它的灵活性和扩展性不够、开发费用高、开发周期长。
FPGA:现场可编程门阵列。作为ASIC领域中的一种半定制电路而出现,与ASIC的区别是用户不需要介入芯片的布局布线和工艺问题,而且可以随时改变其逻辑功能,使用灵活。FPGA以并行运算为主,开发相对于传统PC、单片机开发有很大不同。以硬件描述语言(Verilog或VHDL)来实现。
全可编程FPGA概念的提出,使FPGA朝着进一步软化的方向持续发展,其并行化整数运算的能力将进一步在通用计算定制化领域得到挖掘,近年来在数据中心中起的了很大进步,例如应用于机器学习场合。
网络处理器
网络处理器是专门为处理数据包而设计的可编程通用处理器,采用多内核并行处理结构,其常被应用于通信领域的各种任务,比如包处理、协议分析、路由查找、声音/数据的汇聚、防火墙、QoS等。其通用性表现在执行逻辑由运行时加载的软件决定,用户使用专用指令集即微码(microcode)进行开发。其硬件体系结构大多采用高速的接口技术和总线规范,具有较高的I/O能力,使得包处理能力得到很大提升。
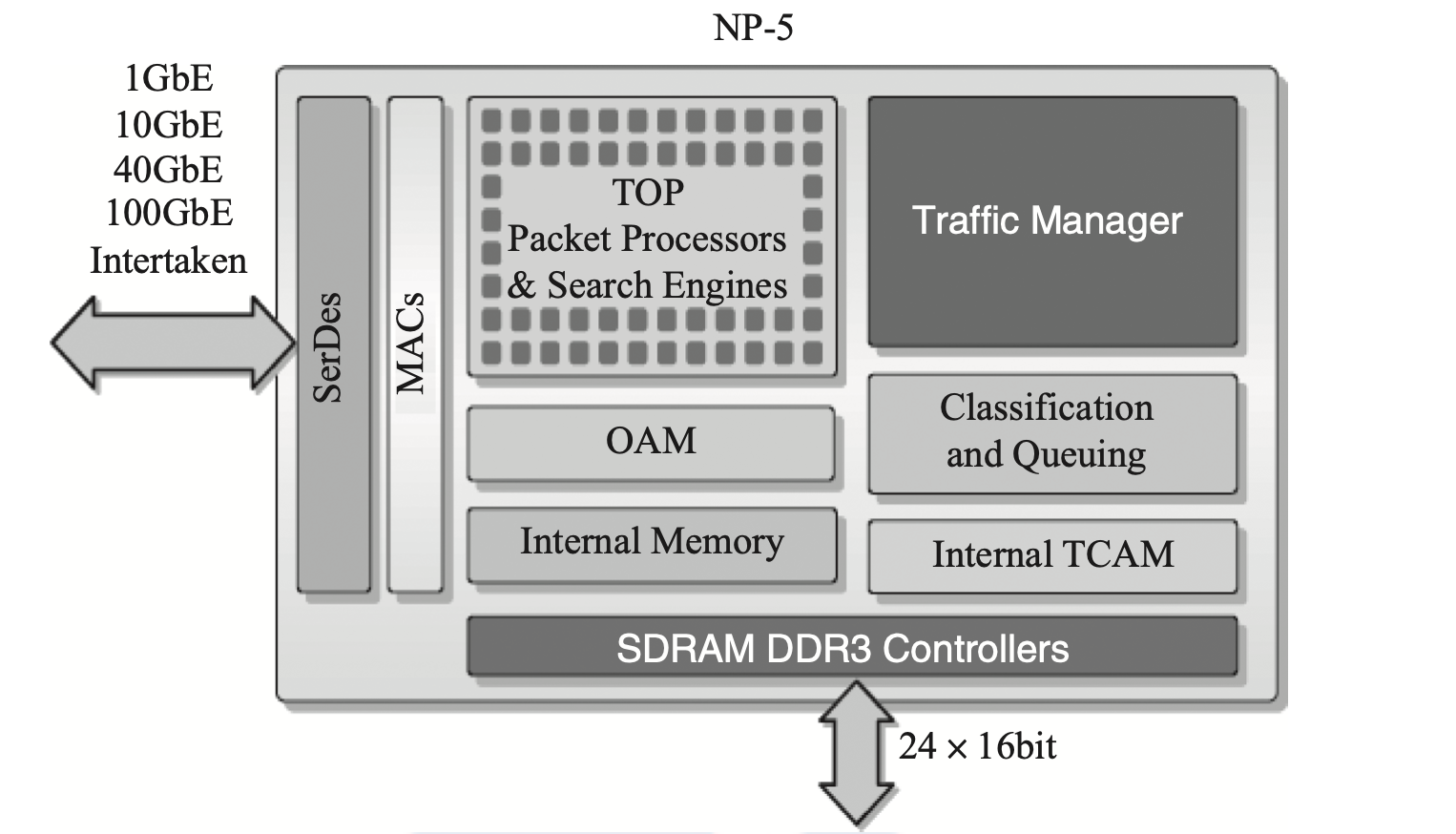
如下图是NP-5处理器架构框图,其中TOP部分是可编程部分,根据需要通过编写微码实现业务相关的包处理逻辑。NPU拥有高性能和高可编程性等优点。但其成本和特定领域的特性限制了它的市场规模。而不同厂商不同架构的NPU遵循的微码规范不尽相同,开发人员的成长以及生态系统的构建都比较困难。虽然一些NPU的微码也开始支持由高级语言(例如C)编译生成,但由于结构化语言本身原语并未面向包处理,使得转换后的效率并不理想。
多核处理器
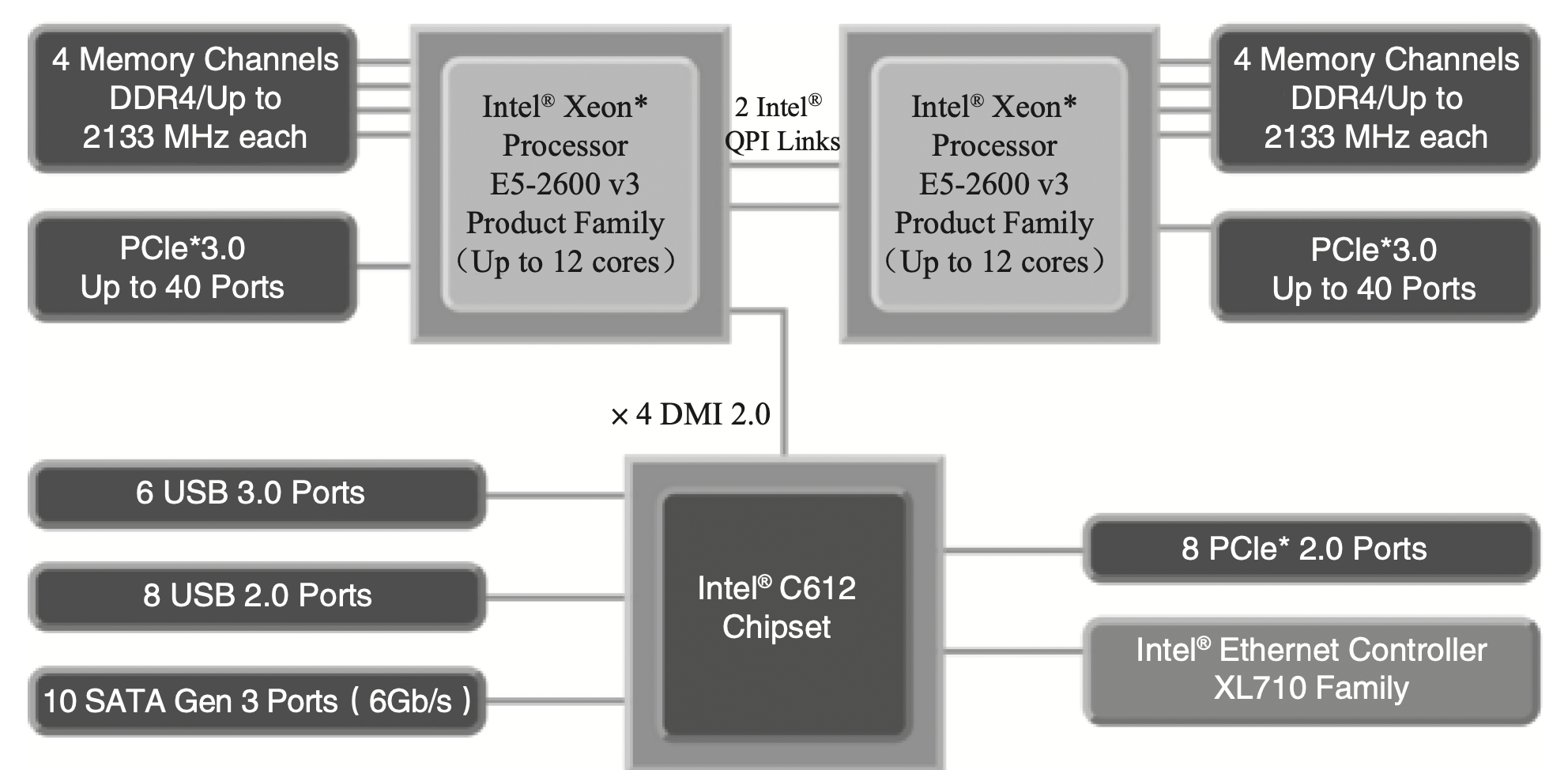
现代CPU性能的扩展主要通过多核的方式进行演进。这样利用通用处理器同样可以在一定程度上并行地处理网络负载。下图是Intel双路服务器平台框图,描述了一个典型的双路服务器平台的多个模块,CPU、芯片组C612、内存和以太网控制器XL710构成了主要的数据处理通道。基于PCIe总线的I/O接口提供了大量的系统接口,为服务器平台引入了差异化的设计。
当前的多核处理器也正在走向SoC化,针对网络的SoC往往集成内存控制器、网络控制器,甚至是一些硬件加速处理引擎。以下是一些主流厂商的多核处理器的SoC平台
- IA multi-core Xeon
- Tilear-TILE-Gx
- Cavium Network-OCTEON & OCTEON II
- Freescale-QorIQ
- NetLogic Microsystem-XLP
初识DPDK
以Linux为例,传统网络设备驱动包处理的动作可以概括如下:
- 数据包到达网卡设备
- 网卡设备依据配置进行DMA操作
- 网卡发送中断,唤醒处理器
- 驱动软件填充读写缓冲区数据结构
- 数据报文到达内核协议栈,进行高层处理
- 如果最终应用在用户态,数据从内核搬移到用户态
- 如果最终应用在内核态,在内核继续进行
随着网络接口带宽从千兆向万兆迈进,原先每个报文就会触发一个中断,中断带来的开销变得突出。大量数据到来会触发频繁的中断开销,导致系统无法承受,因此有人在Linux内核中引入了NAPI机制,其策略是系统被中断唤醒后,尽量使用轮询的方式一次处理多个数据包,直到网络再次空闲重新转入中断等待。
一个二层以太网包经过网络设备驱动的处理后,最终大多要交给用户态的应用。网络包进入计算机大多需要经过协议处理,在Linux系统中TCP/IP由Linux内核处理。即使在不需要协议处理的场景下,大多数场景也需要把包从内核的缓冲区复制到用户缓冲区,系统调用以及数据包复制的开销,会直接影响用户态应用从设备直接获得包的能力,而对于多样的网络功能节点来说,TCP/IP协议栈并不是数据转发节点所必需的。
如果再往使实时性方面考虑,传统上,事件从中断发生到应用感知,也是要经过长长的软件处理路径,所以在2010年前采用IA(Intel Architecture)处理器的用户会得出一个结论,就是IA不适合做包处理。
DPDK最佳实践
现在,DPDK的出现很好的解答了IA多核处理器是否可以应对高性能数据包处理这一问题。
DPDK技术大致归纳如下:
- 轮询:避免中断上下文切换的开销。
- 用户态驱动:既规避了不必要的内存拷贝又避免了系统调用。
- 亲和性与独占:DPDK虽然工作在用户态,但是线程的调度仍然依赖内核。利用线程的CPU亲和绑定的方式,特定任务可以被指定在某个核上工作。好处是可避免线程在不同核间频繁切换,核间线程切换容易导致因
cache miss和cache write back造成的大量性能损失。 - 降低访存开销:利用内存大页能有效降低
TLB miss,利用内存多通道的交错访问有效提高内存访问的有效带宽,利用对于内存非对称性的感知避免额外的访存延迟。 - 软件调优:结构的
cache line对齐、数据在多核间访问避免跨cache line共享、适时地预取数据、多元数据批量操作等 - 利用IA新硬件技术:拿
Intel DDIO技术来讲,这个cache子系统对DMA访存的硬件创新直接助推了性能跨越式的增长。有效利用SIMD(Single Instruction Multiple Data)并结合超标量技术(Superscalar)对数据层面或者对指令层面进行深度并行化,在性能的进一步提升上也行之有效。另外一些指令(比如cmpxchg),本身就是lockless数据结构的基石,而crc32指令对于4 Byte Key的哈希计算也是改善明显。 - 充分挖掘网卡的潜能:经过
DPDK I/O加速的数据包通过PCIe网卡进入系统内存,PCIe外设到系统内存之间的带宽利用效率、数据传送方式(coalesce操作)等都是直接影响I/O性能的因素。在现代网卡中,往往还支持一些分流(如RSS,FDIR等)和卸载(如Chksum, TSO等)功能。DPDK充分利用这些硬件加速特性,帮助应用更好地获得直接的性能提升。
DPDK框架简介
DPDK为IA上的高速包处理而设计。大量利用了有助于包处理的软硬件特性,如大页、缓存行对齐、线程绑定、预取、NUMA、IA最新指令的利用、Intel DDIO、内存交叉访问等。
核心库 Core Libs,提供系统抽象、大页内存、缓存池、定时器及无锁环等基础组件。
PMD 库,提供全用户态的驱动,以便通过轮询和线程绑定得到极高的网络吞吐,支持 各种本地和虚拟的网卡。
Classify 库,支持精确匹配(Exact Match)、最长匹配(LPM)和通配符匹配(ACL),提 供常用包处理的查表操作。
QoS 库,提供网络服务质量相关组件,如限速(Meter)和调度(Sched)。
下图为DPDK主要模块分解
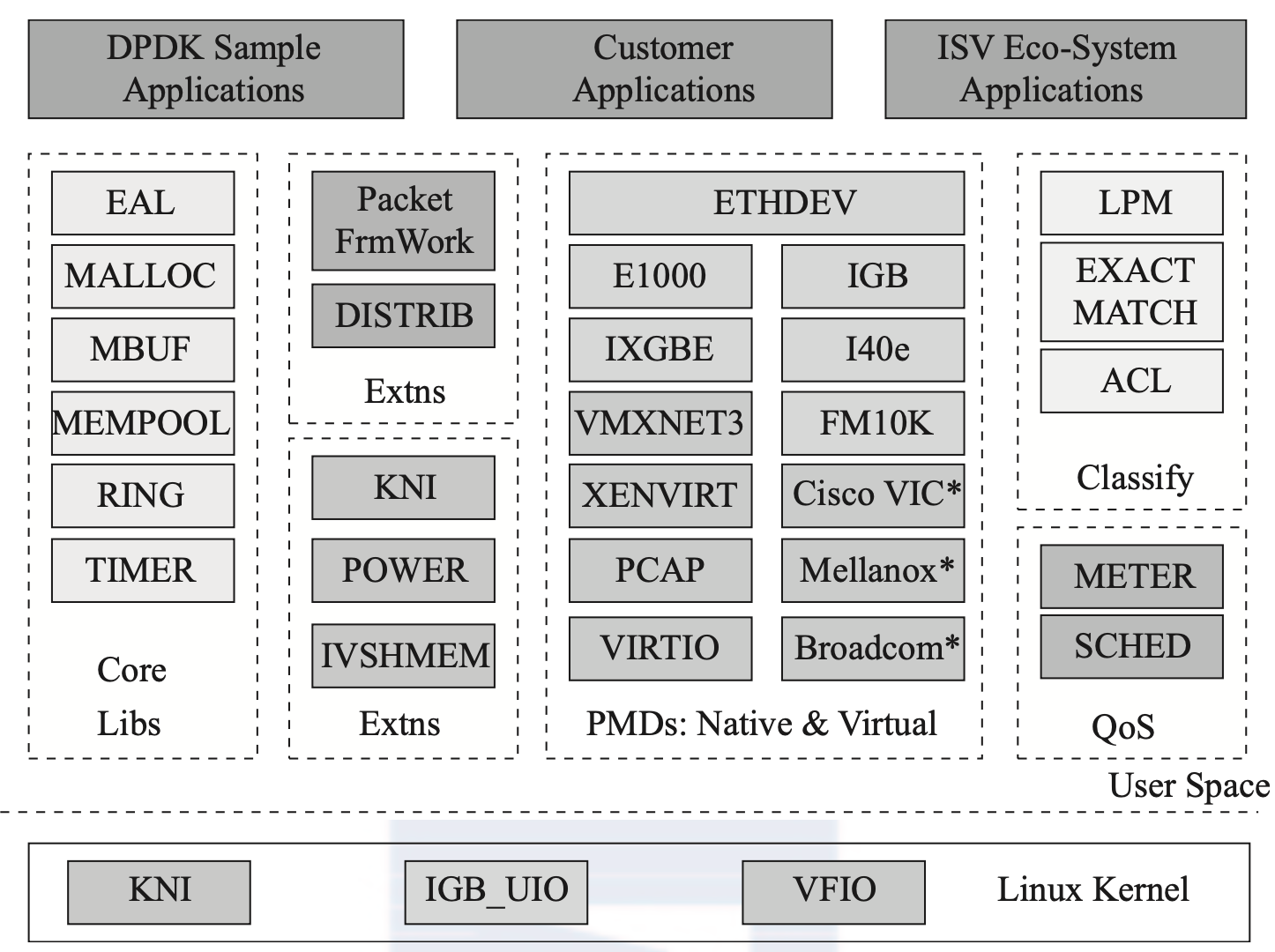
除了这些组件,DPDK还提供了几个平台特性,比如节能考虑的运行时频率调整(POWER)、与Linux Kernel stack建立快速通道的KNI(Kernel Network Interface)。而Packet Framework和DISTRIB为搭建更复杂的多核流水线处理模型提供了基础的组件。
解读数据包处理能力
以以太网为例,一般所说的接口带宽,1Gbit/s、10Gbit/s、25Gbit/s、40Gbit/s、 100Gbit/s,代表以太接口线路上所能承载的最高传输比特率,其单位是 bit/s(bit per second, 位 / 秒)。实际上,不可能每个比特都传输有效数据。以太网每个帧之间会有帧间距(InterPacket Gap,IPG),默认帧间距大小为12字节。每个帧还有7个字节的前导(Preamble),和1个字节的帧首定界符(Start Frame Delimiter,SFD)。具体帧格式如下图所示,有效内容主要是以太网的目的地址、源地址、以太网类型、负载。报文尾部是校验码。

通常意义上的满速带宽能跑有效数据的吞吐可以由如下公式得到理论帧转发率:
帧转发率 = BitRate/8 / IPG+Preamble+SFD+PKtSize
而这个最大理论帧转发率的倒数表示了线速情况下先后两个包到达的时间间隔
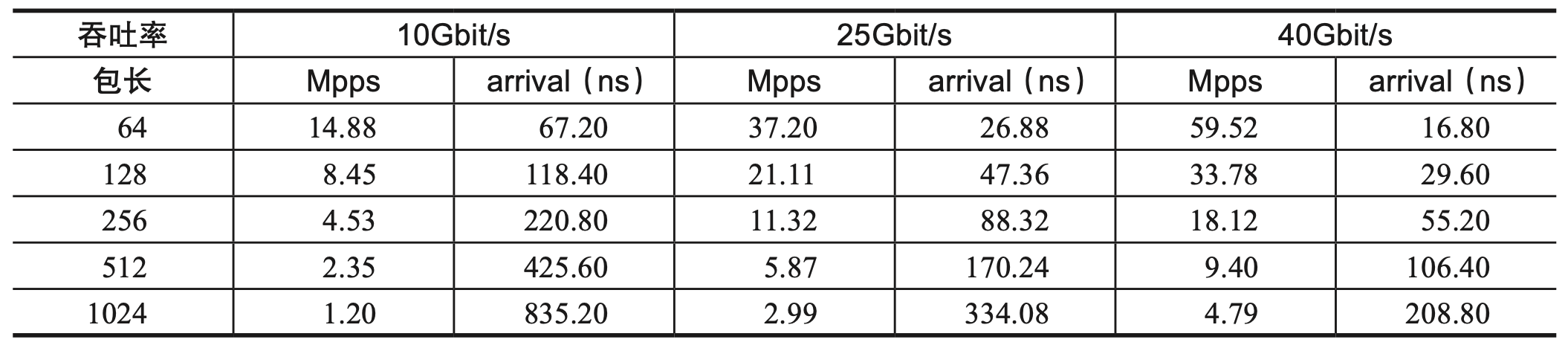
按照这个公式,将不同包长按照特定的速率计算可得到一个以太帧转发率,如下图所示,可以发现在相同带宽速率下,包长越小的包,转发率越高,帧间延迟也越小。
软件包处理的潜力
DPDK加速网络节点
DPDK软件包内有一个最基本的三层转发实例(l3fwd),可用于测试双路服务器整个系统的吞吐能力,实验表明可以达到 220Gbit/s 的数据报文吞吐能力。值得注意的是,除了通过 硬件或者软件提升性能之外,如今 DPDK 整系统报文吞吐能力上限已经不再受限于 CPU 的 核数,当前瓶颈在于 PCIe(IO 总线)的 LANE 数。换句话说,系统性能的整体 I/O 天花板不 再是 CPU,而是系统所提供的所有 PCIe LANE 的带宽,能插入多少个高速以太网接口卡。
在这样的性能基础上,网络节点的软化就成为可能。对于网络节点上运转的不同形态的网络功能,一旦软化并适配到一个通用的硬件平台,随之一个自然的诉求可能就是软硬件解耦。解耦正是网络功能虚拟化(NFV)的一个核心思想,而硬件解耦的多个网络功能在单一通用节点上的隔离共生问题,是另一个核心思想虚拟化诠释的。当然这个虚拟化是广义的, 在不同层面可以有不同的支撑技术。
NFV有很多诉求,业务面高性能,控制面高可用、高可靠、易运维、易管理等。但没有业务面的高性能,后续的便无从谈起。DPDK始终为高性能业务面提供坚实的支撑,除此以外,DPDK立足IA的CPU 虚拟化技术和IO的虚拟化技术,对各种通道做持续优化改进的同时,也对虚拟交换(vswitch)的转发面进化做出积极贡献。应对绝对高吞吐能力的要求,DPDK支持各种I/O的SR-IOV接口;应对高性能虚拟主机网络的要求,DPDK支持标准virtio接口;对虚拟化平台的支撑,DPDK从KVM、VMWARE、XEN的hypervisor到容器技术,可谓全平台覆盖。
DPDK加速计算节点
C10K是IT界的一个著名命题,甚至后续衍生出了关于C1M和C10M的讨论。其阐述 的一个核心问题就是,随着互联网发展,随着数据中心接口带宽不断提升,计算节点上各种互联网服务对于高并发下的高吞吐有着越来越高的要求。
但是单一接口带宽的提高并不能直接导致高并发、高吞吐服务的发生,即使用到了一系列系统方法(异步非阻塞,线程等),但网络服务受限于内核协议栈多核水平扩展上的不足以及建立拆除连接的高开销,开始逐渐阻碍进一步高并发下高带宽的要求。另一方面,内核协议栈需要考虑更广泛的支持,并不能为特定的应用做特殊优化,一般只能使用系统参数进行调优。 当然,内核协议栈也在不断改进,而以应用为中心的趋势也会不断推动用户态协议栈的涌现。有基于BSD协议栈移植的,有基于多核模型重写的原型设计,也有将整个Linux内核包装成库的。它们大多支持以DPDK作为I/O引擎,有些也将DPDK的一些优化想法加入到协议栈的优化中,取得了比较好的效果。
DPDK加速存储节点
Intel最近开源了SPDK(Storage Performance Development Kit),一款存储加速开发套件,其主要的应用场景是iSCSI性能加速。目前iSCSI系统包括前端和后端两个部分,在前端,DPDK提供网络I/O加速,加上一套用户态TCP/IP协议栈(目前还不包含在开源包中),以流水线的工作方式支撑起基于iSCSI的应用;在后端,将DPDK用户态轮询驱动的方式实践在NVMe上,PMD的NVMe驱动加速了后端存储访问。这样一个端到端的整体方案,用数据证明了卓有成效的IOPS性能提升。
DPDK方法论
- 专用负载下的针对性软件优化
- 追求可水平扩展的性能
- 向Cache索求极致的实现优化性能
DPDK安装
Todo
DPDK实例
在对DPDK的原理和代码展开进一步解析之前,先看一些小而简单的例子,建立一个形象上的认知。
- helloworld:启动基础运行环境,DPDK构建了一个基于操作系统的,但适合包处理的软件运行环境,你可以认为这是个mini-OS
- skeleton:最精简的单核报文收发骨架
- l3fwd:三层转发是DPDK用于发布性能测试指标的主要应用
Helloworld
DPDK里的helloworld是最基础的入门程序。它建立了一个多核运行的基础环境,每个线程会打印hello from core #,其中core #是由操作系统管理的。
代码如下
1 | /* SPDX-License-Identifier: BSD-3-Clause |
从代码角度,rte是指runtime environment,eal是指environment abstraction layer。DPDK的主要对外函数接口都是以rte_作为前缀,抽象化函数接口可以帮助DPDK运行在多个操作系统上。
初始化基础运行环境
主线程运行入口是main函数,调用了rte_eal_init入口函数,启动基础运行环境。
1 | int rte_eal_init(int argc,char **argv) |
入口参数是启动DPDK的命令行,可以是长长的一串很复杂的设置。对于Helloworld这个实例,最需要的参数是”-c rte_eal_init本身完成的工作很复杂,它读取入口参数,解析并保存作为DPDK运行的系统信息,依赖这些信息,构建一个针对包处理设计的运行环境,主要动作分解如下:
- 配置初始化
- 内存初始化
- 内存池初始化
- 队列初始化
- 告警初始化
- 中断初始化
- PCI初始化
- 定时器初始化
- 检测内存本地化(NUMA)
- 插件初始化
- 主线程初始化
- 轮询设备初始化
- 建立主从线程通道
- 将从线程设置在等待模式
- PCI设备的探测与初始化
多核运行初始化
DPDK面向多核设计,程序会试图独占运行在逻辑核(lcore)上。main函数里重要的是启动多核运行环境。RTE_LCORE_FOREACH_WORKER(lcore_id),遍历所有EAL指定可以使用的lcore,然后通过rte_eal_remote_launch在每个lcore上,启动被指定的线程。
1 | int rte_eal_remote_launch(int (*f)(void *),void *arg,unsigned slave_id); |
第一个参数是从线程,是被征召的线程
第二个参数是传给从线程的参数
第三个参数是指定的逻辑核,从线程会执行在这个core上
rte_eal_remote_launch(lcore_hello, NULL, lcore_id);
其中,参数lcore_id指定了从线程ID,运行入口函数lcore_hello,运行函数lcore_hello,它读取自己的逻辑核编号(lcore_id),打印出”hello from core #”
Skeleton
skeleton的设计初衷是实现一个最简单的报文收发示例,对收入报文不做任何处理直接发送。可以用于平台的单核报文出入性能测试。
主要处理函数main处理逻辑如下
1 | /* |
首先调用rte_eal_init初始化运行环境。检查网络接口数,据此分配内存池rte_pktmbuf_pool_create,入口参数是指定rte_socket_id(),考虑了本地内存使用的范例,调用port_init(portid, mbuf_pool)初始化网口的配置,最后调用lcore_main()进行主处理流程。
网口初始化流程
1 | port_init(uint8_t port,struct rte_mempool *mbuf_pool) |
首先对指定端口设置队列数,本例指定为单队列。在收发两个方向上,基于端口与队列进行配置设置,缓冲区进行关联设置。
网口设置:对指定端口设置接收、发送方向的队列数目。依据配置信息来指定端口功能。
1 | int rte_eth_dev_configure(uint8_t port_id,uint16_t nb_rx_q,uint16_t nb_tx_q,const struct rte_eth_conf *dev_conf) |
队列初始化:对指定端口的某个队列,指定内存、描述符数量、报文缓冲区、并且对队列进行配置
1 | int rte_eth_rx_queue_setup(uint8_t port_id, uint16_t rx_queue_id, |
网口设置:初始化配置结束后,启动端口int rte_eth_dev_start(uint8_t port_id);完成后,读取 MAC 地址,打开网卡的混杂模式设置,允许所有报文进入。
port_init处理逻辑如下
1 | /* Main functional part of port initialization. 8< */ |
网口收发报文循环收发在lcore_main中实现,为保证性能,首先检测CPU与网卡的Socket是否最优适配。数据收发循环非常简单,为高速报文进出定义了burst的收发函数如下,四个参数意义非常直观:端口、队列、报文缓冲区以及收发包数。
基于端口队列的报文收发函数如下:
1 | static inline uint16_t rte_eth_rx_burst(uint8_t port_id, uint16_t queue_id, |
这就构成了最基本的DPDK报文收发展示。可以看到,此处不涉及任何具体网卡形态,软件接口对硬件没有依赖。
lcore_main处理逻辑如下:
1 | /* Basic forwarding application lcore. 8< */ |
L3fwd
L3fwd是发布DPDK性能测试的例子。如果将PCIE插槽上填满高速网卡,将网口与大流量测试仪表连接,他能展示在双路服务器平台具备200Gbit/s的转发能力。数据包被收入系统后,会查询IP报文头部,依据目标地址进行路由查找,发现目的端口,修改IP头部后,将报文从目的端口送出。路由查找有两种方式,一种是基于目标IP地址的完全匹配(exact match),另一种是基于路由表的最长掩码匹配(Longest Prefix Match,LPM)。
启动这个例子,指定命令参数格式如下:
1 | ./build/l3fwd [EAL options] -- -p PORTMASK [-P] --config(port,queue,lcore) [,(port,queue,lcore)] |
命令参数分为两个部分,以”—“为分界线,分界线右边的参数是三层转发的私有命令选项。左边是DPDK的EAL Options
- [EAL Options]是DPDK运行环境的输入配置选项,输入命令会交给
rte_eal_init处理 - PORTMASK依据掩码选择端口,DPDK启动时会搜索系统认识的PCIe设备,依据黑白名单原则来决定是否接管,早期版本可能会接管所有端口,断开网络连接。现在可通过脚本绑定。
- config选项指定(port,queue,lcore),用指定线程处理对应的端口的队列。要实现
200Gbit/s的转发,需要大量线程(核)参与,并行转发。
主线程main的处理流程如下所述:
- 初始化运行环境:
rte_eal_init(argc,argv) - 分析入参:
parse_args(argc,argv) - 初始化lcore与port配置
- 端口与队列初始化
- 端口启动,使能混杂模式
- 启动从线程,令其运行
main_loop()
从线程执行main_loop()的处理流程如下所述:
- 读取自己的lcore信息完成配置
- 读取关联的接收与发送队列信息
- 进行循环处理:
- 向指定队列批量发送报文
- 从指定队列批量接收报文
- 批量转发接收到的报文
批量转发接收到的报文是处理的主体,提供了基于Hash的完全匹配转发,也可以基于LPM进行转发。转发路由查找方式可以由编译配置选择。
下面的例子包括基于multi buffer原理的代码实现,在#if(ENABLE_MULTI_BUFFER_OPTIMIZE == 1)的路径下,一次处理8个报文。它的实现有效利用了处理器内部的乱序执行和并行处理能力,能显著提高转发性能。
1 | for (j = 0; j < n; j += 8) { |
依据IP头部的五元组信息,利用rte_hash_lookup来查询目标端口
1 | mask0 = _mm_set_epi32(ALL_32_BITS, ALL_32_BITS, ALL_32_BITS, BIT_8_TO_15); |
这段代码在读取报文头部信息时,将整个头部导入了基于SSE的矢量寄存器(128位宽),并对内部进行了掩码mask0运算,得到key,然后把key作为入口参数送入rte_hash_lookup运算。
小结
DPDK立足通用多核处理器,经过软件优化的不断摸索,实践出一套行之有效的方法,在IA数据包处理上取得重大性能突破。随着软硬件解耦的趋势,DPDK已经成为NFV事实上的数据面基石。着眼未来,无论是网络节点,还是计算节点或是存储节点,这些云服务的基础设施都有机会因DPDK而得到加速。